主流开源分布式图计算框架 Benchmark
本文由美团 NLP 团队高辰、赵登昌撰写,首发于 Nebula Graph Community 公众号

{kind=link}
- 前言
随着近年来数据的爆炸式增长,如何高效地分析处理数据,在业界一直备受关注。现实世界中的数据往往数量庞大且关系复杂,这些数据中不同个体间彼此交互产生的数据以图的形式表现最为自然。比如微信的社交网络,是由节点(个人、公众号)和边(关注、点赞)构成的图;淘宝的交易网络,是由节点(个人、商品)和边(购买、收藏)构成的图。
图计算正是研究事物之间的关系,并对其进行完整的刻画、计算和分析的一门技术。目前,已经有不少公司将图计算技术应用到了自己的业务场景中(如京东金融的小额借贷业务,搜狗搜索的搜索排序系统、工商银行的信用卡反欺诈系统等),取得了远超传统计算的效果。
而美团内部在骑手社交网络、金融反欺诈、设备风险识别等诸多场景下也有使用图计算的迫切需求。
图计算技术可以很好地解决全图的离线分析问题,但目前在工程落地上依然存在困难。图计算中存在数据稀疏、顶点幂律分布、活跃顶点集动态变化、并行通信开销大等问题,并不天然具备良好的并行扩展能力,设计不良的图计算框架性能甚至不如单机。
为了满足美团业务方的超大规模图计算需求,需要选出一款图计算框架,作为图计算平台的底层引擎。我们结合业务现状,制定了选型的基本条件:
开源项目,团队必须拥有对源代码的控制力,才能保证数据安全和服务可用性。
分布式架构,具备良好的可扩展性。
能够服务 OLAP 场景,高性能产出图分析结果。
通用的图计算系统,能提供多种流行的图算法,且能方便地定制开发新算法,以应对多种业务应用场景。
经过广泛的调研后,我们列举一些有代表性的图计算框架如下:
Neo4j-APOC :在图数据库的基础上,支持一些基本图算法,分布式版本不开源。
Pregel:Google 在 2009 年提出,是图计算模型的开山祖师,后续很多工作都受到它的思想影响。不开源。
Giraph:Facebook 基于 Pregel 思想的开源实现。
Gemini:清华大学基于 Pregel 思想进行了多项改进的实现,性能优秀。仅提供免费 Demo,商业版不开源。
KnightKing:针对 Walker 游走类算法专门设计的图计算框架,不具有通用性。
GraphX:Apache 基金会基于 Spark 实现的图计算框架,社区活跃度较高。
GraphLab(PowerGraph):商业软件,不开源。已被苹果收购。
Plato:腾讯基于 Gemini 和 KnightKing 思想的 C++ 开源实现,是一款高性能、可扩展、易插拔的图计算框架。
按照选型的基本条件进行筛选,最终纳入评测范围的框架为:GraphX、Giraph、Plato。
- 测试概要
2.1 硬件配置
物理机配置
CPU:48核(Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz)
内存:192GB
硬盘:5,587GB
实例数量:同机房 4 台
2.2 部署方案
2.2.1 GraphX
系统版本:3.1.2
Spark 版本:3.1.2
GraphX 基于 Spark 平台执行算法,每个实例上需要预先启动 1 个 worker(Spark 的配置参数可参看附录 5.1.1)。
2.2.2 Giraph
系统版本:1.3.0
Spark 版本:2.7.6
Giraph 依赖 MapReduce 来启动 Job,各实例需要预先按如下方式部署(Hadoop 配置参数可参看附录 5.2.1)。

2.2.3 Plato
系统版本:0.1.1
Plato 在发起算法执行前,会通过 Hydra 为每个实例启动 1 个进程。
2.3 评测数据集
我们使用不同数据量级的 2 个图数据集进行评测:分别是Twitter 社交关注关系数据集(twitter-2010:https://law.di.unimi.it/webdata/twitter-2010/ )和网页链接关系数据集(clueweb-12:https://law.di.unimi.it/webdata/clueweb12/ )。
twitter-2010
图的有向性:有向图
点数量:41,652,230
边数量:1,468,365,182
clueweb-12
图的有向性:有向图
点数量:955,207,488
边数量:42,574,107,469
2.4 评测图算法
在 LDBC(关联数据基准委员会)提出的 Graphalytics 基准算法中,我们选出了比较典型的 PageRank、connected-component 和 SSSP 作为本评测的图算法。
为了确保评测实验的合理公平性,我们还统一了各框架的算法运行参数,并重写了部分框架的算法实现代码,以保证各框架算法运行结果的等价性(各框架的详细配置参数及源码实现请参看附录 5.1、附录 5.2、附录 5.3)。
2.4.1 PageRank
PageRank 是一种节点中心性指标算法,用于度量顶点的重要程度。
算法思路:PageRank 是一个全图迭代式算法。图中每个顶点有 1 个初始 rank值,作为顶点的重要度。算法每一轮迭代中,所有顶点的 rank 值都会更新。某顶点在一轮迭代中的新 rank 值,由所有指向它的邻居为它“贡献”的 rank 值计算得出;而该顶点的新 rank 值,又可以继续在下轮迭代为它指向的顶点做“贡献”。当迭代达到指定次数,或者全图所有顶点的 rank 值变化小于指定阈值时,算法终止。
算法统一参数:
最大迭代次数:100
结束阈值:0
2.4.2 connected-component
connected-component 算法用于识别并切分出一个非连通图中的所有最大连通子图。本评测使用的是针对有向图的单向连通图算法。
算法思路:connected-component 是一个非全图迭代式算法。我们使用 label 值来表示顶点所属的连通子图。算法开始时,将每个顶点的 label 值初始化为顶点 id,并都设为激活态。算法迭代中,激活态的顶点会向其指向的邻居顶点发送自己的 label 值,邻居顶点判断如果接收到的 label 值比自己的小,则更新 label,并把自己置为激活态。当图中没有激活态的顶点,即没有消息传递时,算法终止。最终,label 值相同的顶点被划分在同一个连通子图。
2.4.3 SSSP
SSSP(Single Source Shortest Path,单源最短路径)算法用于计算图中所有顶点到指定顶点的最短距离。
算法思路:SSSP 也是一个非全图迭代式算法。我们使用dist 表示某顶点到指定源点的最短距离。算法开始时,源点的 dist 值设为 0,其他顶点的 dist 值初始化为无穷大值,并将源点置为激活态。算法迭代中,激活态的顶点向邻居发送自己的 dist 值,邻居顶点判断如果接收到的(dist 值 +1)小于自己的 dist 值,则更新 dist,并置为激活态。当图中没有激活态的顶点,即没有消息传递时,算法终止。
算法统一参数:
源点id:0
- 结果及分析
我们分别在单节点(1 node)、两节点(2 nodes)、四节点(4 nodes)部署模式下,使用 GraphX、Giraph 和 Plato 运行 3 个算法(PageRank、connected-component、SSSP),并统计了各自的时间消耗和峰值内存占用情况。
下面分两个数据集进行结果展示及数据分析(详细评测数据请见附录5.4)。
3.1 数据集 twitter-2010
3.1.1 测试结果
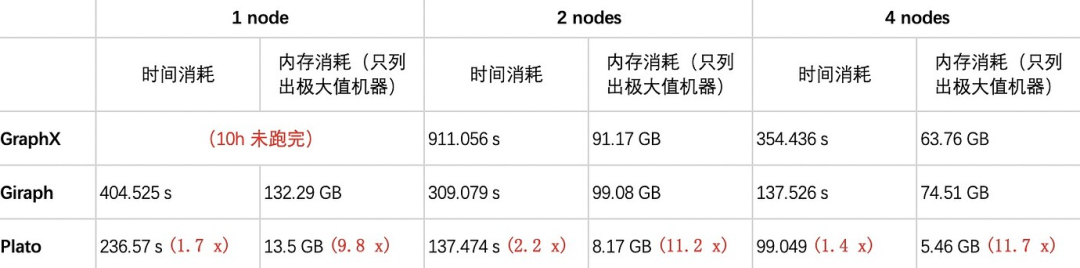
说明:GraphX 在单节点(1 node)部署模式下,无法在 10h 内完成几种算法的运行。因而缺失该情况下的统计数据。
PageRank
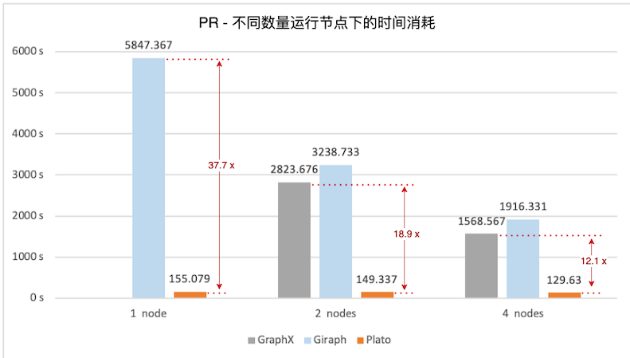
图1. PageRank 算法,不同数量运行节点下的时间消耗
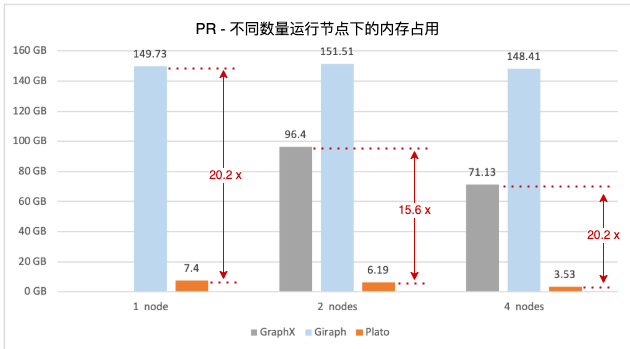
图2. PageRank 算法,不同数量运行节点下的内存占用
connected-component

图3. connected-component 算法,不同数量运行节点下的时间消耗

图4. connected-component 算法,不同数量运行节点下的内存占用
SSSP

图5. SSSP 算法,不同数量运行节点下的时间消耗

图6. SSSP 算法,不同数量运行节点下的内存占用
3.1.2 数据分析
GraphX:执行几种算法的时间和内存消耗都很高。由于依赖的底层数据模型 RDD 的不变性,计算过程中会产生大量新的 RDD 作为中间结果,虽然 GraphX 对不变的顶点和边进行了一定程度的的复用优化,但框架本身限制还是导致了大量的内存占用和较差的性能。尤其在单节点(1 node)场景下,无法在 10h 内完成几种算法的执行。
Giraph:整体性能和内存开销与 GraphX 相当。Giraph 基于 map 容器来存储图数据,带来了很高的内存占用。Giraph 的低性能,一大部分原因在于其点对点直接通信带来的高昂代价,尤其当存在大顶点时,向所有邻居都发送消息会导致巨大的消息缓存占用以及通信开销,从而引发“长尾”问题,拖慢算法的整体运行时间。
Plato:切图将顶点集合按照块式划分,并使每个顶点和它的所有出边/入边在同 1 个分片上,该原则保证了 Plato 在两种通信模式(Pull/Push)下的高效率执行。图7 为适用于 Pull 通信模式的切图方式,将顶点和其出边划分到了 1 个分片上。由于使用“点分割”切图,顶点可能存储多份,即某顶点可能有多个镜像顶点(黄色圆圈),但只会有 1 个主顶点(白色圆圈)。顶点维度的数据都存储在主顶点上,镜像顶点充当消息传递的“桥梁”。
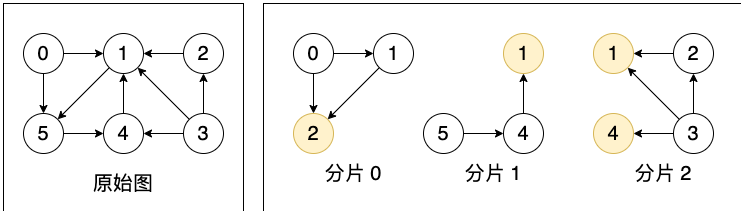
图7. 适用于 Pull 通信模式的切图
PageRank 由于是全图迭代式算法,使用 Pull 通信模式。一次完整的 Pull 通信过程,分为 SIGNAL 和 SLOT 两个阶段。
如图8 所示,以 PageRank 算法中更新顶点 1 的 rank值 为例(这里只描述模拟计算过程):在 SIGNAL 阶段,所有分片上的顶点 1(主顶点和镜像顶点)从指向它的邻居收集 rank 值并在本地聚合,聚合后的 rank 值会发给顶点 1 的主顶点所在分片(分片 0);在 SLOT 阶段,分片 0 上的主顶点将来自各分片的 rank 值进行最终的合并计算,从而得到新的 rank 值。可以看出,该模式下完成 1 个顶点的消息传递最多只需发送 (分片数 -1)个消息,大大减少了进程间通信量,能显著提升性能。
图1 显示,Plato 执行 PageRank 算法要比 GraphX / Giraph 在速度上高一个数量级。对于 connected-component 和 SSSP 这两种非全图迭代式算法,Plato 使用了自适应切换的双通信模式,运行过程中会根据该时刻活跃边数的比例来选择性能更优的通信模式,图3 和图5 看出,对比另外两个框架,Plato 有数倍到 1 个数量级的性能优势。在图数据存储方面,Plato 通过良好的数据结构设计,大大减少了内存占用。并且其顶点索引和边数组的结构设计,实现了获取某顶点邻居的时间开销为 O(1)。整体来看,Plato 比 GraphX / Giraph 计算速度高一个数量级,内存需求小一个数量级。
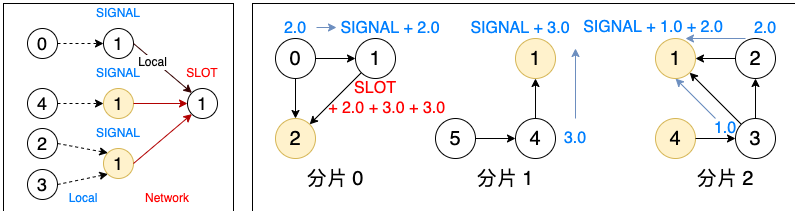
图8. Pull 通信模式
3.2 超大数据集 clueweb-12
由于机器资源限制,对于十亿点、百亿边的超大数据集 clueweb-12,我们只在 4 nodes 场景下对几个框架进行算法评测。
3.2.1 测试结果

3.2.2 数据分析
GraphX / Giraph:原因如 3.1.2 节所述,GraphX 和 Giraph 由于内存占用及性能原因,在 4 nodes 模式下,均无法在 10h 内完成算法运行。在超大数据集和四机器资源下,两框架都为不可用状态。
Plato:得益于优秀的通信模式设计和精致的存储结构实现(详见 3.1.2节),Plato 在四节点部署模式下,即使面对超大数据集,依然出色地完成了几种算法的运行,执行时间最长不超过 70 min,且单台机器的内存占用远未达到内存上限(192 GB)。
- 结论
总结上述实验结果及数据分析,我们得出以下结论:
GraphX 由于底层 RDD 的不变性,执行效率和内存占用均不理想。
Giraph 基于 map 容器的图数据结构导致了很高的内存占用,原生的点对点通信模式也造成性能低下。
Plato 的块式切分、双引擎通信模式、优化的底层存储结构设计使其不论执行效率还是内存开销都远优于另外两个框架,能高效地完成对大数据集的算法执行。
综上,我们最终选择 Plato 作为图计算平台的底层引擎。
- 附录
5.1 GraphX 配置参数及源码
5.1.1 Spark 配置参数
spark-defaults.conf
spark.driver.cores 2spark.driver.memory 2gspark.executor.memory 128gspark.local.dir /opt/meituan/appdatas/spark-tmp
5.1.2 各算法执行脚本及源码
PageRank 执行脚本
/opt/meituan/appdatas/spark-3.1.2-bin-hadoop3.2/bin/spark-submit \ # 提交 spark 任务的 bin 文件--deploy-mode cluster \ # 部署模式为集群模式--master spark://HOST:PORT \ # 指定 master 节点地址--class PageRankDemo \ # 算法的执行类/opt/meituan/appdatas/graphx-runtime/graphx-spark.jar \ # 算法的执行 jar 包spark://HOST:PORT \ # 指定 master 节点地址"/opt/meituan/appdatas/graphx-runtime/twitter-2010-s/*" \ # 输入文件名或文件夹(自动扫描文件夹下所有 csv)100 # 最大迭代轮次
PageRank 算法执行类:PageRankDemo.scala(自定义实现)
import java.io.Fileimport org.apache.spark.graphx.{Edge, Graph}import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object PageRankDemo { def main(args: Array[String]): Unit = { val master = if (args.length > 0) args(0) else "local[*]" val input = if (args.length > 1) args(1) else "test.csv" val maxIter = if (args.length > 2) args(2).toInt else 10 var watchTs = System.currentTimeMillis() val conf = new SparkConf() .setAppName("Spark PageRank") .setMaster(master) .set("spark.ui.port", "8415") val spark = new SparkContext(conf) val links: RDD[String] = spark.textFile(input) val edges = links.map( line => line.split(",") ) .map( line => ( line(0).toLong, line(1).toLong) ) val graph = Graph.fromEdgeTuples(edges, 1) println("[PERF] load edges: " + links.count() + ", init graph cost: " + (System.currentTimeMillis() - watchTs)) watchTs = System.currentTimeMillis() val ranks = graph.staticPageRank(maxIter).vertices println("[PERF] rank cost: " + (System.currentTimeMillis() - watchTs)) watchTs = System.currentTimeMillis() val outputPath = "/tmp/graphx_pr_out_csv" Util deleteDir(new File(outputPath)) ranks.saveAsTextFile(outputPath) println("[PERF] save output cost: " + (System.currentTimeMillis() - watchTs)) }}
connected-component 执行脚本
/opt/meituan/appdatas/spark-3.1.2-bin-hadoop3.2/bin/spark-submit \ # 提交 spark 任务的 bin 文件--deploy-mode cluster \ # 部署模式为集群模式--master spark://HOST:PORT \ # 指定 master 节点地址--class ConnectedComponentsDemo \ # 算法的执行类/opt/meituan/appdatas/graphx-runtime/graphx-spark.jar \ # 算法的执行 jar 包spark://HOST:PORT \ # 指定 master 节点地址"/opt/meituan/appdatas/graphx-runtime/twitter-2010-s/*" \ # 输入文件名或文件夹(自动扫描文件夹下所有 csv)
connected-component 算法执行类: ConnectedComponentsDemo.scala(自定义实现)
import java.io.Fileimport org.apache.spark.graphx.{Edge, Graph}import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object ConnectedComponentsDemo { def main(args: Array[String]): Unit = { val master = if (args.length > 0) args(0) else "local[*]" val input = if (args.length > 1) args(1) else "test.csv" var watchTs = System.currentTimeMillis() val conf = new SparkConf() .setAppName("Spark ConnectedComponents") .setMaster(master) .set("spark.ui.port", "8415") val spark = new SparkContext(conf) val links: RDD[String] = spark.textFile(input) val edges = links.map( line => line.split(",") ) .map( line => ( line(0).toLong, line(1).toLong) ) val graph = Graph.fromEdgeTuples(edges, 1) println("[PERF] load edges: " + links.count() + ", init graph cost: " + (System.currentTimeMillis() - watchTs)) watchTs = System.currentTimeMillis() val ranks = ConnectedComponentsNew.run(graph).vertices println("[PERF] rank cost: " + (System.currentTimeMillis() - watchTs)) watchTs = System.currentTimeMillis() val outputPath = "/tmp/graphx_cc_out_csv" Util deleteDir(new File(outputPath)) ranks.saveAsTextFile(outputPath) println("[PERF] save output cost: " + (System.currentTimeMillis() - watchTs)) }}
SSSP 执行脚本
/opt/meituan/appdatas/spark-3.1.2-bin-hadoop3.2/bin/spark-submit \ # 提交 spark 任务的 bin 文件--deploy-mode cluster \ # 部署模式为集群模式--master spark://HOST:PORT \ # 指定 master 节点地址--class SsspDemo \ # 算法的执行类/opt/meituan/appdatas/graphx-runtime/graphx-spark.jar \ # 算法的执行 jar 包spark://HOST:PORT \ # 指定 master 节点地址"/opt/meituan/appdatas/graphx-runtime/twitter-2010-s/*" \ # 输入文件名或文件夹(自动扫描文件夹下所有 csv)0 # 指定算法的源点
SSSP 算法执行类:SsspDemo.scala(自定义实现)
import java.io.Fileimport org.apache.spark.graphx.{Edge, EdgeDirection, Graph, VertexId}import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object SsspDemo { def main(args: Array[String]): Unit = { val master = if (args.length > 0) args(0) else "local[*]" val input = if (args.length > 1) args(1) else "test.csv" val sourceId = if (args.length > 2) args(2).toInt else 0 val maxIter = if (args.length > 3) args(3).toInt else Int.MaxValue var watchTs = System.currentTimeMillis() val conf = new SparkConf() .setAppName("Spark SSSP") .setMaster(master) .set("spark.ui.port", "8415") val spark = new SparkContext(conf) val links: RDD[String] = spark.textFile(input) val edges: RDD[Edge[Double]] = links .map( line => line.split(",") ) .map( line => Edge(line(0).toLong, line(1).toLong, 1.0d)) val vertexes: RDD[(VertexId, Double)] = edges .flatMap(edge => Array(edge.srcId, edge.dstId)) .distinct() .map(id => if (id == sourceId) (id, 0.0) else (id, Double.PositiveInfinity) ) val defaultVertex = -1.0d val initialGraph: Graph[(Double), Double] = Graph(vertexes, edges, defaultVertex) println("[PERF] load edges: " + links.count() + ", init graph cost: " + (System.currentTimeMillis() - watchTs)) watchTs = System.currentTimeMillis() val sssp = initialGraph.pregel(Double.PositiveInfinity, maxIter, EdgeDirection.Out)( //Vertex Program (id, dist, newDist) => { if (dist <= newDist) dist else newDist }, //Send Message triplet => { if (triplet.srcAttr + triplet.attr < triplet.dstAttr) { Iterator((triplet.dstId, triplet.srcAttr + triplet.attr)) } else { Iterator.empty } }, //Merge Message (a, b) => { math.min(a, b) } ) println("[PERF] rank cost: " + (System.currentTimeMillis() - watchTs)) watchTs = System.currentTimeMillis() val outputPath = "/tmp/graphx_sssp_out_csv" Util deleteDir(new File(outputPath)) sssp.vertices.saveAsTextFile(outputPath) println("[PERF] save output cost: " + (System.currentTimeMillis() - watchTs)) }}
5.2 Giraph 配置参数及源码
5.2.1 Hadoop 配置参数
yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value></property><property> <name>yarn.resourcemanager.cluster-id</name> <value>rmCluster</value></property><property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value></property><property> <name>yarn.resourcemanager.hostname.rm1</name> <value>ip2</value></property><property> <name>yarn.resourcemanager.hostname.rm2</name> <value>ip3</value></property><property> <name>yarn.resourcemanager.zk-address</name> <value>ip1:2181,ip2:2181,ip3:2181,ip4:2181</value></property><property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value></property><property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>ip2:8088</value></property><property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>ip3:8088</value></property><property> <name>yarn.application.classpath</name> <value>/opt/meituan/appdatas/hadoop-2.7.6/etc/hadoop,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/common/*,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/common/lib/*,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/hdfs/*,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/hdfs/lib/*,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/mapreduce/*,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/mapreduce/lib/*,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/yarn/*,/opt/meituan/appdatas/hadoop-2.7.6/share/hadoop/yarn/lib/* </value></property><property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value></property><property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>185344</value></property><property> <name>yarn.nodemanager.resource.memory-mb</name> <value>185344</value></property><property> <name>yarn.app.mapreduce.am.resource.mb</name> <value>4096</value></property><property> <name>yarn.app.mapreduce.am.command-opts</name> <value>-Xmx3276m</value></property><property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>48</value></property><property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>192</value></property><property> <name>dfs.datanode.max.transfer.threads</name> <value>8192</value></property></configuration>
根据调试,PageRank 算法每台机器启动 39 个 map task,connected-component 和 SSSP 算法每台机器启动 19 个 map task,能达到最优执行性能(仅作为和本评测相同机器配置的参考设置)。
mapred-site.xml(39 map task / node)
<configuration><property> <name>mapreduce.framework.name</name> <value>yarn</value></property><property> <name>mapreduce.jobhistory.address</name> <value>ip1.mt:10020</value></property><property> <name>mapreduce.jobhistory.webapp.address</name> <value>ip1:19888</value></property><property> <name>mapreduce.jobhistory.joblist.cache.size</name> <value>20000</value></property><property> <name>mapreduce.jobhistory.done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done</value></property><property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value></property><property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/opt/meituan/appdatas/hadoop-2.7.6/data/hadoop-yarn/staging</value></property><property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property> <name>mapred.job.tracker</name> <value>ip1.mt:54311</value></property><property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>40</value></property><property> <name>mapred.map.tasks</name> <value>2</value></property><property> <name>mapreduce.map.memory.mb</name> <value>4608</value></property><property> <name>mapreduce.reduce.memory.mb</name> <value>10</value></property><property> <name>mapreduce.map.java.opts</name> <value>-Xmx4147m</value></property><property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx8m</value></property><property> <name>mapred.task.timeout</name> <value>36000000</value></property><property> <name>mapreduce.job.counters.limit</name> <value>500</value></property></configuration>
mapred-site.xml(19 map task / node)
<configuration><property> <name>mapreduce.framework.name</name> <value>yarn</value></property><property> <name>mapreduce.jobhistory.address</name> <value>ip1:10020</value></property><property> <name>mapreduce.jobhistory.webapp.address</name> <value>ip1:19888</value></property><property> <name>mapreduce.jobhistory.joblist.cache.size</name> <value>20000</value></property><property> <name>mapreduce.jobhistory.done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done</value></property><property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value></property><property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/opt/meituan/appdatas/hadoop-2.7.6/data/hadoop-yarn/staging</value></property><property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property> <name>mapred.job.tracker</name> <value>xr-nlpkg-graph-proxy01.mt:54311</value></property><property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>20</value></property><property> <name>mapred.map.tasks</name> <value>2</value></property><property> <name>mapreduce.map.memory.mb</name> <value>9216</value></property><property> <name>mapreduce.reduce.memory.mb</name> <value>10</value></property><property> <name>mapreduce.map.java.opts</name> <value>-Xmx8294m</value></property><property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx8m</value></property><property> <name>mapred.task.timeout</name> <value>36000000</value></property><property> <name>mapreduce.job.counters.limit</name> <value>500</value></property></configuration>
5.2.2 各算法执行脚本及源码
边输入文件的解析类:LongStaticDoubleTextEdgeInputFormat.java(自定义实现)
package org.apache.giraph.io.formats;import org.apache.giraph.io.EdgeReader;import org.apache.giraph.utils.IntPair;import org.apache.hadoop.io.FloatWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.InputSplit;import org.apache.hadoop.mapreduce.TaskAttemptContext;import java.io.IOException;import java.util.regex.Pattern;/** * Simple text-based {@link org.apache.giraph.io.EdgeInputFormat} for * unweighted graphs with int ids. * * Each line consists of: source_vertex, target_vertex */public class LongStaticDoubleTextEdgeInputFormat extends TextEdgeInputFormat<LongWritable, FloatWritable> { /** Splitter for endpoints */ private static final Pattern SEPARATOR = Pattern.compile(","); @Override public EdgeReader<LongWritable, FloatWritable> createEdgeReader( InputSplit split, TaskAttemptContext context) throws IOException { return new LongStaticDoubleTextEdgeReader(); } public class LongStaticDoubleTextEdgeReader extends TextEdgeReaderFromEachLineProcessed<IntPair> { @Override protected IntPair preprocessLine(Text line) throws IOException { String[] tokens = SEPARATOR.split(line.toString()); return new IntPair(Integer.parseInt(tokens[0]), Integer.parseInt(tokens[1])); } @Override protected LongWritable getSourceVertexId(IntPair endpoints) throws IOException { return new LongWritable(endpoints.getFirst()); } @Override protected LongWritable getTargetVertexId(IntPair endpoints) throws IOException { return new LongWritable(endpoints.getSecond()); } @Override protected FloatWritable getValue(IntPair endpoints) throws IOException { // 本类只处理无权图,这里将边权重初始化为默认值1.0 return new FloatWritable(1.0f); } }}
PageRank 执行脚本
hadoop fs -rm -r /giraph-out-prhadoop jar /opt/meituan/appdatas/nlp-giraph/giraph-examples/target/giraph-examples-1.3.0-SNAPSHOT-for-hadoop-2.7.6-jar-with-dependencies.jar \ # 编译的jar包org.apache.giraph.GiraphRunner \ # Giraph启动类org.apache.giraph.examples.SimplePageRankComputation \ # 算法的执行类-mc org.apache.giraph.examples.SimplePageRankComputation\$SimplePageRankMasterCompute \ # 算法的主计算类(pagerank算法的特殊配置)-eif org.apache.giraph.io.formats.LongStaticDoubleTextEdgeInputFormat \ # 输入边文件的解析类(自定义实现)-eip /giraph-input/twitter-2010-s \ # 输入边文件的文件名或文件夹(自动扫描文件夹下所有csv)-vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \ # 顶点数据的输出类-op /giraph-out-pr \ # 顶点数据的输出路径-w 39*N \ # 启动的总worker数量(N为机器数量)-ca giraph.SplitMasterWorker=true # 指定自定义参数
connected-component 执行脚本
hadoop fs -rm -r /giraph-out-cchadoop jar /opt/meituan/appdatas/nlp-giraph/giraph-examples/target/giraph-examples-1.3.0-SNAPSHOT-for-hadoop-2.7.6-jar-with-dependencies.jar \ # 编译的jar包org.apache.giraph.GiraphRunner \ # Giraph启动类org.apache.giraph.examples.ConnectedComponentsComputation \ # 算法的执行类-eif org.apache.giraph.io.formats.LongStaticDoubleTextEdgeInputFormat \ # 输入边文件的解析类(自定义实现)-eip /giraph-input/twitter-2010-s \ # 输入边文件的文件名或文件夹(自动扫描文件夹下所有csv)-vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \ # 顶点数据的输出类-op /giraph-out-cc \ # 顶点数据的输出路径-w 19*N \ # 启动的总worker数量(N为机器数量)-ca giraph.SplitMasterWorker=true # 指定自定义参数
connected-component 算法执行类:ConnectedComponentsComputation.java(有逻辑重写)
package org.apache.giraph.examples;import org.apache.giraph.graph.BasicComputation;import org.apache.giraph.edge.Edge;import org.apache.giraph.graph.Vertex;import org.apache.hadoop.io.FloatWritable;import org.apache.hadoop.io.LongWritable;import java.io.IOException;@Algorithm( name = "Connected components", description = "Finds connected components of the graph")public class ConnectedComponentsComputation extends BasicComputation<LongWritable, LongWritable, FloatWritable, LongWritable> { /** * Propagates the smallest vertex id to all neighbors. Will always choose to * halt and only reactivate if a smaller id has been sent to it. * * @param vertex Vertex * @param messages Iterator of messages from the previous superstep. * @throws IOException */ @Override public void compute( Vertex<LongWritable, LongWritable, FloatWritable> vertex, Iterable<LongWritable> messages) throws IOException { if (getSuperstep() == 0 || getSuperstep() == 1 && vertex.getNumEdges() == 0) { // 初始化label值为顶点id vertex.setValue(vertex.getId()); } long currentComponent = vertex.getValue().get(); if (getSuperstep() == 0) { for (Edge<LongWritable, FloatWritable> edge : vertex.getEdges()) { LongWritable neighbor = edge.getTargetVertexId(); sendMessage(neighbor, vertex.getValue()); } vertex.voteToHalt(); return; } boolean changed = false; for (LongWritable message : messages) { long candidateComponent = message.get(); if (candidateComponent < currentComponent) { currentComponent = candidateComponent; changed = true; } } // propagate new component id to the neighbors if (changed) { vertex.setValue(new LongWritable(currentComponent)); sendMessageToAllEdges(vertex, vertex.getValue()); } vertex.voteToHalt(); }}
SSSP 执行脚本
hadoop fs -rm -r /giraph-out-sssphadoop jar /opt/meituan/appdatas/nlp-giraph/giraph-examples/target/giraph-examples-1.3.0-SNAPSHOT-for-hadoop-2.7.6-jar-with-dependencies.jar \ # 编译的jar包org.apache.giraph.GiraphRunner \ # Giraph启动类org.apache.giraph.examples.SimpleShortestPathsComputation \ # 算法的执行类-eif org.apache.giraph.io.formats.LongStaticDoubleTextEdgeInputFormat \ # 输入边文件的解析类(自定义实现)-eip /giraph-input/twitter-2010-s \ # 输入边文件的文件名或文件夹(自动扫描文件夹下所有csv)-vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \ # 顶点数据的输出类-op /giraph-out-sssp \ # 顶点数据的输出路径-w 19*N \ # 启动的总worker数量(N为机器数量)-ca giraph.SplitMasterWorker=true,SimpleShortestPathsVertex.sourceId=0 # 指定自定义参数
SSSP 算法执行类:SimpleShortestPathsComputation.java(有逻辑重写)
package org.apache.giraph.examples;import org.apache.giraph.graph.BasicComputation;import org.apache.giraph.conf.LongConfOption;import org.apache.giraph.edge.Edge;import org.apache.giraph.graph.Vertex;import org.apache.hadoop.io.DoubleWritable;import org.apache.hadoop.io.FloatWritable;import org.apache.hadoop.io.LongWritable;import org.apache.log4j.Logger;import java.io.IOException;/** * Demonstrates the basic Pregel shortest paths implementation. */@Algorithm( name = "Shortest paths", description = "Finds all shortest paths from a selected vertex")public class SimpleShortestPathsComputation extends BasicComputation< LongWritable, DoubleWritable, FloatWritable, DoubleWritable> { /** The shortest paths id */ public static final LongConfOption SOURCE_ID = new LongConfOption("SimpleShortestPathsVertex.sourceId", 1, "The shortest paths id"); /** Class logger */ private static final Logger LOG = Logger.getLogger(SimpleShortestPathsComputation.class); /** * Is this vertex the source id? * * @param vertex Vertex * @return True if the source id */ private boolean isSource(Vertex<LongWritable, ?, ?> vertex) { return vertex.getId().get() == SOURCE_ID.get(getConf()); } @Override public void compute( Vertex<LongWritable, DoubleWritable, FloatWritable> vertex, Iterable<DoubleWritable> messages) throws IOException { if (getSuperstep() == 0 || !isSource(vertex) && vertex.getValue().get() == 0.0) { // 所有顶点的距离值初始化为最大值 vertex.setValue(new DoubleWritable(Double.MAX_VALUE)); } double minDist = isSource(vertex) ? 0d : Double.MAX_VALUE; for (DoubleWritable message : messages) { minDist = Math.min(minDist, message.get()); } if (minDist < vertex.getValue().get()) { vertex.setValue(new DoubleWritable(minDist)); for (Edge<LongWritable, FloatWritable> edge : vertex.getEdges()) { double distance = minDist + edge.getValue().get(); sendMessage(edge.getTargetVertexId(), new DoubleWritable(distance)); } } vertex.voteToHalt(); }}
5.3 Plato 配置参数及源码
5.3.1 各算法执行脚本及源码
PageRank 执行脚本
#!/bin/bashset -exROOT_DIR="/opt/meituan/appdatas/plato-mt-0.1.1" # 源代码路径WORK_DIR="/opt/meituan/appdatas/plato-runtime" # 工作路径MAIN="$ROOT_DIR/bazel-bin/example/pagerank" # 编译好的算法二进制文件所在地址WNUM=N # 进程分片数WCORES=48 # 使用线程数MPI_HOSTS="HOST1,HOST2..." # 进程ip列表(替换为实际的机器ip列表)INPUT=${INPUT:="/opt/meituan/appdatas/graphx-runtime/twitter-2010-s"} # 输入文件名或文件夹(自动扫描文件夹下所有csv)OUTPUT=${OUTPUT:="$WORK_DIR/../plato-output/pr_output"} # 输出文件夹IS_DIRECTED=${IS_DIRECTED:=true} # 是否有向图EPS=${EPS:=0} # Delta值小于此值认为迭代已经收敛,立即退出DAMPING=${DAMPING:=0.85} # 整形参数ITERATIONS=${ITERATIONS:=100} # 最大迭代轮次# paramPARAMS+=" --threads ${WCORES}"PARAMS+=" --input ${INPUT} --output ${OUTPUT} --is_directed=${IS_DIRECTED}"PARAMS+=" --iterations ${ITERATIONS} --eps ${EPS} --damping ${DAMPING}"# mpichMPIRUN_CMD=${MPIRUN_CMD:="$ROOT_DIR/3rd/mpich/bin/mpiexec.hydra"}# testexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$ROOT_DIR/3rd/hadoop2/lib# run${MPIRUN_CMD} -n ${WNUM} -host $MPI_HOSTS ${MAIN} ${PARAMS} # host参数指定执行机,需要能通过ssh公钥访问
connected-component 执行脚本
#!/bin/bashset -exROOT_DIR="/opt/meituan/appdatas/plato-mt-0.1.1" # 源代码路径WORK_DIR="/opt/meituan/appdatas/plato-runtime" # 工作路径MAIN="$ROOT_DIR/bazel-bin/example/cgm_simple" # 编译好的算法二进制文件所在地址WNUM=N # 进程分片数(N 替换为机器个数)WCORES=48 # 使用线程数MPI_HOSTS="HOST1,HOST2..." # 进程ip列表(替换为实际的机器ip列表)INPUT=${INPUT:="/opt/meituan/appdatas/graphx-runtime/twitter-2010-s"} # 输入文件名或文件夹(自动扫描文件夹下所有csv)OUTPUT=${OUTPUT:="$WORK_DIR/../plato-output/cc_output"} # 输出文件夹IS_DIRECTED=${IS_DIRECTED:=true} # 是否有向图OUTPUT_METHOD=${OUTPUT_METHOD:="all_vertices"} # 输出的结果格式# paramPARAMS+=" --threads ${WCORES}"PARAMS+=" --input ${INPUT} --output ${OUTPUT} --is_directed=${IS_DIRECTED}"PARAMS+=" --output_method ${OUTPUT_METHOD}"# mpichMPIRUN_CMD=${MPIRUN_CMD:="$ROOT_DIR/3rd/mpich/bin/mpiexec.hydra"}# testexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$ROOT_DIR/3rd/hadoop2/lib# run${MPIRUN_CMD} -n ${WNUM} -host $MPI_HOSTS ${MAIN} ${PARAMS} # host参数指定执行机,需要能通过ssh公钥访问
SSSP 执行脚本
#!/bin/bashset -exROOT_DIR="/opt/meituan/appdatas/plato-mt-0.1.1" # 源代码路径WORK_DIR="/opt/meituan/appdatas/plato-runtime" # 工作路径MAIN="$ROOT_DIR/bazel-bin/example/sssp_simple" # 编译好的算法二进制文件所在地址WNUM=N # 进程分片数(N 替换为机器个数)WCORES=48 # 使用线程数MPI_HOSTS="HOST1,HOST2..." # 进程ip列表(替换为实际的机器ip列表)INPUT=${INPUT:="/opt/meituan/appdatas/graphx-runtime/twitter-2010-s"} # 输入文件名或文件夹(自动扫描文件夹下所有csv)OUTPUT=${OUTPUT:="$WORK_DIR/../plato-output/sssp_output"} # 输出文件夹IS_DIRECTED=${IS_DIRECTED:=true} # 是否有向图# paramPARAMS+=" --threads ${WCORES}"PARAMS+=" --input ${INPUT} --output ${OUTPUT} --is_directed=${IS_DIRECTED}"# mpichMPIRUN_CMD=${MPIRUN_CMD:="$ROOT_DIR/3rd/mpich/bin/mpiexec.hydra"}# testexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$ROOT_DIR/3rd/hadoop2/lib# run${MPIRUN_CMD} -n ${WNUM} -host $MPI_HOSTS ${MAIN} ${PARAMS} # host参数指定执行机,需要能通过ssh公钥访问
Plato 本身不包含 SSSP 算法包,因此对该算法进行了等价性实现:
1、在 /example 文件夹下新建 sssp_simple.cc,并在BUILD文件最后添加如下内容。
sssp_simple.cc:
#include <cstdint>#include "glog/logging.h"#include "gflags/gflags.h"#include "plato/graph/graph.hpp"#include "plato/algo/sssp/sssp.hpp"DEFINE_string(input, "", "input file, in csv format, without edge data");DEFINE_string(output, "", "output directory, store the sssp result");DEFINE_bool(is_directed, true, "is graph directed or not");DEFINE_uint32(root, 0, "start sssp from which vertex");DEFINE_int32(alpha, -1, "alpha value used in sequence balance partition");DEFINE_bool(part_by_in, false, "partition by in-degree");bool string_not_empty(const char*, const std::string& value) { if (0 == value.length()) { return false; } return true;}DEFINE_validator(input, &string_not_empty);DEFINE_validator(output, &string_not_empty);void init(int argc, char** argv) { gflags::ParseCommandLineFlags(&argc, &argv, true); google::InitGoogleLogging(argv[0]); google::LogToStderr();}int main(int argc, char** argv) { plato::stop_watch_t watch; auto& cluster_info = plato::cluster_info_t::get_instance(); watch.mark("load"); init(argc, argv); cluster_info.initialize(&argc, &argv); plato::graph_info_t graph_info(FLAGS_is_directed); auto graph = plato::create_dualmode_seq_from_path<plato::empty_t>(&graph_info, FLAGS_input, plato::edge_format_t::CSV, plato::dummy_decoder<plato::empty_t>, FLAGS_alpha, FLAGS_part_by_in); plato::algo::sssp_opts_t opts; opts.root_ = FLAGS_root; watch.mark("t0"); plato::thread_local_fs_output os(FLAGS_output, (boost::format("%04d_") % cluster_info.partition_id_).str(), true); auto callback = [&] (plato::vid_t v_i, std::uint32_t value) { auto& fs_output = os.local(); fs_output << v_i << "," << value << "\n"; }; if (0 == cluster_info.partition_id_) { LOG(INFO) << "Load graph cost: " << watch.show("load") / 1000.0 << "s"; } plato::vid_t visited = plato::algo::single_source_shortest_path(graph.second, graph.first, graph_info, opts, callback); if (0 == cluster_info.partition_id_) { LOG(INFO) << "sssp done, visited: " << visited << ", cost: " << watch.show("t0") / 1000.0 << "s"; } return 0;}
BUILD:
cc_binary ( name = "sssp_simple", srcs = [ "sssp_simple.cc", ], copts = ['-g', '-O2', ] + PLATO_OPTS, linkopts = [ ] + PLATO_OPTS, deps = [ "//3rd/glog:glog", "//3rd/gflags:gflags", "//3rd/boost:boost_include", "//plato/graph:graph", "//plato/algo/sssp:sssp", ], defines = [ # "__DCSC_DEBUG__", ], linkstatic = 1,)
2、新建 /plato/algo/sssp 目录,并在该路径下新建 sssp.hpp 和 BUILD文件。
sssp.hpp:
#ifndef __PLATO_ALGO_SSSP_HPP__#define __PLATO_ALGO_SSSP_HPP__#include <cstdint>#include <cstdlib>#include "glog/logging.h"#include "plato/util/perf.hpp"#include "plato/util/atomic.hpp"#include "plato/graph/graph.hpp"#include "plato/engine/dualmode.hpp"namespace plato { namespace algo {struct sssp_opts_t { vid_t root_ = 0;};// distance 消息结构体struct distance_msg_type_t { vid_t v_i; std::uint32_t value;};/* * demo implementation of single source shortest path * * \tparam INCOMING graph type, with incoming edges * \tparam OUTGOING graph type, with outgoing edges * * \param in_edges incoming edges, dcsc, ... * \param out_edges outgoing edges, bcsr, ... * \param graph_info base graph-info * \param opts sssp options * \param callback callback func to ouput result * * \return * visited vertices count * */template <typename INCOMING, typename OUTGOING, typename Callback>vid_t single_source_shortest_path( INCOMING& in_edges, OUTGOING& out_edges, const graph_info_t& graph_info, const sssp_opts_t& opts, Callback&& callback) { plato::stop_watch_t watch; auto& cluster_info = plato::cluster_info_t::get_instance(); watch.mark("run"); // 传入两种切分方式的图数据,构建双模式引擎 dualmode_engine_t<INCOMING, OUTGOING> engine ( std::shared_ptr<INCOMING>(&in_edges, [](INCOMING*) { }), std::shared_ptr<OUTGOING>(&out_edges, [](OUTGOING*) { }), graph_info); // alloc structs used during bfs auto visited = engine.alloc_v_subset(); // 标记已访问的顶点 auto active_current = engine.alloc_v_subset(); // 标记本轮迭代中活跃的顶点 auto active_next = engine.alloc_v_subset(); // 标记下轮迭代中活跃的顶点 auto distance = engine.template alloc_v_state<std::uint32_t>(); // 存储顶点的最短距离 // 初始化非源点的距离为最大值、源点的距离为0 distance.fill(std::numeric_limits<std::uint32_t>::max()); distance[opts.root_] = 0; // 标记源点已访问过 visited.set_bit(opts.root_); // 标记源点为活跃态 active_current.set_bit(opts.root_); // 全局变量,统计所有分片中活跃态的顶点数量 plato::vid_t actives = 1; for (int epoch_i = 0; 0 != actives; ++epoch_i) { using pull_context_t = plato::template mepa_ag_context_t<distance_msg_type_t>; using pull_message_t = plato::template mepa_ag_message_t<distance_msg_type_t>; using push_context_t = plato::template mepa_bc_context_t<distance_msg_type_t>; using adj_unit_list_spec_t = typename INCOMING::adj_unit_list_spec_t; watch.mark("t1"); active_next.clear(); actives = engine.template foreach_edges<distance_msg_type_t, plato::vid_t> ( // PUSH [&](const push_context_t& context, vid_t v_i) { context.send(distance_msg_type_t {v_i, distance[v_i] + 1}); }, [&](int /*p_i*/, distance_msg_type_t& msg) { plato::vid_t activated = 0; auto neighbours = out_edges.neighbours(msg.v_i); for (auto it = neighbours.begin_; neighbours.end_ != it; ++it) { plato::vid_t dst = it->neighbour_; if ((plato::write_min(&distance[dst], msg.value)) ) { active_next.set_bit(dst); visited.set_bit(dst); ++activated; } } return activated; }, // PULL [&](const pull_context_t& context, plato::vid_t v_i, const adj_unit_list_spec_t& adjs) { for (auto it = adjs.begin_; adjs.end_ != it; ++it) { plato::vid_t src = it->neighbour_; if (active_current.get_bit(src)) { context.send(pull_message_t {v_i, distance_msg_type_t{v_i, distance[src] + 1}}); break; } } }, [&](int, pull_message_t & msg) { if (plato::write_min(&distance[msg.v_i_], msg.message_.value)) { active_next.set_bit(msg.v_i_); visited.set_bit(msg.v_i_); return 1; } return 0; }, active_current ); std::swap(active_current, active_next); if (0 == cluster_info.partition_id_) { LOG(INFO) << "active_v[" << epoch_i << "] = " << actives << ", cost: " << watch.show("t1") / 1000.0 << "s"; } } if (0 == cluster_info.partition_id_) { LOG(INFO) << "Run cost: " << watch.show("run") / 1000.0 << "s"; } watch.mark("output"); // save output auto active_all = engine.alloc_v_subset(); active_all.fill(); //traverse auto active_view_all = plato::create_active_v_view(engine.out_edges()->partitioner()->self_v_view(), active_all); active_view_all.template foreach<vid_t>([&] (vid_t v_i) { callback(v_i, distance[v_i]); return 1; }); if (0 == cluster_info.partition_id_) { LOG(INFO) << "Output cost: " << watch.show("output") / 1000.0 << "s"; } visited.sync(); return visited.count();}}} // namespace algo, namespace plato#endif
BUILD:
load("//build_tools/rules:variables.bzl", "PLATO_OPTS")cc_library ( name = "sssp", hdrs = [ "sssp.hpp", ], srcs = [], includes = [ ".", ], deps = [ "//3rd/glog:glog", "//plato/util:perf", "//plato/util:atomic", "//plato/graph:graph", "//plato/engine:dualmode", ], defines = [ "__DUALMODE_DEBUG__", ], copts = [ '-O2', '-Wall', '-std=c++11', ] + PLATO_OPTS, linkopts = [ ] + PLATO_OPTS, visibility = ["//visibility:public"],)
5.4 评测原始数据
5.4.1 twitter-2010 原始数据
PageRank
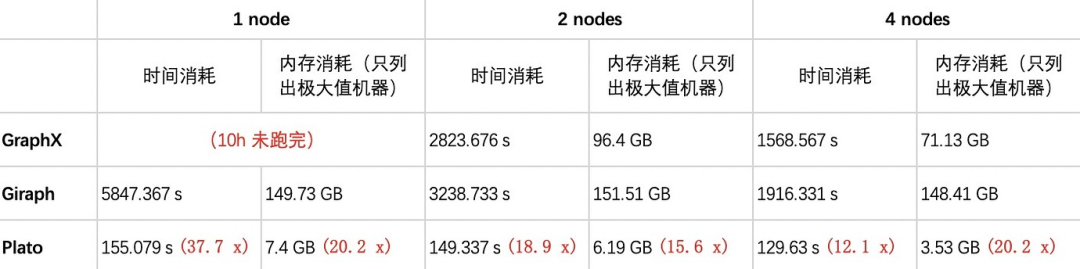
18.9 x:表示在 2 nodes 模式下,Plato 与另外两个框架中性能较优的运行时间比值(2823.676 / 149.337 = 18.9)。即在该场景下,Plato 相比另外两个框架性能至少提升了 18.9 倍。其他指标同理。
connected-component
SSSP

5.4.2 clueweb-12 原始数据

- 参考阅读
主流开源分布式图计算框架 Benchmark的更多相关文章
- 主流开源分布式图数据库 Benchmark
本文由美团 NLP 团队高辰.赵登昌撰写 首发于 Nebula Graph 官方论坛:https://discuss.nebula-graph.com.cn/t/topic/1377 1. 前言 近年 ...
- 腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- 明风:分布式图计算的平台Spark GraphX 在淘宝的实践
快刀初试:Spark GraphX在淘宝的实践 作者:明风 (本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版) ...
- 开源图计算框架GraphLab介绍
GraphLab介绍 GraphLab 是由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架.框架使用C++语言开发实现. 该框架是面向机器学习( ...
- [开源]CSharpFlink(NET 5.0开发)分布式实时计算框架,PC机10万数据点秒级计算测试说明
github地址:https://github.com/wxzz/CSharpFlinkgitee地址:https://gitee.com/wxzz/CSharpFlink 1 计算 ...
- 开源分布式实时计算引擎 Iveely Computing 之 WordCount 详解(3)
WordCount是很多分布式计算中,最常用的例子,例如Hadoop.Storm,Iveely Computing也不例外.明白了WordCount在Iveely Computing上的运行原理,就很 ...
- 免费开源分布式系统日志收集框架 Exceptionless
前言 从去年就答应过Eric(Exceptionless的作者之一),在中国会帮助给 Exceptionless 做推广,但是由于各种原因一直没有做这件事情,在此对Eric表示歉意.:) Except ...
- 开源分布式实时计算引擎 Iveely Computing 之 本地调试Topology(4)
当我们写完一个比较复杂的Topology之后,倘若直接提交到服务器上运行,难免会有很多问题,如何进行本地的调试Topology,是我们非常关心的问题.我们依然以WordCount作为代码示例. 首先, ...
- 开源分布式实时计算引擎 Iveely Computing 之 安装部署(2)
在Github中下载代码和二进制程序中,您都会看到一个bin\iveely computing目录,里面即是Iveely Computing的运行库. 以前总是有 ...
- 腾讯开源进入爆发期,Plato助推十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
随机推荐
- 基于Apache PDFBox的PDF数字签名
在Java语言环境中完成数字签名主要基于itext-pdf.PDFBox两种工具,itext-pdf受商业限制,应用于商业服务中需要购买授权.PDFBox是apache基金会开源项目,基于apache ...
- 感受 Vue3 的魔法力量
作者:京东科技 牛至伟 近半年有幸参与了一个创新项目,由于没有任何历史包袱,所以选择了Vue3技术栈,总体来说感受如下: • setup语法糖<script setup lang=" ...
- 你知道css3渐变吗线性渐变和径向渐变
线性渐变 #app { width: 200px; height: 200px; background: linear-gradient(to bottom, red, green); /*从顶部到底 ...
- Vue基础系统文章07---webpack安装和配置与打包
1.当前web开发困境 a.文件依赖关系错综复杂 b.静态资源请求效率低 c.模块化支持不友好 d.浏览器对高级js兼容性低 例如:模块代码实现隔行换色 1)在新建空白文件夹中运行:npm init ...
- 第三届人工智能,大数据与算法国际学术会议 (CAIBDA 2023)
第三届人工智能,大数据与算法国际学术会议 (CAIBDA 2023) 大会官网:http://www.caibda.org/ 大会时间:2023年6月16-18日 大会地点:中国郑州 截稿日期:2 ...
- 2.1 Windows驱动开发:内核链表与结构体
在Windows内核中,为了实现高效的数据结构操作,通常会使用链表和结构体相结合的方式进行数据存储和操作.内核提供了一个专门用于链表操作的数据结构LIST_ENTRY,可以用来描述一个链表中的每一个节 ...
- RabbitMQ高级知识(消息可靠性,死信交换机,惰性队列,MQ集群)
服务异步通信-高级篇 消息队列在使用过程中,面临着很多实际问题需要思考: 1.消息可靠性 消息从发送,到消费者接收,会经历多个过程: 其中的每一步都可能导致消息丢失,常见的丢失原因包括: 发送时丢失: ...
- 【内存操作】C语言内存函数介绍以及部分模拟实现【初学者保姆级福利】超详细的解释和注释
C语言 内存函数的使用以及部分模拟实现 求个赞求个赞求个赞求个赞 谢谢 先赞后看好习惯 打字不容易,这都是很用心做的,希望得到支持你 大家的点赞和支持对于我来说是一种非常重要的动力 看完之后别忘记关注 ...
- STL源码剖析 | priority_queue优先队列底层模拟实现
今天博主继续带来STL源码剖析专栏的第四篇博客了! 今天带来优先队列priority_queue的模拟实现!话不多说,直接进入我们今天的内容! 前言 那么这里博主先安利一下一些干货满满的专栏啦! 手撕 ...
- USACO 2022 Cu 题解
USACO 2022 Cu 题解 AK用时:$ 3 $ 小时 $ 30 $ 分钟. A - Cow College 原题 Farmer John 计划为奶牛们新开办一所大学! 有 $ N $($ 1 ...