深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM
深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM
1.Learning to Learn
Learning to Learn by Gradient Descent by Gradient Descent
提出了一种全新的优化策略,
用 LSTM 替代传统优化方法学习一个针对特定任务的优化器。
在机器学习中,通常把优化目标 $f(\theta)$ 表示成
$$
\theta^{*}=\operatorname{argmin}_{\theta \in \Theta} f(\theta)
$$
其中,参数 $\theta$ 的优化方式为
$$
\theta_{t+1}=\theta_{t}-\alpha \nabla f\left(\theta_{t}\right)
$$
上式是一种针对特定问题类别的、人为设定的更新规则,
常见于深度学习中,主要解决高维、非凸优化问题。
根据 No Free Lunch Theorems for Optimization 理论,
[1] 提出了一种 基于学习的更新策略 代替 人为设定的更新策略,
即,用一个可学习的梯度更新规则,替代人为设计的梯度更新规则。
其中,
optimizer 为 $g$ 由 $\phi$ 参数化;
optimizee 为 $f$ 由 $\theta$ 参数化。
此时, optimizee 的参数更新方式为
$$
\theta_{t+1}=\theta_{t}+g_{t}\left(\nabla f\left(\theta_{t}\right), \phi\right)
$$
optimizer $g$ 的更新则由 $f$, $\nabla f$ 及 $\phi$ 决定。
1.2 学习机制
图1是 Learning to Learn 中 optimizer 和 optimizee 的工作原理。
图1 Learning to Learn 中 optimizer 和 optimizee 工作原理。
optimizer 为 optimizee 提供更新策略,
optimizee 将损失信息反馈给 optimizer,协助 optimizer 更新。
给定目标函数 $f$ 的分布,那么经过 $T$ 次优化的 optimizer 的损失定义为整个优化过程损失的加权和:
$$
\mathcal{L}(\phi)=\mathbb{E}{f}\left[\sum^{T} \omega_{t} f\left(\theta_{t}\right)\right]
$$
其中,
$$
\begin{aligned}
& \theta_{t+1}=\theta_{t}+g_{t} \
& {\left[g_{t}, h_{t+1}\right]=\operatorname{LSTM}\left(\nabla_{t}, h_{t}, \phi\right)}
\end{aligned}
$$
$\omega_{t} \in \mathbb{R}{\geq 0}$ 是各个优化时刻的任意权重,
$\nabla=\nabla_{\theta} f\left(\theta_{t}\right)$ 。
图2是 Learning to Learn 计算图。
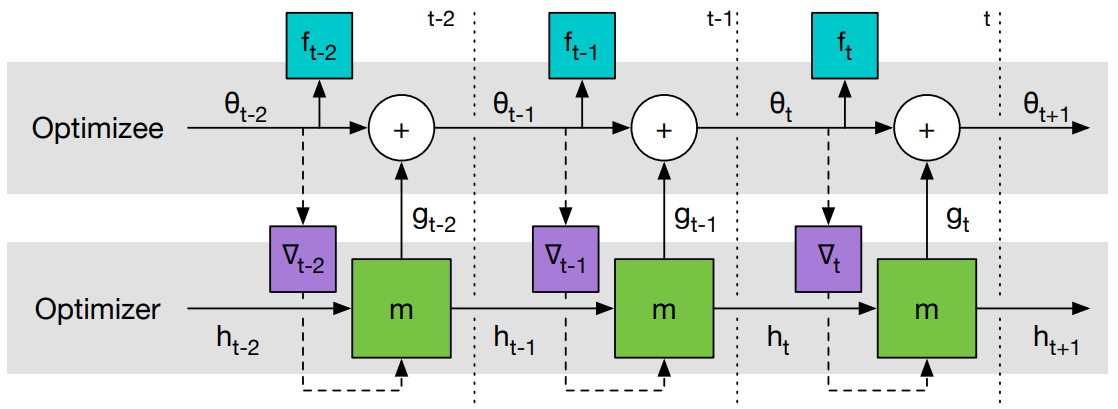
图1 Learning to Learn 计算图。
梯度只沿实线传递,不沿虚线传递(因为 optimizee 的梯度不依赖于 optimizer 的参数,即
$\partial \nabla_{t} / \partial \phi = 0$ ),这样可以避免计算 $f$ 的二阶导。
[1] 中 optimizer 选用了 LSTM 。
从 LSTM 优化器的设计来看,
几乎没有加入任何先验的人为经验。
优化器本身的参数 $\phi$ 即 LSTM 的参数,
这个优化器的参数代表了更新策略。
1.2 Coordinatewise LSTM optimizer
LSTM 需要优化的参数相对较多。
因此,[1] 设计了一个优化器 $m$,它可以对目标函数的每个参数分量进行操作。
具体而言,每次只对 optimizee 的一个参数分量 $\theta_{i}$ 进行优化,
这样只需要维持一个很小的 optimizer 就可以完成工作。
对于每个参数分量 $\theta_{i}$ ,
optimizer 的参数 $\phi$ 共享,隐层状态 $h_{i}$ 不共享。
由于每个维度上的 optimizer 输入的 $h_{i}$ 和 $\nabla f\left(\theta_{i}\right)$ 是不同的,
所以即使它们的 $\phi$ 相同,它们的输出也不一样。
这样设计的 LSTM 变相实现了优化与维度无关,
这与 RMSprop 和 ADAM 的优化方式类似(为每个维度的参数施行同样的梯度更新规则)。
图3是 LSTM 优化器的一步更新过程。
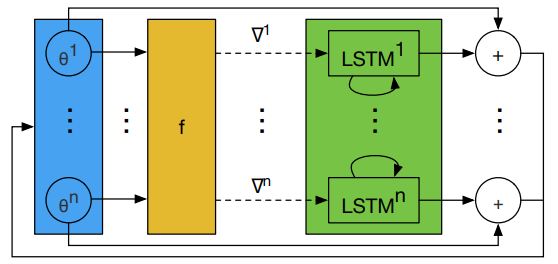
图3 LSTM 优化器的一步更新过程。所有 LSTM 的 $\phi$ 共享,$h_{i}$ 不共享。
1.3 预处理和后处理
由于 optimizer 的输入是梯度,梯度的幅值变化相对较大,
而神经网络一般只对小范围的输入输出鲁棒,因此在实践中需要对 LSTM 的输入输出进行处理。
[1] 采用如下的方式:
$$
\nabla^{k} \rightarrow \begin{cases}\left(\frac{\log (|\nabla|)}{p}, \operatorname{sgn}(\nabla)\right) & \text { if }|\nabla| \geq e^{-p} \ \left(-1, e^{p} \nabla\right) & \text { otherwise }\end{cases}
$$
其中, $p>0$ 为任意一个参数([1] 取 $p=10$),用来裁剪梯度。
如果第一个参数的取值大于 $-1$ ,
那么它就代表梯度的 $\log$ ,第二个参数则是它的符号。
如果第一个参数的取值等于 $-1$ ,
那么它将作为一个标记指引神经网络寻找第二个参数,此时第二个参数就是对梯度的缩放。
- 参考文献
[1] Learning to Learn by Gradient Descent by Gradient Descent
2. Meta-Learner LSTM
元学习在处理 few-shot 问题时的学习机制如下:
基学习器在元学习器的引导下处理特定任务,发现任务特性;
元学习器总结所有任务共性。
基于小样本的梯度下降存在以下问题:
小样本意味着梯度下降的次数有限,在非凸的情况下,得到的模型必然性能很差;
对于每个单独的数据集,神经网络每次都是随机初始化,若干次迭代后也很难收敛到最佳性能。
因此,元学习可以为基于小样本的梯度下降提供一种提高模型泛化性能的策略。
Meta-Learner LSTM 使用单元状态表示 Learner 参数的更新。
训练 Meta-Learner 既能发现一个良好的 Learner 初始化参数,
又能将 Learner 的参数更新到一个给定的小训练集,以完成一些新任务。
2.1 Meta-Learner LSTM
2.1.1 梯度下降更新规则和 LSTM 单元状态更新规则的等价性
一般的梯度下降更新规则
$$
\theta_{t}=\theta_{t-1}-\alpha_{t} \nabla_{\theta_{t-1}} L_{t}
$$
其中,$\theta_{t}$ 是第 $t$ 次迭代更新时的参数值,$\alpha_{t}$ 是第 $t$ 次迭代更新时的学习率,$\nabla_{\theta_{t-1}} L_{t}$ 是损失函数在 $\theta_{t-1}$ 处的梯度值。
LSTM 单元状态更新规则
$$
c_{t}=f_{t} \cdot c_{t-1}+i_{t} \cdot \tilde{c}_{t}
$$
其中,$c_{t}$ 是 $t$ 时刻的细胞状态,$f_{t}\in[0,1]$ 是遗忘门,$i_{t}\in[0, 1]$ 是输入门。
当 $f_{t}=1,\ c_{t-1}=\theta_{t-1},\ i_{t}=\alpha_{t},\ \tilde{c}{t}=-\nabla{\theta_{t-1}} L_{t}$ 时,$\mathrm{Eq.\ (1)=Eq.\ (2)}$ 。
经过这样的替换,利用 LSTM 的状态更新替换学习器参数 $\theta$。
2.1.2 Meta-Learner LSTM 设计思路
Meta-Learner 的目标是学习 LSTM 的更新规则,并将其应用于更新 Learner 的参数上。
(1) 输入门
$$
\begin{align}
i_{t}=\sigma\left({W}{I} \cdot\left[\nabla{\theta_{t-1}} L_{t}, L_{t}, {\theta}{t-1}, i\right]+{b}_{I}\right)
\end{align}
$$
其中,$W$ 是权重矩阵;$b$ 是偏差向量;$\sigma$ 是 Sigmoid 函数;
$\nabla_{\theta_{t-1}} L_{t}$ 和 $L_{t}$ 由 Learner 输入 Meta-Learner。
对于输入门参数 $i_t$ ,它的作用相当于学习率 $\alpha$ ,
在此学习率是一个关于 $\nabla_{\theta_{t-1}} L_{t}$ , $L_{t}$ ,${\theta}{t-1}$ ,$i$ 的函数。
(2) 遗忘门
$$
\begin{align}
f_{t}=\sigma\left(W_{F} \cdot\left[\nabla_{\theta_{t-1}} L_{t}, L_{t}, \theta_{t-1}, f_{t-1}\right]+b_{F}\right)
\end{align}
$$
对于遗忘门参数 $f_t$ ,它代表着 $\theta_{t-1}$ 所占的权重,这里将其固定为 1 ,但 1 不一定是它的最优值。
(3) 将学习单元初始状态 $c_0$ 视为 Meta-Learner 的一个参数,
正对应于 learner 的参数初始值。
这样当来一个新任务时, Meta-Learner 能给出一个较好的初始化值,从而进行快速学习。
(4) 参数共享
为了避免 Meta-Learner 发生参数爆炸,在 Learner 梯度的每一个 coordinate 上进行参数共享。
每一个 coordinate 都有自己的单元状态,但是所有 coordinate 在 LSTM 上的参数都是一样的。
每一个 coordinate 就相当于 Learner 中的每一层,
即对于相同一层的参数 $\theta_i$ ,
它们的更新规则是一样的,即 $W_I$ , $b_I$ , $W_I$ , $b_I$ 是相同的。
2.2 Meta-Learner LSTM 单元状态更新过程
将 LSTM 单元状态更新过程作为随机梯度下降法的近似,实现 Meta-Learner 对 Leraner 参数更新的指导。
(1) 候选单元状态:$\tilde{c}{t}=-\nabla{\theta_{t-1}} L_{t}$,是 Meta-Learner 从 Leraner 得到的损失函数梯度值,直接输入 Meta-Learner ,作为 $t$ 时刻的候选单元状态。
(2) 上一时刻的单元状态:$c_{t-1}=\theta_{t-1}$,是 Learner 用第 $t-1$ 个批次训练数据更新后的参数。每个批次的数据训练完后,Leraner 将损失函数值和损失函数梯度值输入 Meta-Learner,Meta-Learner 更新一次参数,将更新后的参数回馈给 Leraner,Leraner 继续处理下一个批次的训练数据。
(3) 更新的单元状态:$c_{t}=\theta_{t}$,是 Learner 用第 $t$ 个批次训练数据更新后的参数。
(4) 输出门:不考虑。
(5) 初始单元状态:$c_{0}=\theta$,是 Learner 最早的参数初始值。LSTM 模型需要找到最好的初始细胞状态,使得每轮更新后的参数初始值更好地反映任务的共性,在 Learner 上只需要少量更新,就可以达到不错的精度。
2.3 Meta-Learner LSTM 算法流程
Meta-Learner LSTM 前向传递计算如图1所示,其中,
基学习器 $\mathrm{M}$,包含可训练参数 $\theta$;元学习器 $R$,包含可训练参数 $\Theta$。
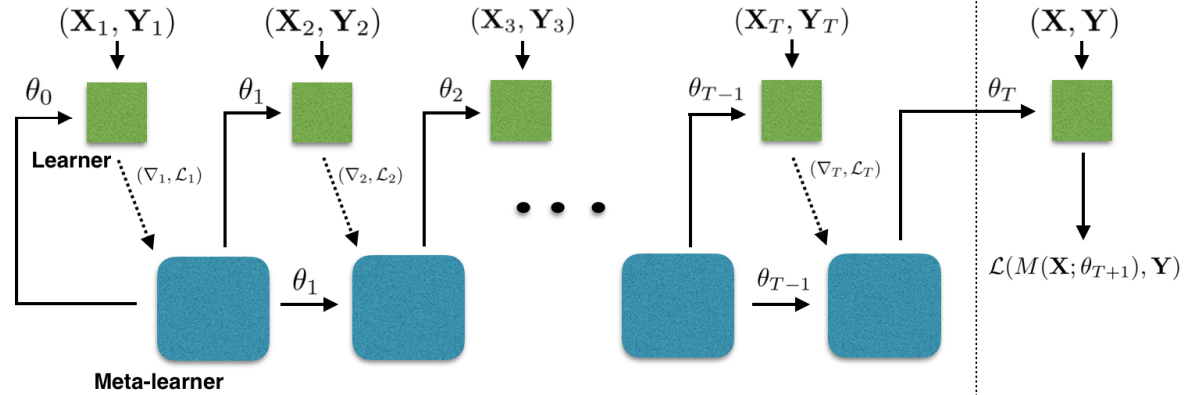
图1 Meta-Learner LSTM 前向传递计算图。
Learner 计算损失函数值和损失函数梯度值,
Meta-Learner 使用 Learner 提供的信息,更新 Learner 中的参数和自身参数。
在任务中,每个批次的训练数据处理完成后,Meta-Learner 为 Learner 更新一次参数,
任务中所有批次的训练数据处理完成后,Meta-Learner 进行一次更新。
Meta-Learner LSTM 算法流程
$\Theta_{0}$ $\leftarrow$ random initialization
for $d=1,...,n$ do:
$D_{\mathrm{train}}$, $D_{\mathrm{test}}$ $\leftarrow$ random dataset from ${D}_{\mathrm{meta-train}}$
intialize learner parameters: $\theta_{0} \leftarrow c_{0}$
for $t=1,...,T$ do:
- $\mathbf{X}{t}$, $\mathbf{Y}$ $\leftarrow$ random batch from $D_{\mathrm{train}}$
- get loss of learner on train batch: $\mathcal{L}{t} \leftarrow \mathcal{L}\left(M\left(\mathbf{X} ; \theta_{t-1}\right), \mathbf{Y}_{t}\right)$
- get output of meta-learner using Eq. (2): $c_{t} \leftarrow R\left(\left(\nabla_{\theta_{t-1}} \mathcal{L}{t}, \mathcal{L}\right) ; \Theta_{d-1}\right)$
- update learner parameters: $\theta_{t} \leftarrow c_{t}$
end for
$\mathbf{X}, \mathbf{Y} \leftarrow D_{\mathrm{test}}$
get loss of learner on test batch: ${L}\mathrm{test} \leftarrow {L}\left(M\left(\mathbf{X} ; \theta\right), \mathbf{Y}\right)$
update $\Theta_{d}$ using $\nabla_{\Theta_{d-1}} {L}_{\mathrm{test}}$
end for
对于第 $d$ 个任务,在训练集中随机抽取 $T$ 个批次的数据,记为 $\left(\boldsymbol{X}{1}, \boldsymbol{Y}\right), \cdots, \left(\boldsymbol{X}{T}, \boldsymbol{Y}\right)$。
对于第 $t$ 个批次的数据 $\left(\boldsymbol{X}{t}, \boldsymbol{Y}\right)$,计算 learner 的损失函数值 $L_{t}=L\left[M\left(X_{t}; \theta_{t-1}\right), Y_{t}\right]$ 和损失函数梯度值 $\nabla_{\theta_{t-1}} L_{t}$,将损失函数和损失函数梯度输入 meta-learner ,更新细胞状态:${c}{t}=\boldsymbol{R}\left[\left(\nabla{\theta_{t-1}} L_{t}, L_{t}\right); \Theta_{d-1}\right]$,更新的参数值等于更新的细胞状态 $\theta_{t}=c_{t}$。
处理完第 $d$ 个任务中所有 $T$ 个批次的训练数据后,使用第 $d$ 个任务的验证集 $(X, Y)$, 计算验证集上的损失函数值 $L_{\mathrm{test}}=L\left[M\left(X; \theta_{T}\right), Y\right]$ 和损失函数梯度值 $\nabla_{\theta_{d-1}} L_{\mathrm{test}}$ ,更新 meta-learner 参数 $\boldsymbol{\Theta}_{d}$ 。
2.4 Meta-Learner LSTM 模型结构
Meta-Learner LSTM 是一个两层的 LSTM 网络,第一层是正常的 LSTM 模型,第二层是近似随机梯度的 LSTM 模型。
所有的损失函数值和损失函数梯度值经过预处理,输入第一层 LSTM 中,
计算学习率和遗忘门等参数,损失函数梯度值还要输入第二层 LSTM 中用于参数更新。
2.5 Meta-Learner LSTM 和 MAML 的区别
在 MAML 中,元学习器给基学习器提供参数初始值,基学习器给元学习器提供损失函数值;
在 Meta-Learner LSTM 中,元学习器给基学习器提供更新的参数,基学习器给元学习器提供每个批次数据上的损失函数值和损失函数梯度值。在 MAML 中,基学习器的参数更新在基学习器中进行,元学习器的参数更新在元学习器中进行;
在 Meta-Learner LSTM 中,基学习器和元学习器的参数更新都在元学习器中进行。在 MAML 中,元学习器使用 SGD 更新参数初始值,使得损失函数中存在高阶导数;
在 Meta-Learner LSTM 中,元学习器给基学习器提供修改的 LSTM 更新参数,元学习器自身的参数并不是基学习器中的参数初始值,元学习器自身的参数使用 SGD 进行更新,并不会出现损失函数高阶导数的计算。在 MAML 中,元学习器和基学习器只在每个任务训练完成后才进行信息交流;
在 Meta-Learner LSTM 中,元学习器和基学习器在每个任务的每个批次训练数据完成后就进行信息交流。MAML 适用于任意模型结构;
Meta-Learner LSTM 中的元学习器只能是 LSTM 结构,基学习器可以适用于任意模型结构。
2.6 Meta-Learner LSTM 分类结果
表1 Meta-Learner LSTM 在 miniImageNet 上的分类结果。
| Method | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| Baseline-finetune | 28.86 $\pm$ 0.54 $%$ | 49.79 $\pm$ 0.79 $%$ |
| Baseline-nearest-neighbor | 41.08 $\pm$ 0.70 $%$ | 51.04 $\pm$ 0.65 $%$ |
| Matching Network | 43.40 $\pm$ 0.78 $%$ | 51.09 $\pm$ 0.71 $%$ |
| Matching Network FCE | 43.56 $\pm$ 0.84 $%$ | 55.31 $\pm$ 0.73 $%$ |
| Meta-Learner LSTM | 43.44 $\pm$ 0.77 $%$ | 60.60 $\pm$ 0.71 $%$ |
- 参考文献
[1] Optimization as a Model for Few-Shot Learning
[2] 长短时记忆网络 LSTM
更多优质内容请关注公号:汀丶人工智能

深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM的更多相关文章
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 伯克利、OpenAI等提出基于模型的元策略优化强化学习
基于模型的强化学习方法数据效率高,前景可观.本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能. 引言 强化学习领域近期 ...
- 强化学习之五:基于模型的强化学习(Model-based RL)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- Linux学习初级篇-鸟哥的Linux私房菜 基础学习篇(第四版)
0.1.2 一切设计的起点:CPU的架构 由于CPU的内部是有一些微指令组成的,所以我们所使用的软件都是要经过CPU内部的微指令集来达成才行.那这些指令集的设计主要又被分为两种设计理念,这是目前世界上 ...
- 从.Net到Java学习第一篇——开篇
以前我常说,公司用什么技术我就学什么.可是对于java,我曾经一度以为“学java是不可能的,这辈子不可能学java的.”结果,一遇到公司转java,我就不得不跑路了,于是乎,回头一看N家公司交过社保 ...
- CTR学习笔记&代码实现5-深度ctr模型 DeepCrossing -> DCN
之前总结了PNN,NFM,AFM这类两两向量乘积的方式,这一节我们换新的思路来看特征交互.DeepCrossing是最早在CTR模型中使用ResNet的前辈,DCN在ResNet上进一步创新,为高阶特 ...
- CTR学习笔记&代码实现6-深度ctr模型 后浪 xDeepFM/FiBiNET
xDeepFM用改良的DCN替代了DeepFM的FM部分来学习组合特征信息,而FiBiNET则是应用SENET加入了特征权重比NFM,AFM更进了一步.在看两个model前建议对DeepFM, Dee ...
- 深度学习实战篇-基于RNN的中文分词探索
深度学习实战篇-基于RNN的中文分词探索 近年来,深度学习在人工智能的多个领域取得了显著成绩.微软使用的152层深度神经网络在ImageNet的比赛上斩获多项第一,同时在图像识别中超过了人类的识别水平 ...
- 深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全
深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全 原文地址:Image Completion with Deep Learning in TensorFlow by Bra ...
- [源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Worker生命周期
[源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Worker生命周期 目录 [源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Work ...
随机推荐
- 【django-vue】登录注册模态框分析 登录注册前端页面 腾讯短信功能二次封装 短信验证码接口 短信登录接口 短信注册接口
目录 昨日回顾 csrf跨站请求伪造 接口幂等性 异常捕获 今日内容 1 登录注册模态框分析 Login.vue Header.vue 2 登录注册前端页面复制 2.0 Header.vue 2.1 ...
- Go--gjson
GJSON 是一个用于处理 JSON 数据的 Go 语言库.它提供了一些方便的功能,例如解析 JSON 字符串.查询 JSON 对象.生成 JSON 对象等 下载gjson: go get -u gi ...
- 可用性库存(CO09)排除库存地点增强
1.业务需求 1.1.业务背景 1.2.对应方案: 2.测试BAPI 首先运行事务代码CO09,查看结果 运行BAPI_MATERIAL_AVAILABILITY 3.增强实现 3.1.增强思路 3. ...
- SCA技术进阶系列(一):SBOM应用实践初探
现代软件都是组装的而非纯自研.随着开源组件在数字化应用中的使用比例越来越高,混源开发已成为当前业内主流开发方式.开源组件的引入虽然加快了软件开发效率,但同时将开源安全问题引入了整个软件供应链.软件组成 ...
- S3C2440移植uboot之裁剪和修改默认参数
上一节S3C2440移植uboot之支持DM9000移植uboot支持了网卡驱动,这节裁剪和修改uboot默认参数 目录 uboot的环境参数 修改uboot的默认环境变量 查看 default_ ...
- 01-Shell脚本入门
1.Shell介绍 1.1 疑问 linux系统是如何操作计算机硬件CPU,内存,磁盘,显示器等? 答: 使用linux的内核操作计算机的硬件 1.2 Shell介绍 通过编写Shell命令发送给li ...
- 【MicroPython】 mp对象和 c 类型的转换
[来源]https://www.eemaker.com/micropython-mp-toc.html
- JMS微服务开发示例(八)双机热备
双机热备,指两个一模一样的微服务,两个同时在运行,但是只有一个在工作,当工作中的微服务垮掉后,另一个会自行补上. 要实现这个,只需要设置 SingletonService = true. var mi ...
- [转帖]Nginx - 根据IP分配不同的访问后端
https://www.cnblogs.com/hukey/p/11868017.html 1. 需求分析 为了在线上环境提供测试分支,规定将某IP转发到测试程序地址.如果是 ngx 直接对外,采用 ...
- [转帖]prometheus node-exporter 全部指标说明
https://www.cnblogs.com/276815076/p/16383615.html Basic CPU / Mem / Disk Info Basic CPU / Mem / Disk ...