SHELL网络爬虫实例剖析--转载
前天简单分享了用 shell 写网络爬虫的一些见解,今天特地把代码发出来与51博友分享,还是那句话,爱技术、爱开源、爱linux。
针对脚本的注解和整体构思,我会放到脚本之后为大家详解。
#!/bin/bash
#
# This script is used to grab the data on the specified industry websites
# Written by sunsky
# Mail : @qq.com
# Date : -- ::
# if [ `echo $UID` != ];then
echo 'Please use the root to execute the script!'
fi
if [ ! -f /dataimg/years ];then
echo 'Please give date file, the file path for/dataimg/years .'
fi
if [ ! -d $TMP_DIR ];then
mkdir -p $TMP_DIR
fi
if [ ! -d $URL_MD5_DIR ];then
mkdir -p $URL_MD5_DIR
fi
if [ ! -d $HTML_DIR ];then
mkdir -p $HTML_DIR
fi ROOT_DIR="/dataimg" # 指定脚本运行根目录
TMP_DIR="$ROOT_DIR/tmp" # 生成商品详细页url之前的临时数据存放目录
URL_MD5_DIR="$ROOT_DIR/url_md5" # 记录商品详细页url的MD5值的目录
HTML_DIR="$ROOT_DIR/html" # 存放下载下来的商品详细页目录
URL_MD5="$URL_MD5_DIR/md5.$year" # 负责记录商品详细页url的md5值
WEB_URL="https://www.redhat.sx/" # 所爬网站的主页url
REPORT="$ROOT_DIR/report" # 负责记录采集的url综合信息
CURL="curl -A 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.102 Safari/537.36' --referer http://www.redhat.sx"
OPT0="/dataimg/years" # 年份信息
OPT1="$TMP_DIR/${X1_MD5}" # 品牌信息
OPT2="$TMP_DIR/${X1_MD5}_${X2_MD5}" # 车型信息
OPT3="$TMP_DIR/${X1_MD5}_${X2_MD5}_${X3_MD5}" # 装饰信息
OPT4="$TMP_DIR/${X1_MD5}_${X2_MD5}_${X3_MD5}_${X4_MD5}" # 部位分类信息
OPT5="$TMP_DIR/${X1_MD5}_${X2_MD5}_${X3_MD5}_${X4_MD5}_${URL_LIST_MD5}" # 商品详情页url信息 FIFO_FILE="/tmp/$$.fifo"
mkfifo $FIFO_FILE
exec <>$FIFO_FILE
rm -f $FIFO_FILE num=
for ((i=;i<$num;i++));do
echo
done >& while read X1;do
{
URL1="${WEB_URL}/model/YMMTSelects.cfc?method=getMakes&PassYear=$X1"
X1_MD5=`echo $URL1|cksum|cut -d' ' -f1`
if ! ls $OPT1 >&/dev/null;then
$CURL -s $URL1|awk 'BEGIN{RS="<"}{print $0}'|awk -F'>' '{print $2}'|sed '1,9d'|sed '$d'|grep -v '^$' > $OPT1
fi
while read X2;do
X2=`echo $X2|sed 's# #%20#g'`
URL2="${URL1}&PassMakeName=$X2"
#X2_MD5=`echo $URL|cksum|cut -d' ' -f1`
if ! ls $OPT2 >&/dev/null;then
$CURL -s $URL2|awk 'BEGIN{RS="<"}{print $0}'|awk -F'>' '{print $2}'|sed '1,6d'|sed '$d'|grep -v '^$' > $OPT2
fi
while read X3;do
X3=`echo $X3|sed 's#[[:space:]]#%20#g'`
URL3="${URL2}&PassModel=$X3"
X3_MD5=`echo $URL3|cksum|cut -d' ' -f1`
if ! ls $OPT3 >&/dev/null;then
$CURL -s $URL3|sed 's#[[:space:]]##g'|awk 'BEGIN{RS="<|=|>"}{print $0}'|egrep '^[0-9]+$' > $OPT3
fi
while read X4;do
X4=`echo $X4|sed 's# #%20#g'`
URL4="${URL3}&PassVehicleID=$X4"
X4_MD5=`echo $URL4|cksum|cut -d' ' -f1`
if ! ls "${OPT4}" >&/dev/null;then
$CURL -s $URL4|awk 'BEGIN{RS="<"}{print $0}'|awk -F'[>;]' '{print $2}'|sed -e '1,3d' -e '$d' -e '/^$/d' > $OPT4
fi
while read X5;do
X5=`echo $X5|sed 's# #%20#g'`
URL_LIST="${WEB_URL}index.cfm?fuseaction=store.sectionSearch&YMMTyears=$X1&YMMTmakenames=$X2&YMMTmodelnames=$X3&YMMTtrimnames=$X4&YMMTsectionnames=$X5"
URL_LIST_MD5=`echo "$URL_LIST"|md5sum|awk '{print $1}'`
if ! grep -q $URL_LIST_MD5 "$URL_MD5" ;then
$CURL -s "$URL_LIST" > "$URL_MD5_DIR/$URL_LIST_MD5"
NUM=`grep 'View page' "$URL_MD5_DIR/$URL_LIST_MD5"|wc -l`
NUM2=$(($NUM/))
echo > $OPT5
grep 'a href="index.cfm?fuseaction=store.PartInfo&PartNumbe' "$URL_MD5_DIR/$URL_LIST_MD5"|cut -d'"' -f2 > $OPT5
while [ $NUM2 -ge ];do
URL_LIST=`grep "View page $NUM2" "$URL_MD5_DIR/$URL_LIST_MD5"|awk -F'[" ]' '{a[$9]=$9}END{for(i in a)print a[i]}'`
$CURL -s "$URL_LIST"|grep 'a href="index.cfm?fuseaction=store.PartInfo&PartNumbe'|cut -d'"' -f2 >> $OPT5
NUM2=$(($NUM2-))
done
echo $URL_LIST_MD5 >> "$URL_MD5"
fi
while read X6;do
URL_DETAIL="${WEB_URL}${X6}"
URL_DETAIL_MD=`echo $URL_DETAIL|md5sum|awk '{print $1}'`
if ! grep -q $URL_DETAIL_MD "$URL_MD5" >&/dev/null;then # 该判断以商品列表详细页URL的md5值为基准,负责URL的重复项判定
$CURL -s "$URL_DETAIL" > "$HTML_DIR/$URL_DETAIL_MD"
LABEL=`grep 'diagram-label' "$HTML_DIR/$URL_DETAIL_MD"|awk -F'[<>]' '{print $5}'` # 商品标签
GIF_URL=`grep -B partInfo "$HTML_DIR/$URL_DETAIL_MD"|grep -o "https.*gif"|awk '{a=$0}END{print a}'` # 产品对应的图片URL
PRODUCT_ID=`grep 'productID' "$HTML_DIR/$URL_DETAIL_MD"|awk -F'[<>]' '{print $3}'` # 产品零件号码
GIFILE=${GIF_URL#*/} # 去除了https:/后的图片URL信息,as:/a/b.gif
GIF_IMG="${ROOT_DIR}${GIFILE}" # 图片存到本地后的绝对路径,as:/dataimg/a/b.gif
U4=`grep -B '<!-- start opentop -->' "$HTML_DIR/$URL_DETAIL_MD"|grep javascript|awk -F'[<>]' '{print $3}'`
! ls $GIF_IMG >& /dev/null && wget -q -m -k -P "$ROOT_DIR" "$GIF_URL"
echo $URL_DETAIL_MD >> "$URL_MD5"
echo "$(date +%m%d%T)+++$X1+++$X2+++$X3+++$U4+++$X5+++$URL_DETAIL+++$URL_DETAIL_MD+++$LABEL+++$PRODUCT_ID+++$GIF_IMG+++$URL_LIST" >> "$REPORT"
fi
done < $OPT5 # 传入商品详细列表url信息,进行循环
done < $OPT4 # 传入产品部位分类信息,进行循环
done < $OPT3 # 传入装饰信息,进行循环
done < $OPT2 # 传入车型信息,进行循环
done < $OPT1 # 传入品牌信息,进行循环
echo >&
}&
done < $OPT0 # 传入年份信息,进行循环 wait exec <&-
OK!
以上就是脚本的全部内容,整体脚本主要包含了组合目标URL和抓取目标URL两个大方向,围绕这两个大方向,主要是使用 curl 来做数据抓取,是用sed、awk、grep、cut来做兴趣数据的抽取。
由于所要抓取的目标URL必须经过几个选项匹配,最终才能得到想要结果,因此我们在抓取目标URL之前添加了组合目标URL这一操作。整体这2个方向,我通过多层的while循环嵌套,来实现对参数的复用和一层一层的输入挖掘。
为了优化速度以及控制速度,采用了 shell 的多进程和数据智能判重的方式。
采用 shell 的多进程目的是为了增大操作数来缩短整体完成时间,提高抓取效率。
shell 多进程主要依托 循环 + { } + & 来实现。如果多进程的进程数量有指定数值,那么我们可以使用for和while都而已,如果多进程的进程数量没有指定数值,那么我们最好使用while循环语句。通过将 { }& 嵌套在循环中实现将 {}内的命令群组放到后台去自动执行,然后完成本次 { }& 操作,使得循环可以进入下一次。
以上并未实现该shell 在后台开启进程数的控制,假设你的需要执行一万次,如果你未控制速度,就可能会导致直接触发着一万次操作,同时放到后台执行,这样对系统是致命的伤害。另一方面,作为爬虫,你对目标网站的并发量也不能太大。出于这两方面的考虑,我们需要控制 shell 多进程每次放入后台执行的数量。针对这一行为,我们主要通过文件描述符来实现。通过新建一临时管道文件,然后为该文件打开一个文件描述符,并为其传递指定数量的空行(本文传递了10个空行),这样做的目的是为了实现对进程并发量的控制。接着,在下面循环中, { }&操作的前面使用read -u9(这里9为本文使用的文件描述符)来从9这个文件描述符中获取一行,如果获取到就能继续往下执行,如果获取不到就在这里等待。
通过以上的2者结合,就能实现对 shell 多进程的智能管控。
采用数据智能判重的目的在于,在脚本调试中发现速度的执行瓶颈在于curl的速度,即网络速度,因此一旦脚本异常中断后,恢复之后,又要重复进行curl操作,这样就极大增加了脚本执行时间。因此通过智能判重,完美实现了curl时间消耗过久的以及数据重复采集的问题。以下是数据只能判重的逻辑图:
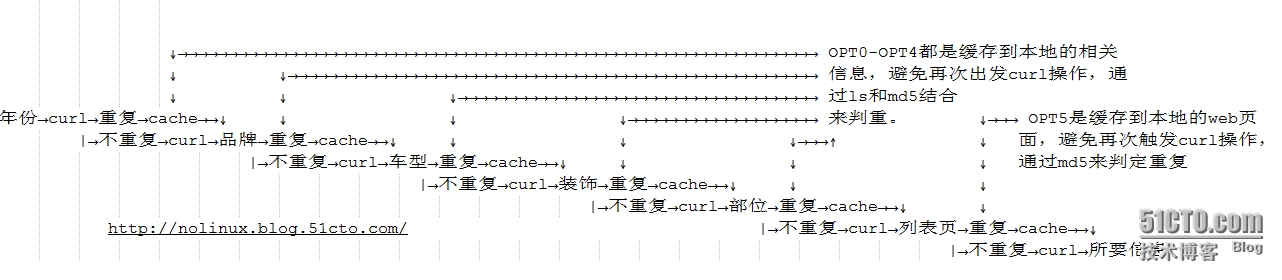
针对脚本中变量的取值意义,我已经在上面的脚本中进行了详细的注释,这里不在复述。
其它细枝末节的一些使用方法和技巧,这里不再一一解释。对 shell 感兴趣的朋友可以和我一起交流,一起进步。
本文出自 “Not Only Linux” 博客,请务必保留此出处http://nolinux.blog.51cto.com/4824967/1552472
SHELL网络爬虫实例剖析--转载的更多相关文章
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例
python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例 新浪爱彩双色球开奖数据URL:http://zst.aicai.com/ssq/openInfo/ 最终输出结果格 ...
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- crawler4j:轻量级多线程网络爬虫实例
crawler4j是Java实现的开源网络爬虫.提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫. 下面实例结合jsoup(中文版API),javacvs 爬取自如租房网(http://sh ...
- Python ===if while for语句 以及一个小小网络爬虫实例
if分支语句 >>> count=89 >>> if count==89: print count 89 #单分支 ...
- Pyhton网络爬虫实例_豆瓣电影排行榜_BeautifulSoup4方法爬取
-----------------------------------------------------------学无止境------------------------------------- ...
- Pyhton网络爬虫实例_豆瓣电影排行榜_Xpath方法爬取
-----------------------------------------------------------学无止境------------------------------------- ...
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
随机推荐
- 【转】那些好用的iOS开发工具
原文:http://www.devtang.com/blog/2014/06/29/ios-dev-tools/ 前言 从苹果发明iPhone起,AppStore上的一个又一个类似flappy bir ...
- caption标签,为表格添加标题和摘要
表格还是需要添加一些标签进行优化,可以添加标题和摘要.代码如下: 摘要 摘要的内容是不会在浏览器中显示出来的.它的作用是增加表格的可读性(语义化),使搜索引擎更好的读懂表格内容,还可以使屏幕阅读器更好 ...
- sqlserver2008附加数据库——错误3415
权限问题, 在其文件,右击属性>安全>编辑>添加>加一个everyone单击确定>其完全控制, 这样给每个用户权限 ---来自凌波小屋----冯和超笔记-----
- 解决tomcat占用8080端口问题
在dos下,输入 netstat -ano|findstr 8080 //说明:查看占用8080端口的进程 显示占用端口的进程 askkill /pid 44464 /f //说明,运 ...
- 如何用angularjs制作一个完整的表格之一__创建简单表格
初步接手人生的第一个项目,需要用angularjs制作表格和实现各种功能,因此遇到了各种问题和以前不熟悉的知识点,在此记录下来,以供大家学习交流,解决方式可能并不完善或符合规范,如果大家有更好的方式欢 ...
- 修改PHP的默认时区
每个地区都有自己的本地时间,在网上及无线电通信中,时间的转换问题显得格外突出.整个地球分为24个时区,每个时区都有自己的本地时间.在国际无线电或网络通信场合,为了统一起见,使用一个统一的时间,成为通用 ...
- 以k个元素为一组反转单链表
Example: input: 1->2->3->4->5->6->7->8->NULL and k = 3 output:3->2->1- ...
- IDA6.6调试安卓程序配置教程
1.把ida 目录下android_server传到设备的 /data/local/tmp/ cmd执行adb shell 进入模拟器命令行 su cd /data/local/tmp/ chmod ...
- dict两种遍历方法
采用for...in...遍历: >>> for i in dd: ... print("%s:%s"%(i,dd[i])) ... :chen :hang :w ...
- TableView_编辑 实例代码
@interface MJViewController () <UITableViewDataSource, UITableViewDelegate> { NSMutableArray * ...