GaussDB(for MySQL)剪枝功能,让查询性能提升70倍!
作者,祝青平,华为云数据库内核高级工程师。擅长数据库优化器内核研发,9年数据库内核研发经验,参与多个TP以及AP数据库的研发工作。
近日,华为云数据库社区下面有这样一条用户提问留言:请问,如何通过MySQL提升DISTINCT,尤其是多表连接下DISTINCT的查询效率?
在回答这个问题之前,我们先了解一下DISTINCT。
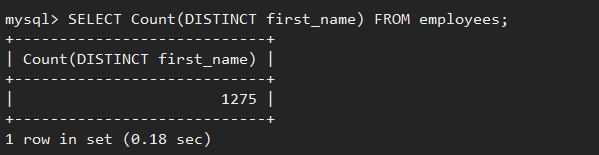
在SQL语句中,DISTINCT关键词用于返回唯一不同的值,使用场景多,应用频繁。它可以用于做单列数据去重,例如,对公司雇员按照”first_name”去重后,得到1275条记录。
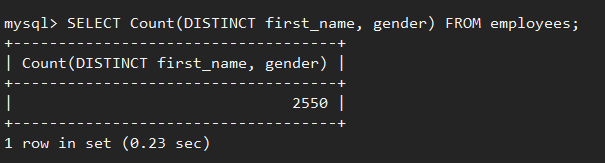
也可以做多列去重,即只有所有指定列的信息都相同时,才会被认为是重复的信息,例如,对公司雇员按照”first_name”和”gender”两列去重后得到2550条记录。
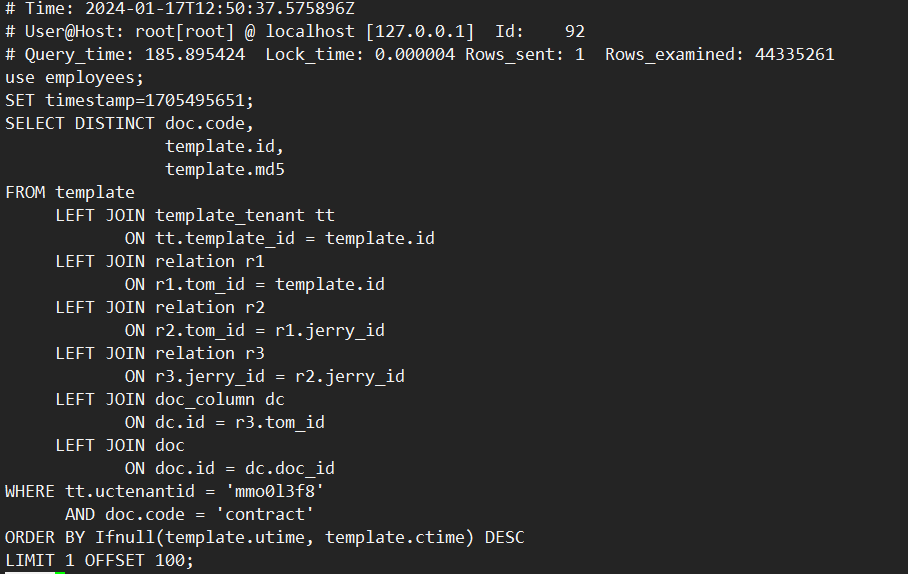
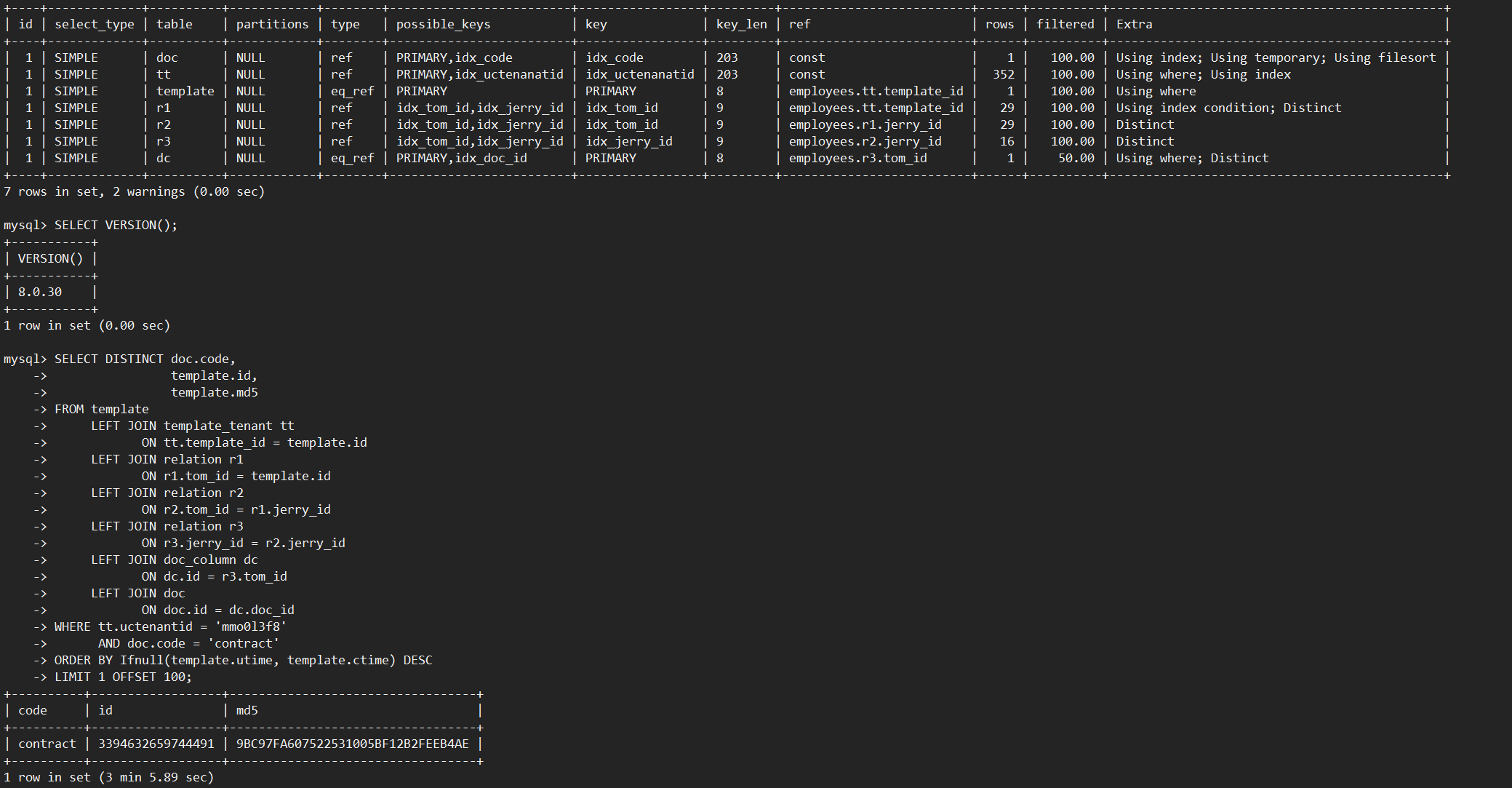
对于“多表连接+DISTINCT”场景,MySQL 8.0需要扫描表连接后的结果。当表连接数量多或基表数据量大时,扫描的数据量也会很大,会导致执行效率很低。如下示例,对7个表连接后的结果做DISTINCT,使用MySQL 8.0.30社区版本,执行耗时186秒,通过查看慢日志信息,发现扫描了约4400万行数据。
为了提升DISTINCT,尤其多表连接下DISTINCT的查询效率,GaussDB(for MySQL)在执行优化器中加入了剪枝功能,可以去除不必要的扫描分支,节省查询耗时。
GaussDB(for MySQL)剪枝方案
以下面的SQL执行为例,表t1有4行数据1,2,5,6。执行如下多表连接+DISTINCT:
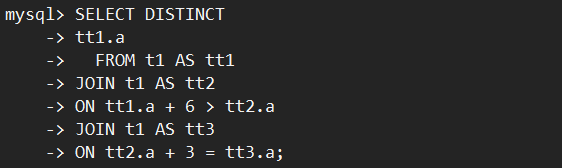
表连接执行逻辑如下:

上述例子中,在MySQL 8.0.30社区版本执行器需要扫描60行数据才能获得结果集。找到满足条件的唯一结果{i=1,j=2,k=5}后,不会停止本轮扫描,而是继续扫描{i=1,j=5,k=1}及后续无用的数据,导致执行时间长。详细的执行流程参见下图:
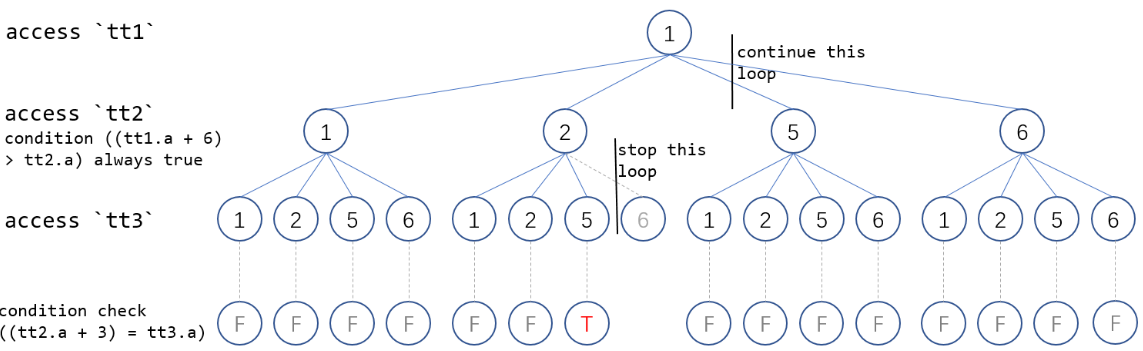
针对如上的多表连接+DISTINCT执行效率慢的问题,GaussDB(for MySQL)在火山模型的执行器上实现了提前减枝优化,当找到满足的条件的DISTINCT值之后,通过全局变量判断是否可以提前结束本轮迭代,并层层退出,大幅减少了扫描工作量。
以上述SQL为例,在扫描{1,1,1},{1,1,2},{1,1,5},{1,1,8},{1,2,1},{1,2,2},{1,2,5} 7组数据后,找到满足DISTINCT 条件值 tt1.a "1",立即结束本轮迭代,并停止上一层迭代。该例子中只需要扫描28行数据就可获得最终结果集,相比MySQL 8.0社区版本扫描60行,GaussDB(for MySQL)性能显著提升。
GaussDB(for MySQL)剪枝特性使用方法
打开特性开关:SET rds_nlj_distinct_optimize=ON;
通过”EXPLAIN FORMAT=TREE”查看特性是否生效,执行计划中出现” join with distinct optimization”关键字说明特性生效,查询过程中可进行减枝优化,提升多表JOIN+DISTINCT执行效率。
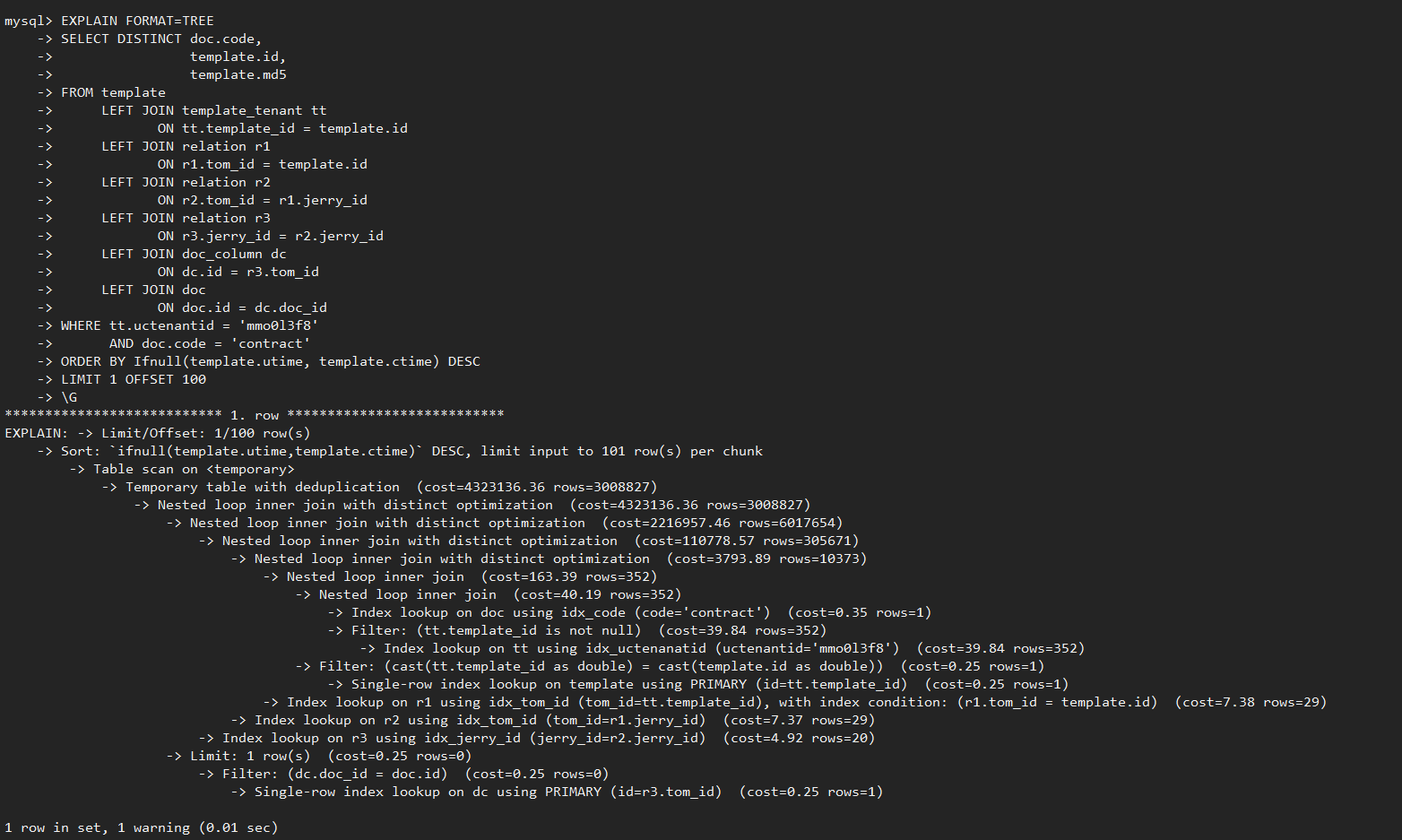
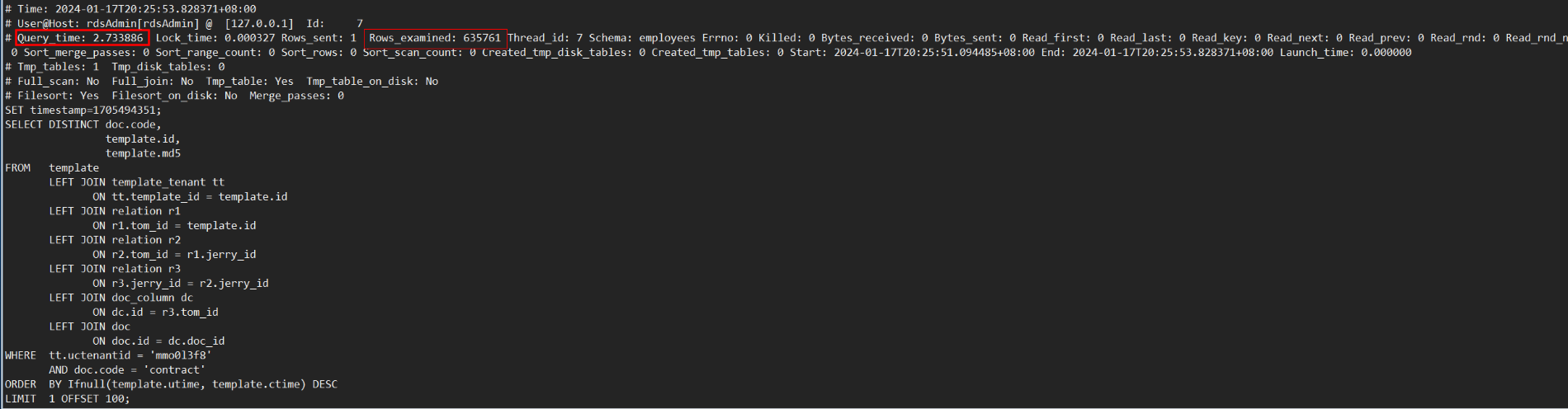
GaussDB(for MySQL)剪枝典型场景测试对比
前面提到的测试样例中,GaussDB(for MySQL)执行耗时2.7秒完成,只需要扫描数据量约61万行;相比MySQL 8.0 社区版本执行耗时约186秒,扫描数据量4400万,执行耗时和扫描数据量减少近70倍,实现了执行效率飞跃式提升。如下图所示:
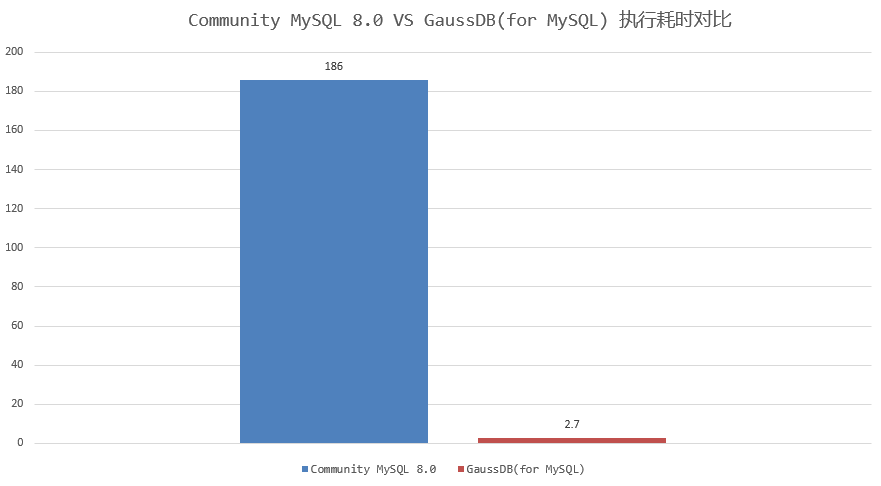
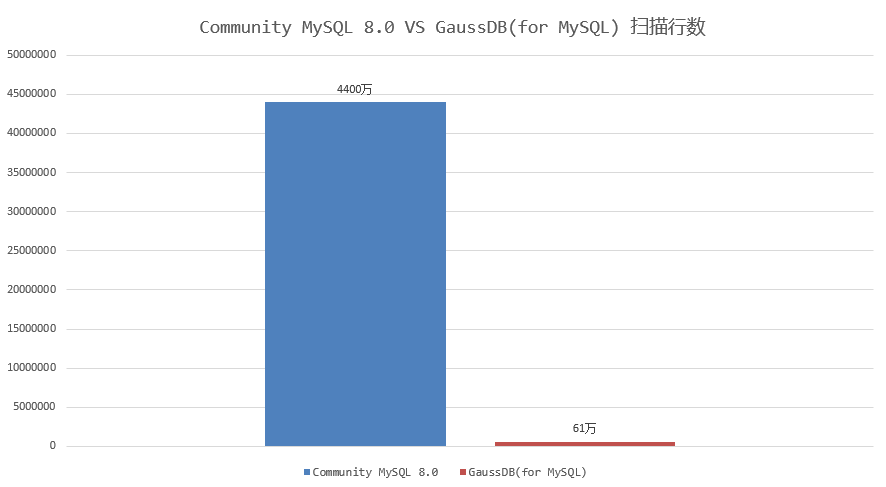
因此,针对“多表连接+DISTINCT”的场景,GaussDB(for MySQL)在执行过程中动态剪枝,裁剪掉大量无用数据,减少执行过程中扫描数据量,是提升查询效率的秘密武器。
总结:
以上通过对GaussDB(for MySQL)剪枝方案、剪枝特性使用方法、典型场景测试对比结果的详细呈现,剖析了“多表连接+DISTINCT”场景中,GaussDB(for MySQL)大幅提升查询效率的原因。如果对华为云GaussDB(for MySQL)更多功能感兴趣的话,可以查看官方产品文档,了解更多:https://support.huaweicloud.com/gaussdbformysql/index.html
GaussDB(for MySQL)剪枝功能,让查询性能提升70倍!的更多相关文章
- 查询性能提升3倍!Apache Hudi 查询优化了解下?
从 Hudi 0.10.0版本开始,我们很高兴推出在数据库领域中称为 Z-Order 和 Hilbert 空间填充曲线的高级数据布局优化技术的支持. 1. 背景 Amazon EMR 团队最近发表了一 ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- 查询效率提升10倍!3种优化方案,帮你解决MySQL深分页问题
开发经常遇到分页查询的需求,但是当翻页过多的时候,就会产生深分页,导致查询效率急剧下降. 有没有什么办法,能解决深分页的问题呢? 本文总结了三种优化方案,查询效率直接提升10倍,一起学习一下. 1. ...
- Web 应用性能提升 10 倍的 10 个建议
转载自http://blog.jobbole.com/94962/ 提升 Web 应用的性能变得越来越重要.线上经济活动的份额持续增长,当前发达世界中 5 % 的经济发生在互联网上(查看下面资源的统计 ...
- 重构、插件化、性能提升 20 倍,Apache DolphinScheduler 2.0 alpha 发布亮点太多!
点击上方 蓝字关注我们 社区的小伙伴们,好消息!经过 100 多位社区贡献者近 10 个月的共同努力,我们很高兴地宣布 Apache DolphinScheduler 2.0 alpha 发布.这是 ...
- 高性能mysql 第6章 查询性能优化
查询缓存: 在解析一个sql之前,如果查询缓存是打开的,mysql会去检查这个查询(根据sql的hash作为key)是否存在缓存中,如果命中的话,那么这个sql将会在解析,生成执行计划之前返回结果. ...
- 高性能mysql 第六章查询性能优化 总结(上)查询的执行过程
6 查询性能优化 6.1为什么查询会变慢 这里说明了的查询执行周期,从客户端到服务器端,服务器端解析,优化器生成执行计划,执行(可以细分,大体过程可以通过show profile查看),从服务器端返 ...
- 优化临时表使用,SQL语句性能提升100倍
[问题现象] 线上mysql数据库爆出一个慢查询,DBA观察发现,查询时服务器IO飙升,IO占用率达到100%, 执行时间长达7s左右.SQL语句如下:SELECT DISTINCT g.*, cp. ...
- 转--优化临时表使用,SQL语句性能提升100倍
转自:http://www.51testing.com/html/01/n-867201-2.html [问题现象] 线上mysql数据库爆出一个慢查询,DBA观察发现,查询时服务器IO飙升,IO占用 ...
- Nacos 2.0 正式发布,性能提升 10 倍!!
3月20号,Nacos 2.0.0 正式发布了! Nacos 简介: 一个更易于构建云原生应用的动态服务发现.配置管理和服务管理平台. 通俗点讲,Nacos 就是一把微服务双刃剑:注册中心 + 配置中 ...
随机推荐
- BBS项目(一): 表设计 注册功能 登录功能 生成随机验证码
目录 表设计 1.确定表的数量 2.确定表的基础字段 自关联字段 3.确定表的外键字段 表关系图 项目初建流程备忘 注册功能 登录功能 生成随机验证码 表设计 # 仿造博客园项目 核心:文章的增删改查 ...
- WPF Window无边框窗体阴影效果
WPF通过WindowChrome实现Window无边框窗体阴影效果 代码: <Window x:Class="SunCreate.PACP.Client.UI.GIS.CameraD ...
- Cpp 值的种类划分
本博文会介绍移动语义的形式术语和规则.并且会正式的介绍值的类别,如 lvalue.rvalue.prvalue和 xvalue,并讨论了在绑定对象引用时的作用.也会讨论移动语义不会自动传递的细节,以及 ...
- IDEA整合SSM框架:简易图书操作模块
这个SSM整合文章,以图书的增删改查为例 本篇文章源码已上传: Github:https://github.com/RivTian/University-coursework/tree/master/ ...
- mybatis-plus-QueryWrapper like的用法
mybatis-plus 中想写like的语句 一.直接用 QueryWrapper 中的 like String deptLevelCodeTemp = "1000010001" ...
- JVM简单概述
一.内存模型&分区 Java虚拟机在运行Java程序时,会管理着一块内存区域:运行时数据区 在运行时数据区里,会根据用途进行划分为以下模块: 1.Java虚拟机栈 2.本地方法栈 3.Java ...
- Java 内存管理最佳实践
本文翻译自国外论坛 medium,原文地址:https://medium.com/@fullstacktips/best-practices-for-memory-management-in-java ...
- sipp3.6多方案压测脚本
概述 SIP压测工具sipp,免费,开源,功能足够强大,配置灵活,优点多. 有时候我们需要模拟现网的生产环境来压测,就需要同时有多个sipp脚本运行,并且需要不断的调整呼叫并发. 通过python脚本 ...
- freeswitch服务器的时间同步设置
概述 在生产环境中,一般会有N台freeswitch 服务器,不同服务器之间的信令和话单的时间不能相差太多,否则对查找和定位问题会造成一定的困扰. 同时,freeswitch的默认运行设置并未直接使用 ...
- C#单向链表的实现
节点 public class ListNode { public ListNode(int NewValue) { Value = NewValue; } //前一个 public ListNode ...