ShardingSphere实战
前言
本文主要从sharding最新版本5.1.2版本入手搭建,按主键ID和时间进行分表。
本文主要介绍搭建过程,有兴趣了解shardingsphere的同学可以先自行查阅相关资料。
shardsphere官网:https://shardingsphere.apache.org/index_zh.html(建议下载master文档进行学习)
github地址:https://github.com/apache/shardingsphere.git
gitee地址:https://gitee.com/Sharding-Sphere/sharding-sphere.git
正文
这里搭建的框架采用 springboot2 + shardingsphere5 + mybatisplus(不用写sql) + mysql(druid连接池)
1、初始化SQL脚本(需要的自行前往文末项目地址获取)
● 示例中有user表和order表,user表按id分片,order表按时间进行年月分片。
● 注意:分表需要自行预创建,这里建议写个执行器创建
2、项目引入pom依赖(这里选的版本未发现冲突)


<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency> <dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.11</version>
</dependency>
maven依赖
3、进行yml配置
● 需要加上spring.shardingsphere.props.sql-show = true , 打印sharding执行的sql,便于观察理解分表的原理,生产环境可选择关闭。
● 这里主要是用order表根据年月进行分表,因考虑到需要兼容历史表,所以这里逻辑分表需包含历史表名,具体看配置项actual-data-nodes。
● 一般建议跨两个表进行查询,比如这里是按照月份分表,则建议限制查询时间跨度最大为一个月,这样最多跨两个逻辑分表进行查询,性能会提高很多。
spring:
application:
name: demo-shardingsphere
shardingsphere:
# 打印执行sql
props:
sql-show: true
# 数据源配置
datasource:
names: test
test:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ss_test?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: root
# 分片规则
rules:
sharding:
# 分片策略
sharding-algorithms:
# 自定义分片策略
order_inline:
type: class_based
props:
strategy: standard
algorithmClassName: com.demo.config.sharding.algorithm.OrderTableAlgorithm
tables:
# 需要进行分片的逻辑表名前缀
t_order:
# 逻辑分表
actual-data-nodes: test.t_order,test.t_order_$->{2022..2025}0$->{1..9},test.t_order_$->{2022..2025}1$->{0..2}
table-strategy:
standard:
# 分表的字段
sharding-column: create_date
# 自定义的分片策略名
sharding-algorithm-name: order_inline # 下面是按主键进行分表,规则比较简单,自定义表达式即可
# sharding-algorithms:
# user_inline:
# type: inline
# props:
# algorithm-expression: user_$->{id % 2}
# tables:
# user:
# actual-data-nodes: test.user_$->{0..1}
# table-strategy:
# standard:
# sharding-column: id
# sharding-algorithm-name: user_inline
# key-generate-strategy:
# column: id
# key-generator-name: snowflake
# key-generators:
# snowflake:
# type: SNOWFLAKE server:
port: 8889 # 定义跨表时间查询范围,小于min时间,则联查历史表,不允许大于max时间,具体可看自定义的分片策略实现
sharding:
table:
user:
base:
date:
min: 2022-08-01 00:00:00
max: 2023-01-31 23:59:59 #logging:
# level:
# com.demo.mapper: debug
配置文件
4、自定分片策略
● 这里采用jdk8的新时间特性LocalDateTime,需要与定义的分表字段类型对应上。
● sharding5使用了新的分片对象(5之前使用PreciseShargingAlgorithm),查询和插入都可以在一个对象里配置。
● 考虑到有些项目已经是在线上运行的项目,需要兼容历史表,这里配置中做了判断,需自行配置分表投产的时间作为区分,历史表数据不动,新数据采用分表插入和查询。
private static final DateTimeFormatter dateFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
private static final DateTimeFormatter monthFormatter = DateTimeFormatter.ofPattern("yyyyMM");
/**
* 获取查询对应分表名
* @param collection
* @param preciseShardingValue
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<LocalDateTime> preciseShardingValue) {
LocalDateTime date = preciseShardingValue.getValue();
if (date == null) {
return collection.stream().findFirst().get();
}
String tableName = preciseShardingValue.getLogicTableName();
// 如果查询范围包括基础表,则需要联合基础表进行查询
LocalDateTime minBaseDate = LocalDateTime.parse(StaticValue.userBaseTableMinDate, dateFormatter);
if (date.isAfter(minBaseDate)) {
String tableSuffix = date.format(monthFormatter);
tableName = tableName.concat("_").concat(tableSuffix);
}
String t = tableName;
return collection.stream().filter(str -> str.equals(t)).findFirst().orElseThrow(() -> new RuntimeException(t + "分表不存在"));
}
/**
* 范围查询获取所有分表
*
* @param collection
* @param rangeShardingValue
* @return 分表集合
*/
@Override
public Collection<String> doSharding(Collection collection, RangeShardingValue rangeShardingValue) {
String logicTableName = rangeShardingValue.getLogicTableName();
Range<LocalDateTime> valueRange = rangeShardingValue.getValueRange();
Set<String> tableRange = extracted(logicTableName, valueRange.lowerEndpoint(), valueRange.upperEndpoint());
return tableRange;
}
/**
* 根据时间范围获取分表集合
*
* @param logicTableName
* @param lowerEndpoint
* @param upperEndpoint
* @return
*/
private Set<String> extracted(String logicTableName, LocalDateTime lowerEndpoint, LocalDateTime upperEndpoint) {
Set<String> rangeTable = new HashSet<>();
// 如果查询范围包括基础表,则需要联合基础表进行查询
LocalDateTime minBaseDate = LocalDateTime.parse(StaticValue.userBaseTableMinDate, dateFormatter);
LocalDateTime maxBaseDate = LocalDateTime.parse(StaticValue.userBaseTableMaxDate, dateFormatter);
if (lowerEndpoint.isBefore(minBaseDate)) {
lowerEndpoint = minBaseDate;
rangeTable.add(logicTableName);
}
if (upperEndpoint.isAfter(maxBaseDate)) {
throw new RuntimeException("结束时间不在当前时间内");
}
// 便利所有分表
while (lowerEndpoint.isBefore(upperEndpoint)) {
String tableName = logicTableName.concat("_").concat(lowerEndpoint.format(monthFormatter));
rangeTable.add(tableName);
lowerEndpoint = lowerEndpoint.plusMonths(1);
}
// 可能开始时间累加后与结束时间一致
String tableName = logicTableName.concat("_").concat(upperEndpoint.format(monthFormatter));
rangeTable.add(tableName);
return rangeTable;
}
5、自定义接口测试
● 接口定义请自行参考文末项目源码,这里直接上测试结果图
测试场景一:插入一条2022年10月份数据
sharding运行过程

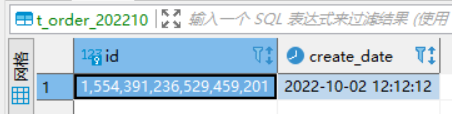
执行结果,插入到表t_order_202210
测试场景二:范围查找2022-07-01至2022-12-01
sharding执行过程
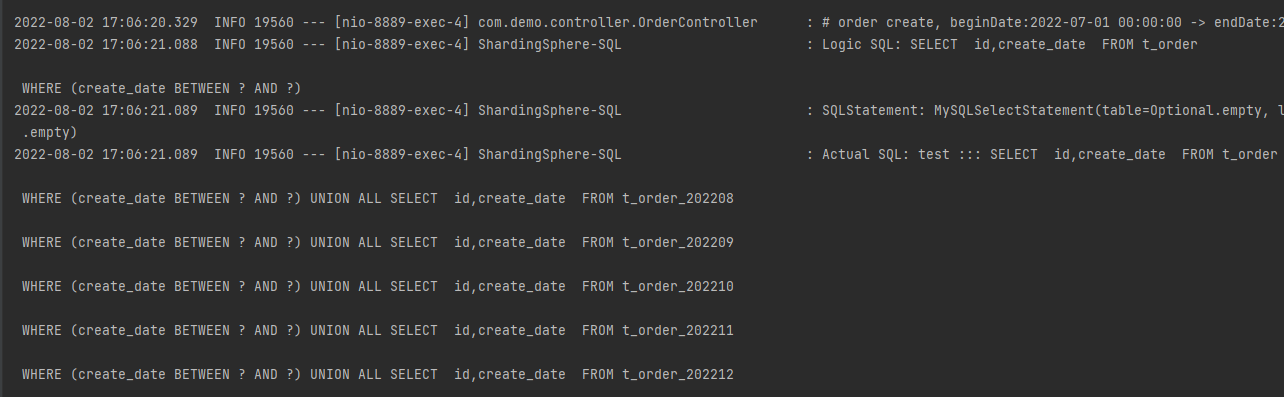
执行结果,可以观察到我们刚插入的数据,另外一条是之前测试插入的
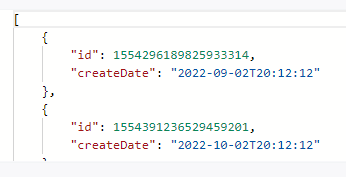
至此,本片文章结束,有兴趣的同学可以一起讨论,谢谢。
有兴趣可参考完整项目地址:https://gitee.com/yhc910/demo-shardingsphere
实战注意点(实时更新):
1、druid连接池属性,jdbc-url改为url
2、sharding-algorithm-name,注意algorithm后面不要加s,后面debug源码才找到问题
3、数据源配置url后面的属性,不要连着两个&&,不然会报错无效数组
ShardingSphere实战的更多相关文章
- 图灵学院JAVA互联网架构师专题学习笔记
图灵学院JAVA互联网架构师专题学习笔记 下载链接:链接: https://pan.baidu.com/s/1xbxDzmnQudnYtMt5Ce1ONQ 密码: fbdj如果失效联系v:itit11 ...
- ShardingSphere 集成 CosId 实战
背景 在软件系统演进过程中,随着业务规模的增长 (TPS/存储容量),我们需要通过集群化部署来分摊计算.存储压力. 应用服务的无状态设计使其具备了伸缩性.在使用 Kubernetes 部署时我们只需要 ...
- 数据量大了一定要分表,分库分表组件Sharding-JDBC入门与项目实战
最近项目中不少表的数据量越来越大,并且导致了一些数据库的性能问题.因此想借助一些分库分表的中间件,实现自动化分库分表实现.调研下来,发现Sharding-JDBC目前成熟度最高并且应用最广的Java分 ...
- Java实战:教你如何进行数据库分库分表
摘要:本文通过实际案例,说明如何按日期来对订单数据进行水平分库和分表,实现数据的分布式查询和操作. 本文分享自华为云社区<数据库分库分表Java实战经验总结 丨[绽放吧!数据库]>,作者: ...
- Apache ShardingSphere 在京东白条场景的落地之旅
京东白条使用 Apache ShardingSphere 解决了千亿数据存储和扩容的问题,为大促活动奠定了基础. 2014 年初,"京东白条"作为业内互联网信用支付产品,数据量爆发 ...
- DistSQL:像数据库一样使用 Apache ShardingSphere
Apache ShardingSphere 5.0.0-beta 深度解析的第一篇文章和大家一起重温了 ShardingSphere 的内核原理,并详细阐述了此版本在内核层面,特别是 SQL 能力方面 ...
- 重磅|Apache ShardingSphere 5.0.0 即将正式发布
Apache ShardingSphere 5.0.0 GA 版在经历 5.0.0-alpha 及 5.0.0-beta 接近两年时间的研发和打磨,终于将在 11 月份与大家正式见面! 11 月 10 ...
- 如何在 ShardingSphere 中开发自己的 DistSQL
在<DistSQL:像数据库一样使用 Apache ShardingSphere>和<SCTL 涅槃重生:投入 RAL 的怀抱>中,已经为大家介绍了 DistSQL 的设计初衷 ...
- ShardingSphere 云上实践:开箱即用的 ShardingSphere-Proxy 集群
本次 Apache ShardingSphere 5.1.2 版本更新为大家带来了三大全新功能,其中之一即为使用 ShardingSphere-Proxy chart 在云环境中快速部署一套 Shar ...
- ShardingSphere数据分片
码农在囧途 坚持是一件比较难的事,坚持并不是自欺欺人的一种自我麻痹和安慰,也不是做给被人的,我觉得,坚持的本质并没有带着过多的功利主义,如果满是功利主义,那么这个坚持并不会长久,也不会有好的收获,坚持 ...
随机推荐
- 基于Expression Lambda表达式树的通用复杂动态查询构建器——《构思篇一》
在上一篇中构思了把查询子句描述出来的数据结构,那么能否用代码将其表达出来,如何表达呢? 再次回顾考察,看下面的查询子句: Id>1 and Id<10 如上所示,有两个独立的条件分别为Id ...
- Manjaro linux 安装svn 并在文件管理器里显示相关图标
需要先安装svn linux版打开终端执行 sudo pacman -S svn 安装完成后执行一下 svn --version 出现这个就说明svn已经安装完成了,这个时候我们可以执行 svn ch ...
- GaussDB(DWS)迁移实践丨row_number输出结果不一致
摘要:迁移前后结果集row_number字段值前后不一致,前在DWS上运行不一致. 本文分享自华为云社区<GaussDB(DWS)迁移 - oracle兼容 --row_number输出结果不一 ...
- 记录一次ScrollViewer控件 经过大量文本数据卡顿的原因
在 WPF 中,CanContentScroll 是 ScrollViewer 控件的一个附加属性,它控制滚动视图中的内容是否按项或像素来滚动. 当 CanContentScroll 设置为 fals ...
- Java的Object类的方法
Java的Object类是所有类的根类,它提供了一些通用的方法.下面是一些常用的Object类方法: 1. equals(Object obj):判断当前对象是否与给定对象相等.默认情况下,equal ...
- Hugging News #0616: 有几项非常重要的合作快来围观、最新中文演讲视频回放发布!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 快速取模算法(Barrett Reduction)
原理:取模运算低效的原因本质是除法运算的低效.如果能将除法变成其它运算就可以加速.具体地,将除以任意数转化成"乘一个数.除以一个 \(2^k\) "(取 \(2^{62}\) 即可 ...
- vue前端预览pdf并加水印、ofd文件,控制打印、下载、另存,vue-pdf的使用方法以及在开发中所踩过的坑合集
根据公司的实际项目需求,要求实现对pdf和ofd文件的预览,并且需要限制用户是否可以下载.打印.另存pdf.ofd文件,如果该用户可以打印.下载需要控制每个用户的下载次数以及可打印的次数.正常的预览p ...
- Python运维开发之路《模块》
一.模块 1. 模块初识 模块定义:模块(module),通常也被称为库(lib,library),是一个包含所有你定义的函数和变量的文件,其后缀名是.py.模块可以被别的程序引入,以使用该模块中 ...
- Spring原理之web.xml加载过程
web.xml是部署描述文件,它不是Spring所特有的,而是在Servlet规范中定义的,是web应用的配置文件.web.xml主要是用来配置欢迎页.servlet.filter.listener等 ...