JVM面试必问:G1垃圾回收器
摘要:G1垃圾回收器是一款主要面向服务端应用的垃圾收集器。
本文分享自华为云社区《JVM面试高频考点:由浅入深带你了解G1垃圾回收器!!!》,原文作者:Code皮皮虾 。
G1垃圾回收器介绍
G1垃圾回收器是一款主要面向服务端应用的垃圾收集器。作为垃圾回收器技术发展史上里程碑的成果,G1垃圾回收器不同于以往的垃圾回收器,首先是思想上的转变,如下图:
G1对于Java堆的划分
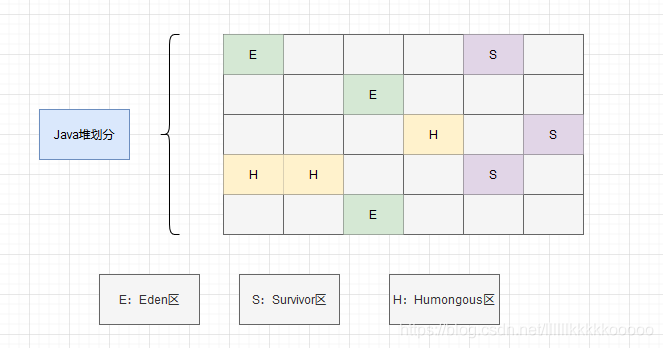
上面的图,小伙伴们第一次看可能不咋明白,因为各位还不了解G1,看看下面的话,应该就差不多了。
G1垃圾回收器对于Java堆区域的划分不同于以往我们对Java对区域划分的认知
以往对于Java堆区域的划分为:新生代和老年代,新生代又划分为 Eden区和 Survivor区,Survivor区又分为 from区和 to区。
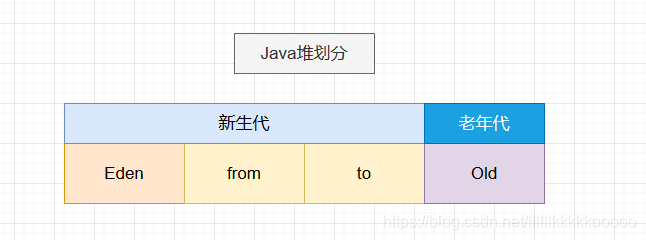
但是现在,G1不再坚持固定大小以及固定数量的分代区域划分,而是把连续的Java堆空间划分为多个大小相等的独立区域(Region),每个Region都可以成为 Eden空间、Survivor空间、老年代空间。
这种思想上的转变和设计,使得G1可以面向堆内存任何部分来组成回收集来进行回收,衡量标准不再是它属于哪个分代,而是哪块内存存放的垃圾最多,回收收益最大,这就是G1收集器的 Mixed GC模式,即混合GC模式。
Region还有一类特殊的 Humongous 区域,专门用来存储大对象。G1认为只要大小超过了一个Region容量一半的对象即可判定为大对象。如果是那些超过了整个Region容量的超大对象,将会放在连续 N 个 Humongous Region区域。
Region的取值范围为 1M ~ 32M
Region的默认个数为 2048个
-XX:G1HeapRegionSize = N
G1这么做看起来是由一种焕然一新的感觉,但细心的小伙伴可能已经发现,如果 Region之间存在跨区引用对象,那这些对象如何解决?
- 不管是G1还是其他分代收集器,JVM都是使用 记忆集(Remembered Set) 来避免全局扫描。
- 每个Region都有一个对应的记忆集。
- 每次Reference类型数据写操作时,都会产生一个 写屏障(Write Barrier)暂时去终止操作
- 然后检查将要写入的引用 指向的对象是否和该Reference类型数据在不同的 Region(其他收集器:检查老年代对象是否引用了新生代对象)
- 如果不同,通过 卡表(Card Table)把相关引用信息记录到引用指向对象的所在Region对应的记忆集(Remembered Set) 中
- 当进行垃圾收集时,在GC Roots枚举范围加上记忆集;就可以保证不进行全局扫描了。
G1的记忆集可以理解为一个哈希表,Key就是别的Region的起始地址,Value就是卡表的索引号集合。
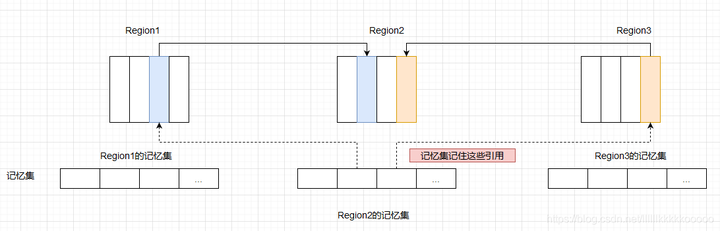
因为G1将Java堆划分为一个个Region的缘故,而Region数量相比于传统分代数量明显多得多,所以G1相比于传统的垃圾回收器来说,需要消耗相当于Java堆容量 10%~ 20%的额外空间来维持收集器的工作。
G1 垃圾回收器工作流程
- 初始标记(Initial Marking):这阶段仅仅只是标记GC Roots能直接关联到的对象并修改TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确的可用的Region中创建新对象,这阶段需要停顿线程,但是耗时很短。而且是借用进行Minor GC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。
- 并发标记(Concurrent Marking):从GC Roots开始对堆的对象进行可达性分析,递归扫描整个堆里的对象图,找出存活的对象,这阶段耗时较长,但是可以与用户程序并发执行。当对象图扫描完成以后,还要重新处理SATB记录下的在并发时有引用变动的对象。
- 最终标记(Final Marking):对用户线程做另一个短暂的暂停,用于处理并发阶段结束后仍遗留下来的最后那少量的 SATB 记录。
- 筛选回收(Live Data Counting and Evacuation):负责更新 Region 的统计数据,对各个 Region 的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划。可以自由选择多个Region来构成会收集,然后把回收的那一部分Region中的存活对象==复制==到空的Region中,在对那些Region进行清空。
除了并发标记外,其余过程都要 STW
G1和CMS的区别
- G1从整体上来看是 标记-整理 算法,但从局部(两个Region之间)是复制算法。而CMS是 标记-清除算法 所以说,G1不会产生内存碎片,而CMS会产生内存碎片
- CMS使用了 写后屏障来维护卡表,而G1不仅使用了写后屏障来维护卡表,还是用了 写前屏障来跟踪并发时的指针变化情况(为了实现原始快照)。
- CMS对Java堆内存使用的是传统的 新生代和老年代划分方法,而G1使用的全新的划分方法。
- CMS收集器只收集老年代,可以配合新生代的Serial和ParNew收集器一起使用。G1收集器收集范围是老年代和新生代。不需要结合其他收集器使用
- CMS使用 增量更新解决并发标记下出现的错误标记问题,而G1使用原始快照解决
JVM面试必问:G1垃圾回收器的更多相关文章
- JVM学习——G1垃圾回收器(学习过程)
JVM学习--G1垃圾回收器 把这个跨时代的垃圾回收器的笔记独立出来. 新生代:适用复制算法 老年代:适用标记清除.标记整理算法 二娃本来看G1的时候觉得比较枯燥,但是后来总结完之后告诉我说,一定要慢 ...
- 面试必问:JVM类加载机制详细解析
前言 在Java面试中,简历上有写JVM(Java虚拟机)相关的东西,JVM的类加载机制基本是面试必问的知识点. 类的加载和卸载 JVM是虚拟机的一种,它的指令集语言是字节码,字节码构成的文件是cla ...
- G1垃圾回收器在并发场景调优
一.序言 目前企业级主流使用的Java版本是8,垃圾回收器支持手动修改为G1,G1垃圾回收器是Java 11的默认设置,因此G1垃圾回收器可以用很长时间,现阶段垃圾回收器优化意味着针对G1垃圾回收器优 ...
- 一线大厂Java面试必问的2大类Tomcat调优
一.前言 最近整理了 Tomcat 调优这块,基本上面试必问,于是就花了点时间去搜集一下 Tomcat 调优都调了些什么,先记录一下调优手段,更多详细的原理和实现以后用到时候再来补充记录,下面就来介绍 ...
- G1垃圾回收器
垃圾回收器的发展历程 背景 01.G1解决的问题 G1垃圾回收器是04年正式提出,12开始正式支持,在17年作为JDK9默认的垃圾处理器. 在04年的时候,java程序堆的内存越来越大,从而导致程序中 ...
- linux驱动工程面试必问知识点
linux内核原理面试必问(由易到难) 简单型 1:linux中内核空间及用户空间的区别?用户空间与内核通信方式有哪些? 2:linux中内存划分及如何使用?虚拟地址及物理地址的概念及彼此之间的转化, ...
- 互联网公司面试必问的Redis题目
Redis是一个非常火的非关系型数据库,火到什么程度呢?只要是一个互联网公司都会使用到.Redis相关的问题可以说是面试必问的,下面我从个人当面试官的经验,总结几个必须要掌握的知识点. 介绍:Redi ...
- 【面试必问】python实例方法、类方法@classmethod、静态方法@staticmethod和属性方法@property区别
[面试必问]python实例方法.类方法@classmethod.静态方法@staticmethod和属性方法@property区别 1.#类方法@classmethod,只能访问类变量,不能访问实例 ...
- 互联网公司面试必问的mysql题目(下)
这是mysql系列的下篇,上篇文章地址我附在文末. 什么是数据库索引?索引有哪几种类型?什么是最左前缀原则?索引算法有哪些?有什么区别? 索引是对数据库表中一列或多列的值进行排序的一种结构.一个非常恰 ...
- 互联网公司面试必问的mysql题目(上)
又到了招聘的旺季,被要求准备些社招.校招的题库.(如果你是应届生,尤其是东北的某大学,绝对福利哦) 介绍:MySQL是一个关系型数据库管理系统,目前属于 Oracle 旗下产品.虽然单机性能比不上or ...
随机推荐
- MAC版本vmware无法识别虚拟机网卡适配器
一.问题 莫名其妙的突然mac上的vmware无法识别网络适配器了 二.解决过程 1.重装vmware-无效 2.降级安装vmware-无效 3.安装pd虚拟机,并使用sudo命令启动-偶尔有效 4. ...
- 2023平台工程崭露头角,AI 带来新机遇与挑战
在今年,平台工程正在迅速在 IT 企业中崭露头角,成为软件开发团队的必要实践.根据 CloudBees 发布的最新报告<2023年平台工程:快速采纳和影响>,83%的受访者已经完全实施了平 ...
- nodejs修改npm包安装位置
适用于非个人电脑.便携使用 npm config set cache D:\nodejs\node_cache npm config set prefix D:\nodejs npm config s ...
- npm 发布包时 图片打包在新的项目引入不显示 路径错误解决方案
使用的是vue-cli 4.0以上脚手架 vue2.6 封装好组件后 npm publish ,在其他项目引入该组件库 图片显示失败 打开F12时看到 组件库里图片是/img/图片名,可是该项目没有此 ...
- GPTs破冰硅基文明社会
GPTs破冰硅基文明社会 渐进是技术革命的常态 技术革命看似一夕之间就颠覆了世界,但实际上每项重大技术进步的背后,都经历了漫长的渐进积累.以蒸汽机为例,最初动力微弱.效率低下,需要大量工程师跟车维护, ...
- Windows Server 2022 安装IIS 报错 访问临时文件夹 C:\WINDOWS\TEMP\3C 读取/写入权限 错误: 0x80070005
在windows中使用命令行方式安装IIS(Web服务器) Windows Server 2022 安装IIS 报错 访问临时文件夹 C:\WINDOWS\TEMP\3C 读取/写入权限 错误: 0x ...
- TortoiseGit 使用 OpenSSH Key
中文互联网上没一个说这个东西的,还得是 stackoverflow,原文在这. 方法很简单,修改 TortoiseGit 默认 SSH Client: 修改为 Windows 系统默认 OpenSSH ...
- Log4j入门使用
前言 本篇文章主要在于,初步了解log4j,以及对它的简单使用 欢迎点赞 收藏 留言评论 私信必回哟 博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言 @ 目录 一,log4j简介 二,配 ...
- 在.net中通过自定义LoggerProvider将日志保存到数据库方法(以mysql为例)
在.NET中,Microsoft.Extensions.Logging是一个灵活的日志库,它允许你将日志信息记录到各种不同的目标,包括数据库.在这个示例中,我将详细介绍如何使用Microsoft.Ex ...
- bash shell笔记整理——file命令
file命令的作用 查看一个给定参数的文件类型 file命令语法 file [FILE...] file命令还有选项,但是基本用的不太多,这个命令也基本用得不是很多. 示例 [root@nginx-p ...