机器学习算法(四): 基于支持向量机的分类预测(SVM)
机器学习算法(四): 基于支持向量机的分类预测
本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc
1.相关流程
支持向量机(Support Vector Machine,SVM)是一个非常优雅的算法,具有非常完善的数学理论,常用于数据分类,也可以用于数据的回归预测中,由于其其优美的理论保证和利用核函数对于线性不可分问题的处理技巧,在上世纪90年代左右,SVM曾红极一时。
本文将不涉及非常严格和复杂的理论知识,力求于通过直觉来感受 SVM。
推荐参考:SVM参考文章
- 了解支持向量机的分类标准;
- 了解支持向量机的软间隔分类;
- 了解支持向量机的非线性核函数分类;
- Demo实践
- Step1:库函数导入
- Step2:构建数据集并进行模型训练
- Step3:模型参数查看
- Step4:模型预测
- Step5:模型可视化
2. 算法实战
2.1 Demo实践
首先我们利用sklearn直接调用 SVM函数进行实践尝试
Step1:库函数导入
## 基础函数库
import numpy as np
## 导入画图库
import matplotlib.pyplot as plt
import seaborn as sns
## 导入逻辑回归模型函数
from sklearn import svm
Step2:构建数据集并进行模型训练
##Demo演示LogisticRegression分类
## 构造数据集
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])
y_label = np.array([0, 0, 0, 1, 1, 1])
## 调用SVC模型 (支持向量机分类)
svc = svm.SVC(kernel='linear')
## 用SVM模型拟合构造的数据集
svc = svc.fit(x_fearures, y_label)
Step3:模型参数查看
## 查看其对应模型的w
print('the weight of Logistic Regression:',svc.coef_)
## 查看其对应模型的w0
print('the intercept(w0) of Logistic Regression:',svc.intercept_)
the weight of Logistic Regression: [[0.33364706 0.33270588]]
the intercept(w0) of Logistic Regression: [-0.00031373]
Step4:模型预测
## 模型预测
y_train_pred = svc.predict(x_fearures)
print('The predction result:',y_train_pred)
The predction result: [0 0 0 1 1 1]
Step5:模型可视化
由于此处选择的线性核函数,所以在此我们可以将svm进行可视化。
# 最佳函数
x_range = np.linspace(-3, 3)
w = svc.coef_[0]
a = -w[0] / w[1]
y_3 = a*x_range - (svc.intercept_[0]) / w[1]
# 可视化决策边界
plt.figure()
plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
plt.plot(x_range, y_3, '-c')
plt.show()
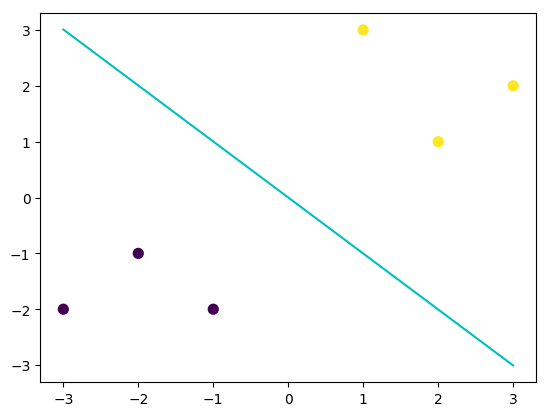
可以对照之前的逻辑回归模型的决策边界,我们可以发现两个决策边界是有一定差异的(可以对比两者在X,Y轴上的截距),这说明这两个不同在相同数据集上找到的判别线是不同的,而这不同的原因其实是由于两者选择的最优目标是不一致的。接下来我们进行SVM的一些简单介绍。
2.2 实践升级
我们常常会碰到这样的一个问题,首先给你一些分属于两个类别的数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
%matplotlib inline
# 画图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=60, cmap=plt.cm.Paired)

现在需要一个线性分类器,将这些数据分开来。
我们可能会有多种分法:
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
x_fit = np.linspace(0, 3)
# 画函数
y_1 = 1 * x_fit + 0.8
plt.plot(x_fit, y_1, '-c')
y_2 = -0.3 * x_fit + 3
plt.plot(x_fit, y_2, '-k')

那么现在有一个问题,两个分类器,哪一个更好呢?
为了判断好坏,我们需要引入一个准则:好的分类器不仅仅是能够很好的分开已有的数据集,还能对未知数据集进行两个的划分。
假设,现在有一个属于红色数据点的新数据(3, 2.8)
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
plt.scatter([3], [2.8], c='#cccc00', marker='<', s=100, cmap=plt.cm.Paired)
x_fit = np.linspace(0, 3)
# 画函数
y_1 = 1 * x_fit + 0.8
plt.plot(x_fit, y_1, '-c')
y_2 = -0.3 * x_fit + 3
plt.plot(x_fit, y_2, '-k')

可以看到,此时黑色的线会把这个新的数据集分错,而蓝色的线不会。
我们刚刚举的例子可能会带有一些主观性。
那么如何客观的评判两条线的健壮性呢?
此时,我们需要引入一个非常重要的概念:最大间隔。
最大间隔刻画着当前分类器与数据集的边界,以这两个分类器为例:
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
x_fit = np.linspace(0, 3)
# 画函数
y_1 = 1 * x_fit + 0.8
plt.plot(x_fit, y_1, '-c')
# 画边距
plt.fill_between(x_fit, y_1 - 0.6, y_1 + 0.6, edgecolor='none', color='#AAAAAA', alpha=0.4)
y_2 = -0.3 * x_fit + 3
plt.plot(x_fit, y_2, '-k')
plt.fill_between(x_fit, y_2 - 0.4, y_2 + 0.4, edgecolor='none', color='#AAAAAA', alpha=0.4)

可以看到, 蓝色的线最大间隔是大于黑色的线的。
所以我们会选择蓝色的线作为我们的分类器。
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画图
y_1 = 1 * x_fit + 0.8
plt.plot(x_fit, y_1, '-c')
# 画边距
plt.fill_between(x_fit, y_1 - 0.6, y_1 + 0.6, edgecolor='none', color='#AAAAAA', alpha=0.4)

那么,我们现在的分类器是最优分类器吗?
或者说,有没有更好的分类器,它具有更大的间隔?
答案是有的。
为了找出最优分类器,我们需要引入我们今天的主角:SVM
from sklearn.svm import SVC
# SVM 函数
clf = SVC(kernel='linear')
clf.fit(X, y)
SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
# 最佳函数
w = clf.coef_[0]
a = -w[0] / w[1]
y_3 = a*x_fit - (clf.intercept_[0]) / w[1]
# 最大边距 下届
b_down = clf.support_vectors_[0]
y_down = a* x_fit + b_down[1] - a * b_down[0]
# 最大边距 上届
b_up = clf.support_vectors_[-1]
y_up = a* x_fit + b_up[1] - a * b_up[0]
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画函数
plt.plot(x_fit, y_3, '-c')
# 画边距
plt.fill_between(x_fit, y_down, y_up, edgecolor='none', color='#AAAAAA', alpha=0.4)
# 画支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none')

带黑边的点是距离当前分类器最近的点,我们称之为支持向量。
支持向量机为我们提供了在众多可能的分类器之间进行选择的原则,从而确保对未知数据集具有更高的泛化性。
2.2.1 软间隔
但很多时候,我们拿到的数据是这样子的
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.9)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)

这种情况并不容易找到这样的最大间隔。
于是我们就有了软间隔,相比于硬间隔而言,我们允许个别数据出现在间隔带中。
我们知道,如果没有一个原则进行约束,满足软间隔的分类器也会出现很多条。
所以需要对分错的数据进行惩罚,SVC 函数中,有一个参数 C 就是惩罚参数。
惩罚参数越小,容忍性就越大。
以 C=1 为例子,比如说:
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.9)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 惩罚参数:C=1
clf = SVC(C=1, kernel='linear')
clf.fit(X, y)
# 最佳函数
w = clf.coef_[0]
a = -w[0] / w[1]
y_3 = a*x_fit - (clf.intercept_[0]) / w[1]
# 最大边距 下届
b_down = clf.support_vectors_[0]
y_down = a* x_fit + b_down[1] - a * b_down[0]
# 最大边距 上届
b_up = clf.support_vectors_[-1]
y_up = a* x_fit + b_up[1] - a * b_up[0]
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画函数
plt.plot(x_fit, y_3, '-c')
# 画边距
plt.fill_between(x_fit, y_down, y_up, edgecolor='none', color='#AAAAAA', alpha=0.4)
# 画支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none')

惩罚参数 C=0.2 时,SVM 会更具包容性,从而兼容更多的错分样本:
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.9)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 惩罚参数:C=0.2
clf = SVC(C=0.2, kernel='linear')
clf.fit(X, y)
x_fit = np.linspace(-1.5, 4)
# 最佳函数
w = clf.coef_[0]
a = -w[0] / w[1]
y_3 = a*x_fit - (clf.intercept_[0]) / w[1]
# 最大边距 下届
b_down = clf.support_vectors_[10]
y_down = a* x_fit + b_down[1] - a * b_down[0]
# 最大边距 上届
b_up = clf.support_vectors_[1]
y_up = a* x_fit + b_up[1] - a * b_up[0]
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画函数
plt.plot(x_fit, y_3, '-c')
# 画边距
plt.fill_between(x_fit, y_down, y_up, edgecolor='none', color='#AAAAAA', alpha=0.4)
# 画支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none')

2.2.2 超平面
如果我们遇到这样的数据集,没有办法利用线性分类器进行分类
from sklearn.datasets.samples_generator import make_circles
# 画散点图
X, y = make_circles(100, factor=.1, noise=.1, random_state=2019)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
clf = SVC(kernel='linear').fit(X, y)
# 最佳函数
x_fit = np.linspace(-1.5, 1.5)
w = clf.coef_[0]
a = -w[0] / w[1]
y_3 = a*X - (clf.intercept_[0]) / w[1]
plt.plot(X, y_3, '-c')

我们可以将二维(低维)空间的数据映射到三维(高维)空间中。
此时,我们便可以通过一个超平面对数据进行划分
所以,我们映射的目的在于使用 SVM 在高维空间找到超平面的能力。
# 数据映射
from mpl_toolkits.mplot3d import Axes3D
r = np.exp(-(X[:, 0] ** 2 + X[:, 1] ** 2))
ax = plt.subplot(projection='3d')
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap=plt.cm.Paired)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
x_1, y_1 = np.meshgrid(np.linspace(-1, 1), np.linspace(-1, 1))
z = 0.01*x_1 + 0.01*y_1 + 0.5
ax.plot_surface(x_1, y_1, z, alpha=0.3)

在 SVC 中,我们可以用高斯核函数来实现这以功能:kernel='rbf'
# 画图
X, y = make_circles(100, factor=.1, noise=.1, random_state=2019)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
clf = SVC(kernel='rbf')
clf.fit(X, y)
ax = plt.gca()
x = np.linspace(-1, 1)
y = np.linspace(-1, 1)
x_1, y_1 = np.meshgrid(x, y)
P = np.zeros_like(x_1)
for i, xi in enumerate(x):
for j, yj in enumerate(y):
P[i, j] = clf.decision_function(np.array([[xi, yj]]))
ax.contour(x_1, y_1, P, colors='k', levels=[-1, 0, 0.9], alpha=0.5,
linestyles=['--', '-', '--'])
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none');

此时便完成了非线性分类。
3.总结
SVM优缺点
优点
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 能找出对任务至关重要的关键样本(即:支持向量);
- 采用核技巧之后,可以处理非线性分类/回归任务;
- 最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
缺点
- 训练时间长。当采用SMO 算法时,由于每次都需要挑选一对参数,因此时间复杂度为$O(N^2)$ ,其中 $N$ 为训练样本的数量;
- 当采用核技巧时,如果需要存储核矩阵,则空间复杂度为$O(N^2)$ ;
- 模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。
因此支持向量机目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务
本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc
项目参考: https://tianchi.aliyun.com/course/278/3420
机器学习算法(四): 基于支持向量机的分类预测(SVM)的更多相关文章
- Android版数据结构与算法(四):基于哈希表实现HashMap核心源码彻底分析
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 存储键值对我们首先想到HashMap,它的底层基于哈希表,采用数组存储数据,使用链表来解决哈希碰撞,它是线程不安全的,并且存储的key只能有一个为 ...
- 吴恩达机器学习笔记45-使用支持向量机(Using A SVM)
本篇我们讨论如何运行或者运用SVM. 在高斯核函数之外我们还有其他一些选择,如:多项式核函数(Polynomial Kernel)字符串核函数(String kernel)卡方核函数( chi-squ ...
- paper 19 :机器学习算法(简介)
本来看了一天的分类器方面的代码,乱乱的,索性再把最基础的概念拿过来,现总结一下机器学习的算法吧! 1.机器学习算法简述 按照不同的分类标准,可以把机器学习的算法做不同的分类. 1.1 从机器学习问题角 ...
- 机器学习算法( 七、AdaBoost元算法)
一.概述 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此?这就是元算法(meta-algorithm)背后的思路.元算法是对其他算法进行组合的一种方 ...
- 机器学习算法-K-NN的学习 /ML 算法 (K-NEAREST NEIGHBORS ALGORITHM TUTORIAL)
1为什么我们需要KNN 现在为止,我们都知道机器学习模型可以做出预测通过学习以往可以获得的数据. 因为KNN基于特征相似性,所以我们可以使用KNN分类器做分类. 2KNN是什么? KNN K-近邻,是 ...
- 《机器学习实战(基于scikit-learn和TensorFlow)》第六章内容学习心得
本章讲决策树 决策树,一种多功能且强大的机器学习算法.它实现了分类和回归任务,甚至多输出任务. 决策树的组合就是随机森林. 本章的代码部分不做说明,具体请到我的GitHub上自行获取. 决策树的每个节 ...
- Python实现的各种机器学习算法
七种算法包括: 线性回归算法 Logistic 回归算法 感知器 K 最近邻算法 K 均值聚类算法 含单隐层的神经网络 多项式的 Logistic 回归算法 01 线性回归算法 在线性回归中,我们想要 ...
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码) Python 被称为是最接近 AI 的语言.最近一位名叫Anna-Lena Popkes的小姐姐在GitHub上分享了自己如何使用P ...
- 【机器学习算法-python实现】决策树-Decision tree(1) 信息熵划分数据集
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 决策书算法是一种逼近离散数值的分类算法,思路比較简单,并且准确率较高.国际权威的学术组织,数据挖掘国际 ...
- 机器学习算法(二): 基于鸢尾花数据集的朴素贝叶斯(Naive Bayes)预测分类
机器学习算法(二): 基于鸢尾花数据集的朴素贝叶斯(Naive Bayes)预测分类 项目链接参考:https://www.heywhale.com/home/column/64141d6b1c8c8 ...
随机推荐
- 股票数据爬虫进阶:免费、开源的股票爬虫Python库,实测真香
更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流. 免费.开源的股票爬虫Python库:Easyquotation 我们在此前的文章中,向大家分享了如何用P ...
- C# 防XSS攻击 示例
思路: 对程序代码进行过滤非法的关键字 新建控制台程序,编写代码测试过滤效果 class Program { static void Main(string[] args) { //GetStrReg ...
- 一文看完String的前世今生,内容有点多,请耐心看完!
写在开头 String字符串作为一种引用类型,在Java中的地位举足轻重,也是代码中出现频率最高的一种数据结构,因此,我们需要像分析Object一样,将String作为一个topic,单独拿出来总结, ...
- 在Python中使用Process创建子进程遇到的问题
假如使用Process创建子进程,那么在最后的函数调用时需要加上if __name__ == "__main__":语句,否则会报错. 未使用该语句 代码示例 from multi ...
- 【日常踩坑】解决 kex_exchange_identification 报错
目录 踩坑 原因分析 解决办法 1. 临时关闭代理 2. 修改代理软件配置,22 端口走直连 3. 改用 HTTPS 协议,走 443 端口 参考资料 踩坑 最近在使用 git 时,发现 git pu ...
- 应用程序使用统计信息 – .NET CORE(C#) WPF界面设计
应用程序使用统计信息 - .NET CORE(C#) WPF界面设计 首发文章地址:https://dotnet9.com/10546.html 关键功能点 抽屉式菜单 圆形进度条 Demo演示: 1 ...
- java - 创建文件
package practice; import java.io.File; import java.io.IOException; public class CreateFile { public ...
- CSS : div 高度为0的三种情况
1, css 样式没正确绑定 ( 也就是没有设置高度 ) 2, 子元素 浮动 ( float ) 3, 子元素 绝对定位 ( position : absolute )
- MySQL高可用搭建方案之(MMM)
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 注意:这篇转载文章,非原创 首发博客地址 原文地址 前言 MySQL的高可用 ...
- SQLServer的varchar与nvarchar的学习之二
SQLServer的varchar与nvarchar的学习之二 背景 昨天简单总结了多种数据库 varchar和nvarchar的区别与关系 今天想着能够分析一下数据库文件. 计划使用winhex 查 ...