六、Doris数据流与控制流
目录:
- 数据查询
- 数据导入
- 元数据修改
1、查询
用户可使用MySQL客户端连接FE,执行SQL查询, 获得结果,查询流程如下:
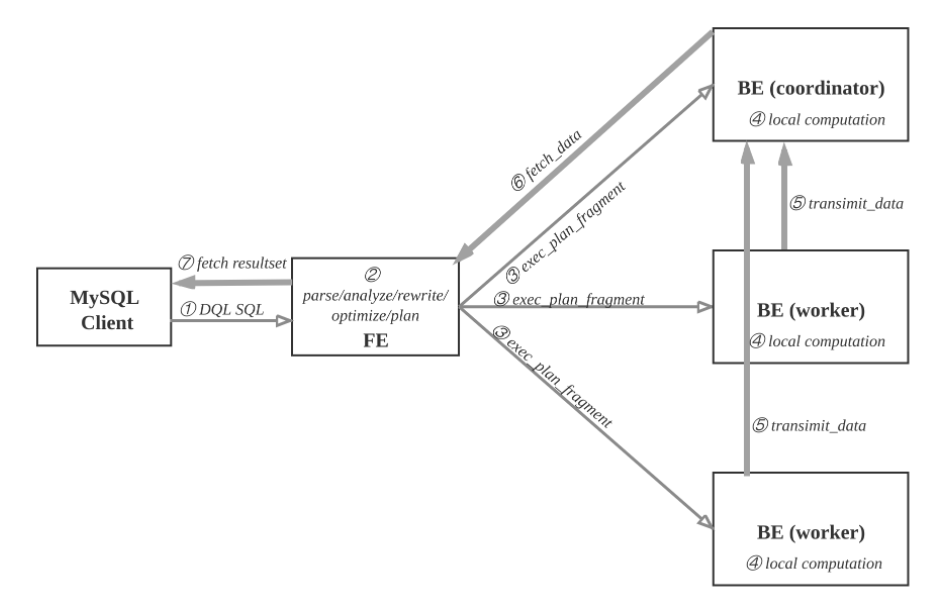
分步说明:
- ① MySQL客户端执行DQL SQL命令。
- ② FE解析, 分析, 改写, 优化和规划, 生成分布式执行计划。
- ③ 分布式执行计划由 若干个可在单台be上执行的plan fragment构成, FE执行exec_plan_fragment, 将plan fragment分发给BE,并指定其中一台BE为coordinator。
- ④ BE执行本地计算, 比如扫描数据。
- ⑤ 其他BE调用transimit_data将中间结果发送给BE coordinator节点汇总为最终结果。
- ⑥ FE调用fetch_data获取最终结果。
- ⑦ FE将最终结果发送给MySQL client。
执行计划在BE上的实际执行过程比较复杂, 采用向量化执行方式,比如一个算子产生4096个结果,输出到下一个算子参与计算,而非batch方式或者one-tuple-at-a-time。
数据导入
用户创建表之后, 导入数据填充表
- 支持导入数据源有: 本地文件, HDFS, Kafka和S3
- 支持导入方式有: 批量导入, 流式导入
- 支持的数据格式有: CSV, Parquet, ORC等.
- 导入发起方式有: 用RESTful接口, 执行SQL命令.
数据导入的流程图:
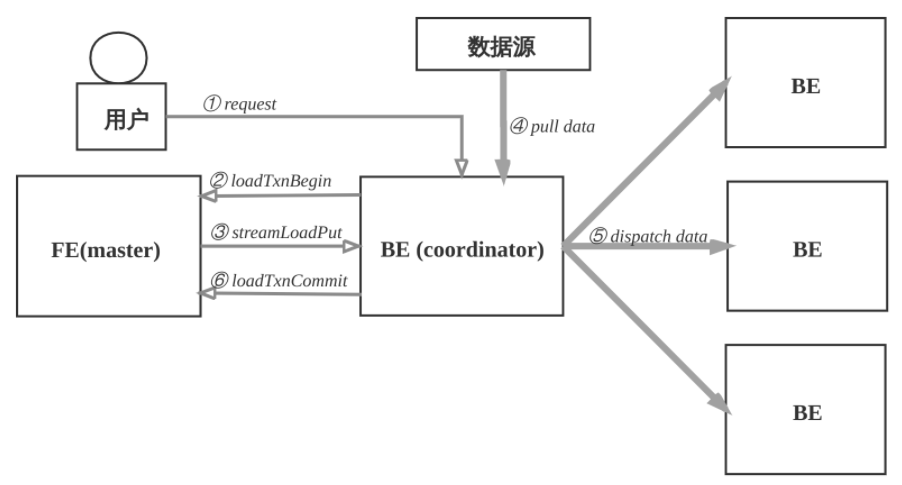
分步解释:
- ① 用户选择一台BE作为协调者, 发起数据导入请求, 传入数据格式, 数据源和标识此次数据导入的label, label用于避免数据重复导入. 用户也可以向FE发起请求, FE会把请求重定向给BE.
- ② BE收到请求后, 向FE master节点上报, 执行loadTxnBegin, 创建全局事务。 因为导入过程中, 需要同时更新base表和物化索引的多个bucket, 为了保证数据导入的一致性, 用事务控制本次导入的原子性.
- ③ BE创建事务成功后, 执行streamLoadPut调用, 从FE获得本次数据导入的计划. 数据导入, 可以看成是将数据分发到所涉及的全部的tablet副本上, BE从FE获取的导入计划包含数据的schema信息和tablet副本信息.
- ④ BE从数据源拉取数据, 根据base表和物化索引表的schema信息, 构造内部数据格式.
- ⑤ BE根据分区分桶的规则和副本位置信息, 将发往同一个BE的数据, 批量打包, 发送给BE, BE收到数据后, 将数据写入到对应的tablet副本中.
- ⑥ 当BE coordinator节点完成此次数据导入, 向FE master节点执行loadTxnCommit, 提交全局事务, 发送本次数据导入的 执行情况, FE master确认所有涉及的tablet的多数副本都成功完成, 则发布本次数据导入使数据对外可见, 否则, 导入失败, 数据不可见, 后台负责清理掉不一致的数据.
3、更改元数据
更改元数据的操作有: 创建数据库, 创建表, 创建物化视图, 修改schema等等. 这样的操作需要:
- 持久化到永久存储的设备上;
- 保证高可用, 复制FE多实例上, 避免单点故障;
- 有的操作需要在BE上生效, 比如创建表时, 需要在BE上创建tablet副本.
元数据的更新操作流程如下:
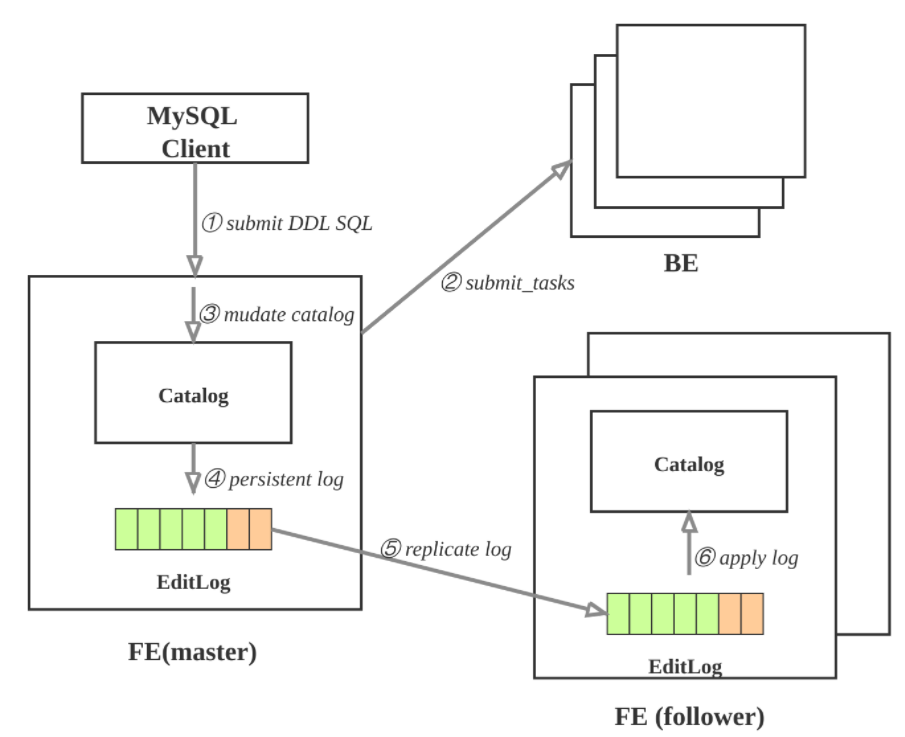
分步解释:
- ① 用户使用MySQL client执行SQL的DDL命令, 向FE的master节点发起请求; 比如: 创建表.
- ② FE检查请求合法性, 然后向BE发起同步命令, 使操作在BE上生效; 比如: FE确定表的列类型是否合法, 计算tablet的副本的放置位置, 向BE发起请求, 创建tablet副本.
- ③ BE执行成功, 则修改内存的Catalog. 比如: 将table, partition, index, tablet的副本信息保存在Catalog中.
- ④ FE追加本次操作到EditLog并且持久化.
- ⑤ FE通过复制协议将EditLog的新增操作项同步到FE的follower节点.
- ⑥ FE的follower节点收到新追加的操作项后, 在自己的Catalog上按顺序播放, 使得自己状态追上FE master节点.
上述执行环节出现失败, 则本次元数据修改失败.
参考:
六、Doris数据流与控制流的更多相关文章
- 软件测试技术(六)——白盒测试之控制流覆盖准则+Visual Studio 2013单元测试
一.目标程序 单片机发送的A/D转换结果的整体格式为:[DLE][STX]Message[CHKSUM][DLE][ETX],其中[]括号中的字符为16进制的助记符,并非ASCII码.其中:[DLE] ...
- SSIS的控制流之For循环容器
SSIS包由一个控制流以及一个或多个数据流(可选)组成.下面的关系图显示具有一个容器和六项任务的控制流. 这些任务中有五项定义于包级别,还有一项定义于容器级别.任务位于容器内.在控制流中的工具箱.我们 ...
- Linux2.6.11版本:classic RCU的实现
转载自:http://www.wowotech.net/kernel_synchronization/linux2-6-11-RCU.html 一.前言 无论你愿意或者不愿意,linux kernel ...
- 【JVM】JVM系列之类加载机制(四)
一.前言 前面分析了class文件具体含义,接着需要将class文件加载到虚拟机中,这个过程是怎样的呢,下面,我们来仔细分析. 二.什么是类加载机制 把class文件加载到内存,并对数据进行校验.转换 ...
- Linux 概念架构的理解
摘要 Linux kernel 成功的两个原因: 架构设计支持大量的志愿开发者加入到开发过程中: 每个子系统,尤其是那些需要改进的,都支持很好的扩展性. 正是这两个原因使得 Linux kernel ...
- 【转】Linux 概念架构的理解
转:http://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=400583492&idx=1&sn=3b18c463dcc451 ...
- 深入JVM系列(三)之类加载、类加载器、双亲委派机制与常见问题
一.概述 定义:虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的java类型.类加载和连接的过程都是在运行期间完成的. 二. 类的 ...
- (转)Linux概念架构的理解
英文原文:Conceptual Architecture of the Linux Kernel 摘要 Linux kernel成功的两个原因:(1)架构设计支持大量的志愿开发者加入到开发过程中:(2 ...
- Linux概念架构的理解
摘要 Linux kernel成功的两个原因:(1)架构设计支持大量的志愿开发者加入到开发过程中:(2)每个子系统,尤其是那些需要改进的,都支持很好的扩展性.正式这两个原因使得Linux kernel ...
- 软件测试software testing summarize
软件测试(英语:software testing),描述一种用来促进鉴定软件的正确性.完整性.安全性和质量的过程.软件测试的经典定义是:在规定的条件下对程序进行操作,以发现程序错误,衡量软件质量,并对 ...
随机推荐
- quartus之ram的IP测试
quartus之ram的IP测试 1.基本原理 ram,读取存储器,用于储存数据.基本的原理就是使用时钟驱动时序,利用地址区分位置,使用使能控制写入.输出的结果以写入的位宽输出. 2.实际操作 顶层代 ...
- redis安装启动脚本
#!/bin/bash # sudo yum install -y gcc # sudo yum install -y ruby build-essential BASE=/usr/local ps ...
- C++设计模式 - 策略模式(Strategy)
组件协作模式: 现代软件专业分工之后的第一个结果是"框架与应用程序的划分","组件协作"模式通过晚期绑定,来实现框架与应用程序之间的松耦合,是二者之间协作时常用 ...
- 基于文件语义实现S3接口语义的注意事项
本文标题中提到的文件语义,指的是POSIX规范. S3指的是AWS提供的对象存储服务以及相关接口.为方便描述,下文中以对象语义替代S3接口语义. 文件语义和对象语义存在比较多的差异. 对象语义不支持文 ...
- Java中的类型推断和lambda表达式
目录 简介 类型的显示使用 Stream中的类型推断 类型推断中变量名字的重要性 类型推断对性能的影响 类型推断的限制 总结 简介 java是强类型的编程语言,每个java中使用到的变量都需要定义它的 ...
- K8s技术全景:架构、应用与优化
本文深入探讨了Kubernetes(K8s)的关键方面,包括其架构.容器编排.网络与存储管理.安全与合规.高可用性.灾难恢复以及监控与日志系统. 关注[TechLeadCloud],分享互联网架构.云 ...
- 掌握 C++ 中 static 关键字的多种使用场景
static是什么 在最开始C中引入了static关键字可以用于修饰变量和函数,后来由于C++引入了class的概念,现在static可以修饰的对象分为以下5种: 成员变量,成员函数,普通函数,局部变 ...
- unknow or unsupported command install
错误原因: 今天使用pip下载labelimg时,出现了"unknow or unsupported command install"的错误,这是由于电脑有多个pip文件路径所导致 ...
- Jenkins首次启动慢
场景描述启动Jenkins后,打开网站,发现一直卡在这个启动页面,慢,很慢,非常慢 解决方法 进入Jenkins的安装目录,找到"hudson.model.UpdateCenter.xml& ...
- 抓包整理————tcp 三次握手[九]
前言 简单抓包一下3次握手. 正文 握手的目标: 同步sequence 序列化 初始化序列化ISN(Initial Sequence Number) 交换tcp 通信参数 如MSS.窗口比例因子.选择 ...