[转帖]学会使用Kafka(八)Kafka基本客户端命令操作
https://www.cnblogs.com/rexcheny/articles/9463811.html
主题管理
创建主题
|
1
|
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --create --topic TestCCC --partitions 3 --replication-factor 3 |
列出所有主题
|
1
2
3
4
|
kafka-topics.sh --list --bootstrap-server 172.16.100.10:9092# 对于启用了sasl权限的需要加上权限文件kafka-consumer-groups.sh --bootstrap-server 172.16.100.10:9092 --list --command-config ../config/sasl.properties |
列出所有消费者组
|
1
2
3
4
5
6
7
8
|
# 新版客户端 Kafka版本1.0./kafka-consumer-groups.sh --new-consumer --bootstrap-server 172.16.100.10:9092 --list | wc -l# 新版客户端,Kafka版本2.1./kafka-consumer-groups.sh --bootstrap-server 172.16.100.10:9092 --list# 旧版客户端./kafka-consumer-groups.sh --zookeeper 172.16.100.10:2181 --list | wc -l |
查看消费者组成员(仅限2.x以上)
|
1
|
kafka-consumer-groups.sh --describe --bootstrap-server 172.31.13.93:9092 --members --group GROUP_NAME |
查看所有主题详情
|
1
|
kafka-topics.sh --describe --bootstrap-server 172.16.100.10:9092 |
查看主题详情
|
1
|
kafka-topics.sh --describe --bootstrap-server 172.16.100.10:9092 --topic TestCCC |
查看所有ISR列表小于AR列表的主题
|
1
|
kafka-topics.sh --describe --bootstrap-server 192.168.5.138:9092 --under-replicated-partitions |
说明:如果没有返回任何信息则说明同步没有问题。因为正常情况下Replicats和Isr列表是相同的,如果同步有问题,有些副本落后太多则两个Isr列表的成员就会少。
查看特定主题的同步是否有问题
|
1
|
kafka-topics.sh --describe --bootstrap-server 192.168.5.138:9092 --under-replicated-partitions --topic Test |
查看哪些主题在建立是单独设置了配置
|
1
|
kafka-topics.sh --describe --bootstrap-server 192.168.5.138:9092 --topics-with-overrides |
查看主题参数
|
1
|
kafka-configs.sh --describe --zookeeper 172.16.100.10/kafka --entity-type topics --entity-name Test |
删除主题
|
1
|
kafka-topics.sh --delete --bootstrap-server 172.16.100.10:9092 --topic TestCCC |
这只是标记主题为删除,因为它是一个异步操作,如果发现某些时候删除了主题但是其ZK中的节点包括磁盘数据还都在,你可以手动清理一下:
删除ZK中/admin/delete_topics下的需要删除的主题名称
手动删除磁盘上的该主题分区目录
在ZK中执行 rmr /controller 来触发Controller的重新选举,这一步要慎重因为它会造成大规模Leader重新选举,不过只执行前两步也行,只是Controller中的缓存没有更新而已
delete.topic.enable=true 如果这个参数设置为false,那么你用命令删除了主题,Kafka也不会删除。只有该参数为true,那么Kafka才会异步删除相关数据,只有当其他情况kafka无法完成删除的时候你才需要手动删除。
修改主题的分区数量
|
1
|
kafka-topics.sh --bootstrap-server 172.16.100.10:9092 --alter --topic TestCCC --partitions 4 |
测试消息的生产和消费
启动生产者
|
1
|
kafka-console-producer.sh --broker-list 172.16.100.10:9092 --topic Test |
启动消费者
|
1
|
kafka-console-consumer.sh --bootstrap-server 172.16.100.10:9092 --topic Test --from-beginning |
获取指定主题当前总的消息数量
|
1
2
|
# --time -1 表示最大位移;--time -2 表示最早位移,这个通常是0kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.5.134:9092 --topic Test --time -1 |
说明:--time -1 的每个分区结果 减去 --time -2 的每个分区结果,然后每个分区差值相加就是当前主题有多少条消息
重设消费者位移
查看某个消费者组针对某个主题的位移信息
|
1
|
kafka-consumer-groups.sh --bootstrap-server 192.168.5.134:9092 --describe --group TestGroup |
重设位移必须要停止消费者
重设位移有几种选项:
- --to-earliest:设置到最早位移处,也就是0
- --to-latest:设置到最新处,也就是主题分区HW的位置
- --to-offset NUM:指定具体的位移位置
- --shift-by NUM:基于当前位移向前回退多少
- --by-duration:回退到多长时间
|
1
|
# 设置TestGroup消费者组所消费的所有topic位移回退到0<br><br>kafka-consumer-groups.sh --bootstrap-server 192.168.5.134:9092 --group TestGroup --reset-offsets --all-topics --to-earliest --execute<br><br># 也可以指定具体主题<br>kafka-consumer-groups.sh --bootstrap-server 192.168.5.134:9092 --group TestGroup --reset-offsets --topic Test --to-earliest --execute |
吞吐量测试
生产
|
1
|
kafka-producer-perf-test.sh --topic Test --num-records 100000 --record-size 150 --throughput -1 --producer-props bootstrap.servers=192.168.5.134:9092 acks=-1 |
消费
|
1
|
kafka-consumer-perf-test.sh --broker-list 192.168.5.134:9092 --messages 10000 --topic Test |
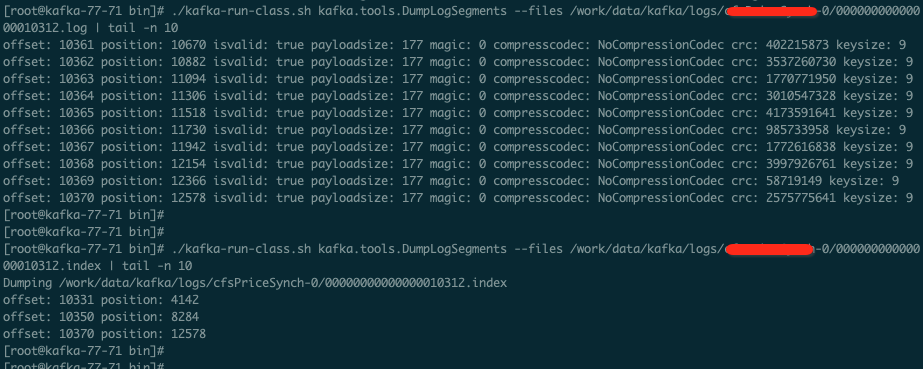
日志查看
我们可以通过命令来查看日志内容以及索引文件内容。
|
1
|
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /work/data/kafka/logs/hellokafka-0/00000000000000000000.log |
配置管理
所谓配置就是参数,比如修改主题的默认参数。
主题级别的
# 查看配置
kafka-configs.sh --describe --zookeeper 172.16.48.171:2181/kafka --entity-type topics --entity-name BB
这里显示 Configs for topic 'BBB' are 表示它的配置有哪些,这里没有表示没有为该主题单独设置配置,都是使用的默认配置。

# 增加一个配置
kafka-configs.sh --zookeeper 172.16.48.171:2181/kafka --entity-type topics --entity-name BBB --alter --add-config flush.messages=2

如果修改的话还是相同的命令,只是把值修改一下

# 删除配置
kafka-configs.sh --zookeeper 172.16.48.171:2181/kafka --entity-type topics --entity-name BBB --alter --delete-config flush.messages

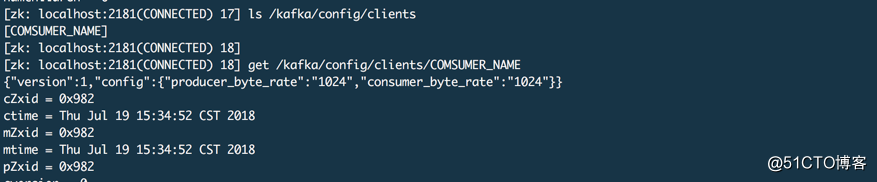
客户端级别
这个主要是设置流控
# 设置指定消费者的流控 --entity-name 是客户端在创建生产者或者消费者时是指定的client.id名称
kafka-configs.sh --zookeeper 172.16.48.171:2181/kafka --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=1024' --entity-type clients --entity-name COMSUMER_NAME

下图为ZK中对应的信息
查看当前有多少消费者组
./kafka-consumer-groups.sh --bootstrap-server 172.16.48.171:9092 --list

查看消费者组的消费偏移量
./kafka-consumer-groups.sh --bootstrap-server 172.16.48.171:9092 --describe --group TestGroup

CURRENT-OFFSET:当前消费者位移
LOG-END-OFFSET:分区最新位移
LAG:LOG-END-OFFSET减去CURRENT-OFFSET的值,表示积压量
CONSUMER-ID:是Kafka自己生成的
CLIENT-ID:是消费者代码里写的CLIENT ID,用于区分同消费者组中的不同客户端
注意:查看偏移量在kafka早期版本(0.9.0.0之前)使用下面的命令
kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zkconnect [ZOOKEEPER_IPADDRESS]:[ZOOKEEPER_PORT] --group [CONSUMER_GROUP]
分区管理
分区平衡
Leader副本在集群中应该是均衡分布,因为Leader副本对外提供读写服务,尽可能不让同一个主题的多个Leader副本在同一个代理上,但是随着时间推移比如故障转移等情况发送,Leader副本可能不均衡。有两种方式设置自动平衡,自动和手动。
自动就是在配置文件中增加 auto.leader.rebalance.enable = true 如果该项为false,当某个节点故障恢复并重新上线后,它原来的Leader副本也不会转移回来,只是一个Follower副本。
手动就是通过命令来执行
kafka-preferred-replica-election.sh --zookeeper 172.16.48.171:2181/kafka
分区迁移
当下线一个节点需要将该节点上的分区副本迁移到其他可用节点上,Kafka并不会自动进行分区迁移,如果不迁移就会导致某些主题数据丢失和不可用的情况。当增加新节点时,只有新创建的主题才会分配到新节点上,之前的主题分区不会自动分配到新节点上,因为老的分区在创建时AR列表中没有这个新节点。
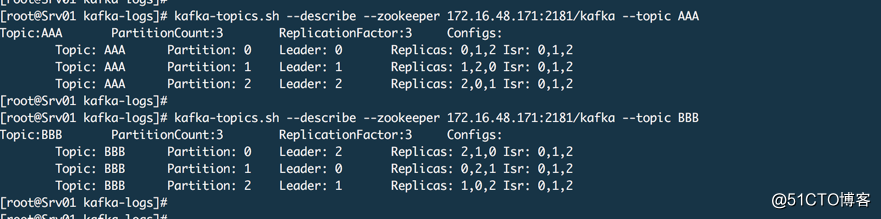
上面2个主题,每个主题3个分区,每个分区3个副本,我们假设现在代理2要下线,所以我们要把代理2上的这两个主题的分区数据迁移出来。

# 1. 在KAFKA目录的config目录中建立topics-to-move.json文件
{
"topics":[
{
"topic":"AAA"
},
{
"topic":"BBB"
}
],
"version":1
}
# 2. 生成分区分配方案,只是生成一个方案信息然后输出
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --topics-to-move-json-file ./topics-to-move.json --broker-list "1,2" --generate
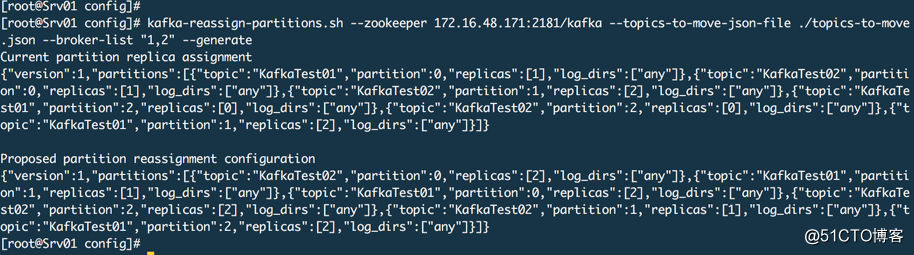
这个命令的原理是从zookeeper中读取主题元数据信息及制定的有效代理,根据分区副本分配算法重新计算指定主题的分区副本分配方案。把【Proposed partition reassignment configuration】下面的分区方案保存到一个JSON文件中,partitions-reassignment.json 文件名无所谓。
# 3. 执行方案
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./partitions-reassignment.json --execute
# 4. 查看进度
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./partitions-reassignment.json --verify

查看结果,这里已经没有代理0了。
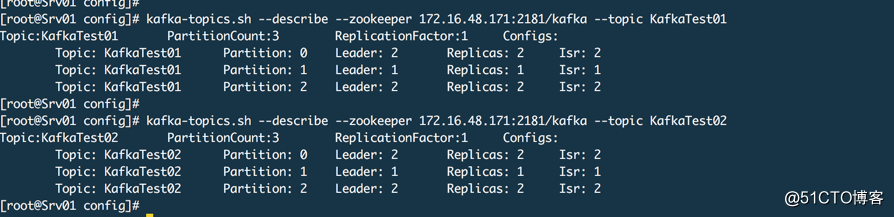
集群扩容
上面演示了节点下线的数据迁移,这里演示一下集群扩容的数据迁移。我们还是用上面两个主题,假设代理0又重新上线了。其实扩容就是上面的反向操作
# 1. 建立JSON文件
# 该文件和之前的相同 # 2. 生成方案并保存到一个JSON文件中
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --topics-to-move-json-file ./topics-to-move.json --broker-list "0,1,2" --generate
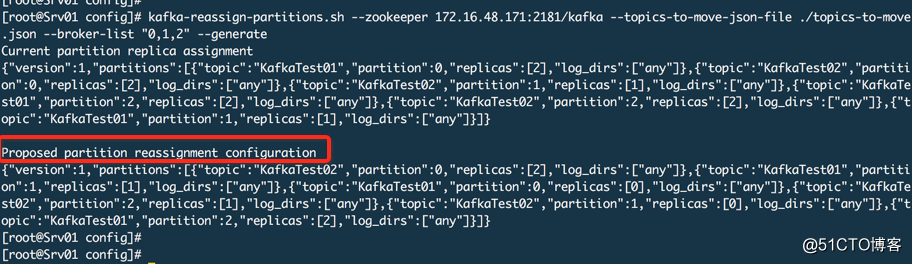
# 3. 数据迁移,这里通过--throttle做一个限流操作,如果数据过大会把网络堵塞。
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./partitions-reassignment.json --execute --throttle 1024
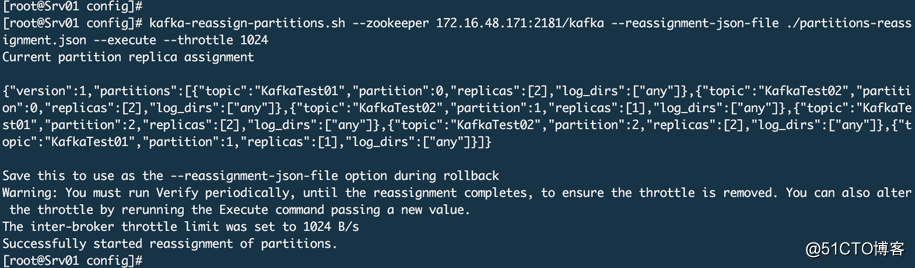
查看进度和结果
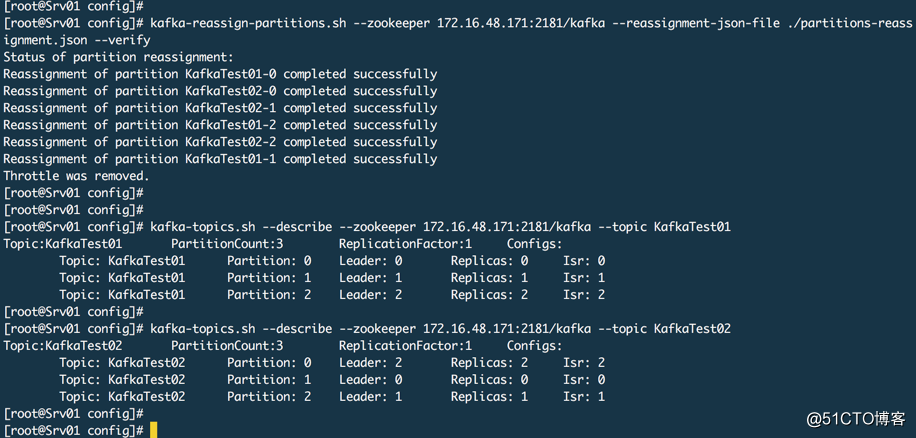
实际上上面这种方式也可以用在这种场景下,比如3台kafka集群这时候需要用新的机器替换老的机器,这时候你可以把新机器加入到这个老的机器中变成一个更大的集群,然后通过上面的方式在 --broker-list "新机器的ID" 然后进行执行,这样的话这个集群中的消息以后就只会发送到新的机器上。然后切换生产者到新机器上,切换一些消费者到新机器上,这样老机器队列消费完毕就可以把剩余的消费者也切换到新机器上。老机器就可以下线了。
增加分区
通常在需要提供吞吐量的时候我们会增加分区,然后如果代理数量不扩大,同时生产者和消费者线程不增大,你扩展了分区也没有用。
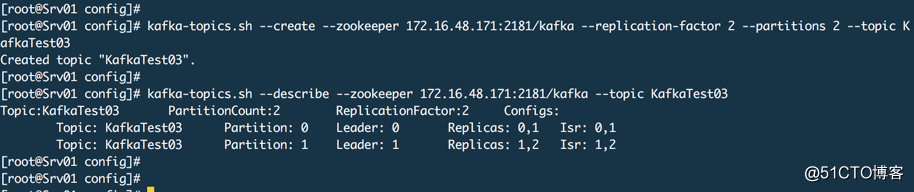
kafka-topics.sh --alter --zookeeper 172.16.48.171:2181/kafka --partitions 3 --topic KafkaTest03
增加副本
集群规模扩大并且想对所有主题或者指定主题提高可用性,那么可以增加原有主题的副本数量

上面是3个分区,每个分区1个副本,我们现在把每个分区扩展为3个副本
# 1. 创建JSON文件 replica-extends.json
{
"version": 1,
"partitions": [{
"topic": "KafkaTest04",
"partition": 0,
"replicas": [0,1,2]
},
{
"topic": "KafkaTest04",
"partition": 1,
"replicas": [0,1,2]
},
{
"topic": "KafkaTest04",
"partition": 2,
"replicas": [0,1,2]
}
]
}
# 2. 执行分区副本重新分配命令
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./replica-extends.json --execute

查看状态

查看结果

镜像操作
Kafka有一个镜像工具kafka-mirror-maker.sh,用于将一个集群数据同步到另外一个集群中,这个非常有用,比如机房搬迁就需要进行数据同步。该工具的本质就是创建一个消费者,在源集群中需要迁移的主题消费数据,然后创建一个生产者,将消费的数据写入到目标集群中。
首先创建消费者配置文件mirror-consumer.properties(文件路径和名称是自定义的)
# 源kafka集群代理地址列表
bootstrap.servers=IP1:9092,IP2:9092,IP3:9092
# 消费者组名
group.id=mirror
其次创建生产者配置文件mirror-producer.properties(文件路径和名称是自定义的)
# 目标kafka集群地址列表
bootstrap.servers=IP1:9092,IP2:9092,IP3:9092
运行镜像命令
# 通过 --whitelist 指定需要镜像的主题,通过 --blacklist 指定不需要镜像的主题
# --new.producer 使用新的生产者 --new.consumer 使用新的消费者
# --num.streams N 消费者线程数量 --num.producers N 生产者线程数量
kafka-mirror-maker.sh --consumer.config PATH/mirror-consumer.properties --producer.config PATH/mirror-producer.properties --whitelist TOPIC
由于镜像操作是启动一个生产者和消费者,所以数据同步完成后这个生产者和消费者并不会关闭,它会依然等待新数据,所以同步完成以后你需要自己查看,确认完成了则关闭生产者和消费者。另外目标集群上并不需要提前建立主题,它会自己建立,但是如果已经建立好了它就会直接使用。
下面是一个我在公司测试环(kafka版本为 0.8.1.1,下面的命令和新版本kafka略有区别)境测试迁移的一个截图,我这里只测试了 EEE999 这个主题
./kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config ./mirrorConsumerConf.conf --num.streams 10 --producer.config ./mirrorProducerConf.conf -num.producers 10 --whitelist "EEE999"
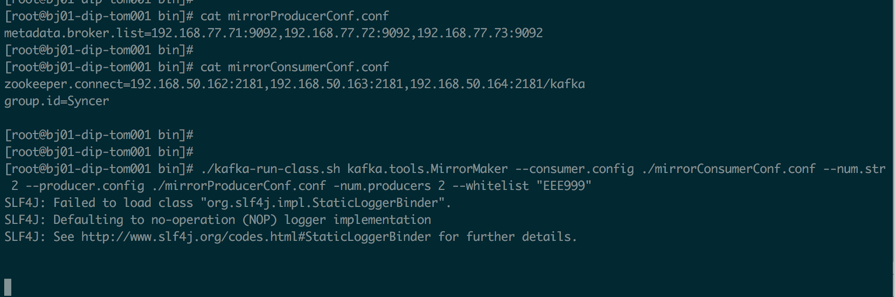
目标服务器不需要提前建立这个主题,你可以建立也可以不建立。这个命令可以用 nohup 执行放到后台。然后通过下面的命令查看同步进度
./kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zkconnect 192.168.50.162:2181/kafka --gyncer --topic EEE999
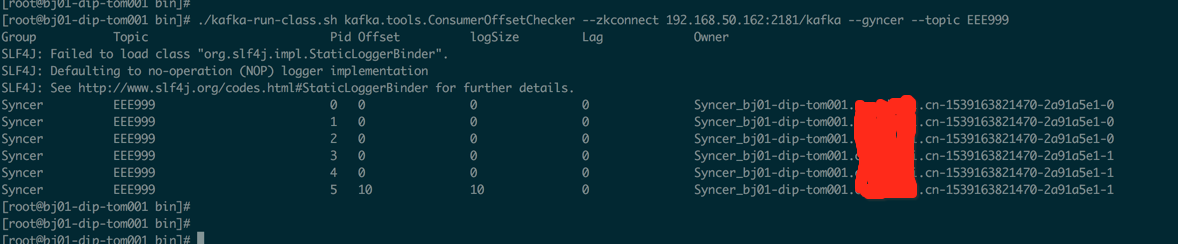
注意,它的同步是把原有的数据都同步到目标环境中,所以如果在老版本中两个卡夫卡集群是完全独立的那么意味着ZK也是独立的,所以新环境中的消费者在消费队列的时候可能会出现重复消费的情况,这就需要你的程序支持幂等原则或者手动设置消费偏移量。
[转帖]学会使用Kafka(八)Kafka基本客户端命令操作的更多相关文章
- CentOS 7部署Kafka和Kafka集群
CentOS 7部署Kafka和Kafka集群 注意事项 需要启动多个shell脚本交互客户端进行验证,运行中的客户端不要停止. 准备工作: 安装java并设置java环境变量,在`/etc/prof ...
- Kafka(3)--kafka消息的存储及Partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 [root@localhost ~]# ...
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...
- Apache Kafka安全| Kafka的需求和组成部分
1.目标 - 卡夫卡安全 今天,在这个Kafka教程中,我们将看到Apache Kafka Security 的概念 .Kafka Security教程包括我们需要安全性的原因,详细介绍加密.有了这 ...
- kafka - Confluent.Kafka
上个章节我们讲了kafka的环境安装(这里),现在主要来了解下Kafka使用,基于.net实现kafka的消息队列应用,本文用的是Confluent.Kafka,版本0.11.6 1.安装: 在NuG ...
- Kafka 教程(二)-安装与基础操作
单机安装 1. 安装 java 2. 安装 zookeeper [这一步可以没有,因为 kafka 自带了 zookeeper] 3. 安装 kafka 下载链接 kafka kafka 是 scal ...
- 最好用的 Kafka Json Logger Java客户端,赶紧尝试一下
最好用的 Kafka Json Logger Java客户端. slf4j4json 最好用的 Kafka Json Logger 库:不尝试一下可惜了! Description 一款为 Kafka ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- Apache Kafka教程--Kafka新手入门
Apache Kafka教程--Kafka新手入门 Kafka Assistant 是一款 Kafka GUI 管理工具--管理Broker,Topic,Group.查看消费详情.监控服务器状态.支持 ...
- 上网八个常用cmd命令你掌握了几个?
上网八个常用cmd命令你掌握了几个? 一.ping 它是用来检查网络是否通畅或者网络连接速度的命令.作为一个生活在网络上的管理员或者黑客来说,ping命令是第一个必须掌握 ...
随机推荐
- 云图说|AI开发难!难!难!端云协同多模态AI开发套件你需要了解一下
摘要:Huawei HiLens Kit是一款端云协同多模态AI开发套件,支持图像.视频.语音等多种数据分析与推理计算,可广泛用于智能监控.智能家庭.机器人.无人机.智慧工业.智慧门店等分析场景. 在 ...
- AI如何提升10倍筛药效率?6月18日华为云携手中科院上海药物所揭开谜底
摘要:6月18日,华为云TechWave全球技术峰会(人工智能&数据)围绕人工智能.大数据.数据库.华为云Stack等热点话题,携手来自全球的IT精英.技术大咖.先锋企业.合作伙伴共话前沿技术 ...
- 想了解Xtrabackup备份原理和常见问题分析,看这篇就够了
摘要:本文来自华为云MySQL研发团队,主要分享了MySQL备份工具Xtrabackup的备份过程.华为云数据库团队对其做的优化改进,以及在使用中可能遇到的问题与解决方法. 本文分享自华为云社区< ...
- 梦幻联动!金蝶&华为云面向大企业发布数据库联合解决方案
摘要:近日,金蝶软件(中国)有限公司(以下简称"金蝶")携手华为云共同发布了金蝶云·星瀚.金蝶云·苍穹和GaussDB(for openGauss)数据库联合解决方案. 本文分享自 ...
- Git 工具 - 子模块: submodule与subtree的使用
git日常使用中,基本都是一个项目一个Git仓库的形式,那么当我们的代码中碰到了业务级别的需要复用的代码,我们一般怎么做呢? 比如:某个工作中的项目需要包含并使用另一个项目. 也许是第三方库,或者你独 ...
- iOS应用上架详细图文教程
App Store作为苹果官方的应用商店,审核严格周期长一直让用户头疼不已,很多app都"死"在了审核这一关,那我们就要放弃iOS用户了吗?当然不是!本期我们从iOS app上 ...
- 总结MySQL 的一些知识点:MySQL 连接的使用
MySQL 连接的使用 在前几章节中,我们已经学会了如何在一张表中读取数据,这是相对简单的,但是在真正的应用中经常需要从多个数据表中读取数据. 本章节我们将向大家介绍如何使用 MySQL 的 JOIN ...
- 火山引擎 DataLeap 一招教你避坑“数据开发”中的资源隔离问题
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 在离线数仓开发过程中,研发人员需要根据业务变化,在开发/生产环境中不断切换.解析.调试.以往,企业一般通过人工方式 ...
- PPT 呼吸感
任何元素都应该保持一定的距离,留出可以"呼吸"的空间 呼吸感 怎么营造 不要让内容超出/接近边框 类似的元素摆放在一起 控制 行间距/字间距 行间距:1.3.字间距:1.0 :行间 ...
- 你正在调试XXX的发布版本,如果在启用 仅我的代码 的同时,使用通过编译器优化的发布版本
仅我的代码"警告 你正在调试 XXX.dll 的发布版本.如果在启用"仅我的代码"的同时使用通过编译器优化的发布版本,调试体验会降级(例如,将不会命中断点) 停止调试禁用 ...