从内部剖析C# 集合之--Dictionary
Dictionary和hashtable用法有点相似,他们都是基于键值对的数据集合,但实际上他们内部的实现原理有很大的差异,
先简要概述一下他们主要的区别,稍后在分析Dictionary内部实现的大概原理。
区别:1,Dictionary支持泛型,而Hashtable不支持。
2,Dictionary没有装填因子(Load Facto)概念,当容量不够时才扩容(扩容跟Hashtable一样,也是两倍于当前容量最小素数),Hashtable是“已装载元素”与”bucket数组长度“大于装载因子时扩容。
3,Dictionary内部的存储value的数组按先后插入的顺序排序,Hashtable不是。
4,当不发生碰撞时,查找Dictionary需要进行两次索引定位,Hashtable需一次,。
Dictionary采用除法散列法来计算存储地址,想详细了解的可以百度一下,简单来说就是其内部有两个数组:buckets数组和entries数组(entries是一个Entry结构数组),entries有一个next用来模拟链表,该字段存储一个int值,指向下一个存储地址(实际就是bukets数组的索引),当没有发生碰撞时,该字段为-1,发生了碰撞则存储一个int值,该值指向bukets数组.
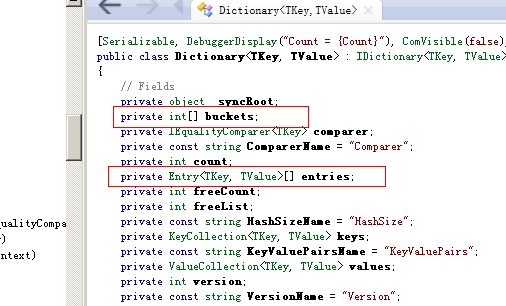

下面跟上次一样,按正常使用Dictionary时,看内部是如何实现的。
一,实例化一个Dictionary, Dictionary<string,string> dic=new Dictionary<string,string>();
a,调用Dictionary默认无参构造函数。
b,初始化Dictionary内部数组容器:buckets int[]和entries<T,V>[],分别分配长度3。(内部有一个素数数组:3,7,11,17....如图: );
);
二,向dic添加一个值,dic.add("a","abc");
a,将bucket数组和entries数组扩容3个长度。
b,计算"a"的哈希值,
c,然后与bucket数组长度(3)进行取模计算,假如结果为:2
d,因为a是第一次写入,则自动将a的值赋值到entriys[0]的key,同理将"abc"赋值给entriys[0].value,将上面b步骤的哈希值赋值给entriys[0].hashCode,
entriys[0].next 赋值为-1,hashCode赋值b步骤计算出来的哈希值。
e,在bucket[2]存储0。
三,通过key获取对应的value, var v=dic["a"];
a, 先计算"a"的哈希值,假如结果为2,
b,根据上一步骤结果,找到buckets数组索引为2上的值,假如该值为0.
c, 找到到entriys数组上索引为0的key,
1),如果该key值和输入的的“a”字符相同,则对应的value值就是需要查找的值。
2) ,如果该key值和输入的"a"字符不相同,说明发生了碰撞,这时获取对应的next值,根据next值定位buckets数组(buckets[next]),然后获取对应buckets上存储的值在定位到entriys数组上,......,一直到找到为止。
3),如果该key值和输入的"a"字符不相同并且对应的next值为-1,则说明Dictionary不包含字符“a”。
Dictionary里的其他方法就不说了,各位可以自己去看源码,下面来通过实验来对比Hashtable和Dictionary的添加和查找性能,
1,添加元素速度测评。
循环5次,每次内部在循环10次取平均值,PS:代码中如有不公平的地方望各位指出,本人知错就改。
a,值类型
static void Main(string[] args)
{
for (int i = ; i < ; i++)
{
Console.WriteLine(string.Format("第{0}次执行:", i + ));
Add();
Console.WriteLine("-------华丽的分分隔线---------");
} Console.ReadKey();
}
public static void Add()
{
Hashtable ht = new Hashtable();
Stopwatch st = new Stopwatch(); long ticks1 = ;
for (int j = ; j < ; j++)
{
st.Reset();
st.Start();
for (int i = ; i < ; i++)
{
ht.Add(i, i);
}
st.Stop();
ticks1 += st.ElapsedTicks;
ht.Clear();
} Console.WriteLine(string.Format("Hashtable添加:{0}个元素,消耗:{1}", , ticks1 / )); Dictionary<int, int> dic = new Dictionary<int, int>();
ticks1 = ;
for (int j = ; j < ; j++)
{
st.Reset();
st.Start();
for (int i = ; i < ; i++)
{
dic.Add(i, i);
}
st.Stop();
ticks1 += st.ElapsedTicks;
dic.Clear();
} Console.WriteLine(string.Format("Dictionary添加:{0}个元素,消耗:{1}", , st.ElapsedTicks));
}
结果:
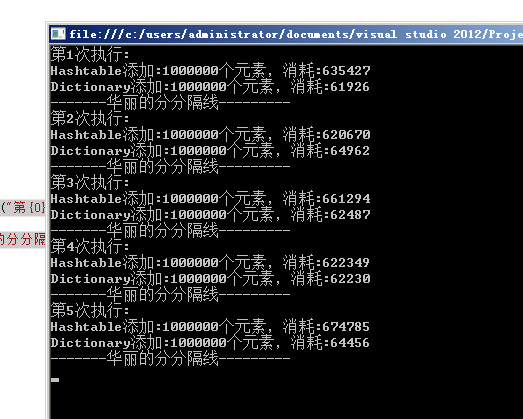
通过运行结果来看,HashTable 速度明显慢于Dictionary,相差一个数量级。我个人分析原因可能为:
a,Hashtable不支持泛型,我向你添加的int类型会发生装箱操作,而Dictionary支持泛型。
b,Hashtable在扩容时会先new一个更大的数组,然后将原来的数据复制到新的数组里,还需对新数组里的key重新哈希计算(这可能是最性能影响最大的因素)。而Dictionary不会这样。
b,引用类型
static void Main(string[] args)
{
for (int i = ; i < ; i++)
{
Console.WriteLine(string.Format("第{0}次执行",i+));
Add();
Console.WriteLine("--------华丽的分隔线------");
} Console.ReadKey();
} public static void Add()
{
Hashtable ht = new Hashtable();
Stopwatch st = new Stopwatch(); long ticks1 = ;
for (int j = ; j < ; j++)
{
st.Reset();
st.Start();
for (int i = ; i < ; i++)
{
ht.Add(i.ToString(), i.ToString());
}
st.Stop();
ticks1 += st.ElapsedTicks;
ht.Clear();
} Console.WriteLine(string.Format("Hashtable添加:{0}个元素,消耗:{1}", , ticks1 / )); Dictionary<string, string> dic = new Dictionary<string, string>();
ticks1 = ;
for (int j = ; j < ; j++)
{
st.Reset();
st.Start();
for (int i = ; i < ; i++)
{
dic.Add(i.ToString(), i.ToString());
}
st.Stop();
ticks1 += st.ElapsedTicks;
dic.Clear();
} Console.WriteLine(string.Format("Dictionary添加:{0}个元素,消耗:{1}", , st.ElapsedTicks));
}

Dic速度还是比Hashtable快,但没有值类型那么明显,这个测试可能有不准的地方。
2,查找速度测评(两种情况:值类型和引用类型)
1 值类型
static void Main(string[] args)
{ // GetByString(); GetByInt(); Console.ReadKey();
} public static void GetByInt()
{
//Hashtable
Hashtable hs = new Hashtable();
Dictionary<int, int> dic = new Dictionary<int, int>(); for (int i = ; i < ; i++)
{
hs.Add(i, i);
dic.Add(i, i);
}
long ticks = ;
Stopwatch st = new Stopwatch();
st.Reset();
for (int i = ; i < ; i++)
{
st.Start();
var result = hs[+i];
st.Stop();
ticks += st.ElapsedTicks;
st.Reset();
}
Console.WriteLine(string.Format("Hashtable查找10次,平均消耗:{0}", (float)ticks / )); //Dictionary
ticks = ;
st.Reset();
for (int i = ; i < ; i++)
{
st.Start();
var result = dic[i];
st.Stop();
ticks += st.ElapsedTicks;
st.Reset();
}
Console.WriteLine(string.Format("Dictionary查找10次,平均消耗:{0}", (float)ticks / ));
}
运行结果

2,引用类型
static void Main(string[] args)
{
GetByString(); Console.ReadKey();
} public static void GetByString()
{
//Hashtable
Hashtable hs = new Hashtable();
Dictionary<string, string> dic = new Dictionary<string, string>(); for (int i = ; i < ; i++)
{
hs.Add(i.ToString(), i.ToString());
dic.Add(i.ToString(), i.ToString());
}
long ticks = ;
Stopwatch st = new Stopwatch();
st.Reset();
string key = "";
for (int i = ; i < ; i++)
{
st.Start();
var result = hs[key];
st.Stop();
ticks += st.ElapsedTicks;
st.Reset();
}
Console.WriteLine(string.Format("Hashtable查找10次,平均消耗:{0}", (float)ticks / )); //Dictionary
ticks = ;
st.Reset();
for (int i = ; i < ; i++)
{
st.Start();
var result = dic[key];
st.Stop();
ticks += st.ElapsedTicks;
st.Reset();
}
Console.WriteLine(string.Format("Dictionary查找10次,平均消耗:{0}", (float)ticks / ));
}
运行结果

根据上面实验结果可以得出:
a,值类型,Hashtable和Dictionary性能相差不大,Hashtable稍微快于Dictionary.
b,引用类型:Hashtable速度明显快于Dictionary。
PS:以上是个人不成熟观点,如果错误请各位指出,谢谢,下篇介绍 SortedList 集合。
另:公司最近招聘.net和java程序员若干,如各位有找工作打算的,请发简历到wangjun@tonglukuaijian.com。
公司在上海闵行浦江智谷。
从内部剖析C# 集合之--Dictionary的更多相关文章
- 从内部剖析C#集合之HashTable
计划写几篇文章专门介绍HashTable,Dictionary,HashSet,SortedList,List 等集合对象,从内部剖析原理,以便在实际应用中有针对性的选择使用. 这篇文章先介绍Hash ...
- 从内部剖析C# 集合之---- HashTable
这是我在博客园的第一篇文章,写的不好或有错误的地方,望各位大牛指出,不甚感激. 计划写几篇文章专门介绍HashTable,Dictionary,HashSet,SortedList,List 等集合对 ...
- C#泛型集合之Dictionary<k, v>使用技巧
1.要使用Dictionary集合,需要导入C#泛型命名空间 System.Collections.Generic(程序集:mscorlib) 2.描述 1).从一组键(Key)到一组值(Value) ...
- Python开发【数据结构】:字典内部剖析
字典内部剖析 开篇先提出几个疑问: 所有的类型都可以做字典的键值吗? 字典的存储结构是如何实现的? 散列冲突时如何解决? 最近看了一些关于字典的文章,决定通过自己的理解把他们写下来:本章将详细阐述上面 ...
- 集合Hashtable Dictionary Hashset
#region Dictionary<K,V> Dictionary<string, Person> dict = new Dictionary<string, Pers ...
- C#基础精华03(常用类库StringBuilder,List<T>泛型集合,Dictionary<K , V> 键值对集合,装箱拆箱)
常用类库StringBuilder StringBuilder高效的字符串操作 当大量进行字符串操作的时候,比如,很多次的字符串的拼接操作. String 对象是不可变的. 每次使用 System. ...
- 字典与集合(Dictionary与Collection)
Dictionary对象将替换Collection对象,并提供附加的语言从而使增加和删除记录的速度比以前提高三倍 虽然Visual Basic 6.0只有很少的新特点,但是具有某些功能强大的新的对象模 ...
- Spring 依赖注入 基于构造函数、设值函数、内部Beans、集合注入
Spring 基于构造函数的依赖注入_w3cschool https://www.w3cschool.cn/wkspring/t7n41mm7.html Spring 基于构造函数的依赖注入 当容器调 ...
- C# 集合之Dictionary详解
开讲. 我们知道Dictionary的最大特点就是可以通过任意类型的key寻找值.而且是通过索引,速度极快. 该特点主要意义:数组能通过索引快速寻址,其他的集合基本都是以此为基础进行扩展而已. 但其索 ...
随机推荐
- MySQL创建/删除/清空表,添加/删除字段
创建表: create table tablename (column_name column_type); create table table_name( id int not null auto ...
- Linux下Openssl的安装全过程
第一章 1.下载地址:http://www.openssl.org/source/ 下一个新版本的OpenSSL,我下的版本是:openssl-1.0.0e.tar.gz 可以通过#wget http ...
- UNIX V6内核源码剖析——进程
进程的概念 1. 什么是进程 2. 进程的并行执行 3. 进程的运行状态 4. 用户模式和内核模式 cpu具有2种模式——内核模式和用户模式,通过PSW来切换. 切换时, 映射到虚拟地址的物理内存区域 ...
- J2EE综合:如何处理大数据量的查询
在实际的任何一个系统中,查询都是必不可少的一个功能,而查询设计的好坏又影响到系统的响应时间和性能这两个要害指标,尤其是当数据量变得越来越大时,于是如何处理大数据量的查询成了每个系统架构设计时都必须面对 ...
- 关于JFace中的TableViewer和TreeViewer中的
TableViewer类 构造方法摘要: 方法摘要: 在做的这几个练习中,发现,getTable(),refresh(),remove(),setSelection()方法经常使用. TreeView ...
- app测试点
手机上的app分为基于HTML5的app(类似于pc上的b/S应用)和本地app(类似于C/S结构). 所以测试上我们也可以充分吸收web的b/s和c/s测试经验.但是不同于pc上的应用测试,手机上的 ...
- php的传值和传址
有些情况下,可能希望在函数体内对参数的修改在函数体外也能反映; 使用引用传递参数要在参数前加上&符号; 例子: <?php $a=5; function show(&$a){ ...
- MidPayinfoVO
package nc.vo.arap.payablebill; import nc.vo.pub.SuperVO; import nc.vo.pub.lang.UFDate; import nc.vo ...
- system.badimageformatexception 未能加载文件或程序集
今天在调用dll文件的时候发现这样一个错误. system.badimageformatexception 未能加载文件或程序集. 发现项目CPU默认Any CPU,我的系统是X64,将 ...
- jsf使用spring注入的bean
jsf的后台bean中使用spring定义的service,需要使用@ManagedProperty,并且要具有该属性的getter/setter方法. package cn.catr.lm.idc. ...