SQL 强化练习 (五)
果然日常练练这些 sql 是非常有必要的, 这几日的报表开发, 用一款过程软件 fineReport, 相对于我之前用 Tableau 来做报表, 这个帆软, 确实更加适合中国人哦, 而Tableau只是专门用来展示而已. 我感觉 FR, 还是有一定门槛的, 首先就是 SQL, 大量的操作都是需要写 sql 来完成的, 我还蛮喜欢的其实, 很灵活的嘛. 其实是要理解 WEB, 比如做填报, 就是要先弄个页面, 然后设计数据库, 单元格值回写数据库, 数据库查询报表展示... 这个就是 WEB 呀, 反正我觉得还是有些复杂的, 但核心技能 SQL 是必须的, 虽然这里用的更多是 查询方面. 还是得不断练习...
表关系
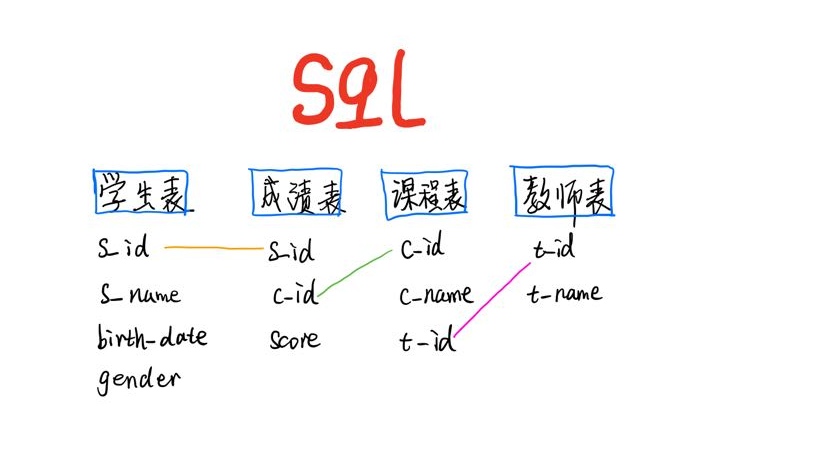
深深可在脑海中, 我感觉, 其实业务中也只不过是, 字段变多了, 表结构复杂一些而已, 本质是还是表呀.
需求 01
查询课程编号为 "0002" 的总成绩, 平均成绩, 人数等.
分析
这就是用来练习下聚合函数(sum, count, avg..)
select
sum(score) as "总成绩",
avg(score) as "平均成绩",
count(score) as "成绩总份数",
count(distinct s_id) as "学生人数"
from score
where c_id = "0002";
+-----------+--------------+-----------------+--------------+
| 总成绩 | 平均成绩 | 成绩总份数 | 学生人数 |
+-----------+--------------+-----------------+--------------+
| 230 | 76.6667 | 3 | 3 |
+-----------+--------------+-----------------+--------------+
感觉其实这个查询是没啥意义的, 就选一个一门课, 有啥号看的呢, 倒不如, 查看所有的课程的信息多好.
select
c_id as "课程编号",
sum(score) as "总成绩",
avg(score) as "平均成绩",
count(score) as "成绩总份数",
count(distinct s_id) as "学生人数"
from score
group by c_id;
+--------------+-----------+--------------+-----------------+--------------+
| 课程编号 | 总成绩 | 平均成绩 | 成绩总份数 | 学生人数 |
+--------------+-----------+--------------+-----------------+--------------+
| 0001 | 160 | 80.0000 | 2 | 2 |
| 0002 | 230 | 76.6667 | 3 | 3 |
| 0003 | 259 | 86.3333 | 3 | 3 |
+--------------+-----------+--------------+-----------------+--------------+
这样, 看全部的数据, 我感觉这更加贴和业务一点. 值得主要的是 group by 的用法, select 一般都先是这个 聚合字段的值, 然后再是一些聚合函数字段. 不要再select 放跟 分组字段 没有关系的字段. 这样经常会引发歧义和直接报错, group by -> aggregation... 这是必须要掌握的哦. 其次, 就是 group by 后面不要跟 where, 根本没有意义, where 必然是要放在 group by 之前呀, 而对于 分组后的过滤 用 having.
正好来练习一下: 用分组过滤 having 的方式来查看 "0002" 的信息
select
c_id as "课程编号",
sum(score) as "总成绩",
avg(score) as "平均成绩",
count(score) as "成绩总份数",
count(distinct s_id) as "学生人数"
from score
group by c_id having c_id = "0002";
一样的结果
+--------------+-----------+--------------+-----------------+--------------+
| 课程编号 | 总成绩 | 平均成绩 | 成绩总份数 | 学生人数 |
+--------------+-----------+--------------+-----------------+--------------+
| 0002 | 230 | 76.6667 | 3 | 3 |
+--------------+-----------+--------------+-----------------+--------------+
1 row in set (0.00 sec)
我感觉我每天都是在干这类似的 筛选字段, 分组聚合的活. 原本我以为会了 Pandas 就无所畏惧, 为所欲为, 结果, 工作中更多是要去从数据库中查询数据 用sql 的方式来查询返回, 而非用 Python 来搞, 我感觉 Python 我搞得更多的是一些线下的表格数据, 什么 Excel, csv, json... 无敌强, 但更多还是用 sql 来查询数据会更通用和专业些.
需求 02
查询 所有课程成绩小于 90 分 的学生学号, 姓名
分析
先用学号进行 group by (结合 where 成绩 < 90) 的课程数量;
然后再统计, 该学号总共选了几门课, 这样一比较就好啦.
我还是先自己肉眼给看一眼:
select
s_id as "学号",
c_id as "课程号",
score as "成绩"
from score
group by s_id, c_id;
+--------+-----------+--------+
| 学号 | 课程号 | 成绩 |
+--------+-----------+--------+
| 0001 | 0001 | 80 |
| 0001 | 0002 | 90 |
| 0001 | 0003 | 99 |
| 0002 | 0002 | 60 |
| 0002 | 0003 | 80 |
| 0003 | 0001 | 80 |
| 0003 | 0002 | 80 |
| 0003 | 0003 | 80 |
+--------+-----------+--------+
8 rows in set (0.00 sec)
这样一看, 都是满足的呀.
-- 首先呢, 先看看每个人成绩小于 90 分的 课有几门
select
s_id as "学号",
count(c_id) as "小于90的课数"
from score
where score < 90
group by s_id;
+--------+-------------------+
| 学号 | 小于90的课数 |
+--------+-------------------+
| 0001 | 1 |
| 0002 | 2 |
| 0003 | 3 |
+--------+-------------------+
3 rows in set (0.00 sec)
-- 然后呢, 再看看每个人一个选课几门课
select
s_id as "学号",
count(c_id) as "选课数"
from score
group by s_id;
+--------+-----------+
| 学号 | 选课数 |
+--------+-----------+
| 0001 | 3 |
| 0002 | 2 |
| 0003 | 3 |
+--------+-----------+
3 rows in set (0.00 sec)
再将这两个表一拼 inner join 不就美滋滋.. 即 inner 上的学号就是不满足条件的呀
select
a.*,
b.*
from
(
select
s_id as "学号",
count(c_id) as "小于90的课数"
from score
where score < 90
group by s_id) as a
inner join
(
select
s_id as "学号",
count(c_id) as "选课数"
from score
group by s_id) as b
on a.学号= b.学号;
+--------+-------------------+--------+-----------+
| 学号 | 小于90的课数 | 学号 | 选课数 |
+--------+-------------------+--------+-----------+
| 0001 | 1 | 0001 | 3 |
| 0002 | 2 | 0002 | 2 |
| 0003 | 3 | 0003 | 3 |
+--------+-------------------+--------+-----------+
3 rows in set (0.00 sec)
最后来个完整的. 我一般是从里到外的. 不断 select , 面向过程多一些.
select
s_id as "学号",
s_name as "姓名"
from student
where s_id in (
select
a.学号
from
(
select
s_id as "学号",
count(c_id) as "小于90的课数"
from score
where score < 90
group by s_id) as a
inner join
(
select
s_id as "学号",
count(c_id) as "选课数"
from score
group by s_id) as b
on a.学号= b.学号
);
+--------+-----------+
| 学号 | 姓名 |
+--------+-----------+
| 0001 | 王二 |
| 0002 | 星落 |
| 0003 | 胡小适 |
+--------+-----------+
3 rows in set (0.00 sec)
小结
- 聚合函数练习 sum, avg, count + distinct ....这些常见聚合函数的熟练使用呀.
- group by 前的 select 不要放跟 其无关的非聚合字段, 没有意义, where 要置前, 组内过滤用 having
- 复杂查询先理清楚逻辑, 一点点给查出来, 再拼接 Join 再过滤, 子查询等操作, 跟写代码一样的其实
SQL 强化练习 (五)的更多相关文章
- SQL总结(五)存储过程
SQL总结(五)存储过程 概念 存储过程(Stored Procedure):已预编译为一个可执行过程的一个或多个SQL语句. 创建存储过程语法 CREATE proc | procedure pro ...
- 漏洞重温之sql注入(五)
漏洞重温之sql注入(五) sqli-labs通关之旅 填坑来了! Less-17 首先,17关,我们先查看一下页面,发现网页正中间是一个登录框. 显然,该关卡的注入应该为post型. 直接查看源码. ...
- SQL强化(一)保险业务
保险业务 : 表结构 : sql语句 : /*1. 根据投保人电话查询出投保人 姓名 身份证号 所有保单 编号 险种 缴费类型*/SELECTt2.cust_name,t2.idcard,t4.pro ...
- SQL学习笔记五之MySQL索引原理与慢查询优化
阅读目录 一 介绍 二 索引的原理 三 索引的数据结构 四 聚集索引与辅助索引 五 MySQL索引管理 六 测试索引 七 正确使用索引 八 联合索引与覆盖索引 九 查询优化神器-explain 十 慢 ...
- VFP检测SQL Server的五个实例代码
** 需要指出的是,无论下面哪种方式的代码,都需要打开本机的网络共享,否则找不到SQL服务器** 例一 ************************************************ ...
- SQL 实战(五)
一. 将所有to_date为9999-01-01的全部更新为NULL,且 from_date更新为2001-01-01.CREATE TABLE IF NOT EXISTS titles_test ( ...
- sql编程篇 (五) 事务
计算机中的事务 编辑 概念 事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit).事务通常由高级数据库操纵语言或编程语言(如SQL,C++或Java)书写的用 ...
- 防止 jsp被sql注入的五种方法
一.SQL注入简介 SQL注入是比较常见的网络攻击方式之一,它不是利用操作系统的BUG来实现攻击,而是针对程序员编程时的疏忽,通过SQL语句,实现无帐号登录,甚至篡改数据库. 二.SQL注入攻击的总体 ...
- SQL入门经典(五) 之键和约束
这一篇博客主要讲键的创建,约束的创建.修改对象和删除对象. 主键:主键是每行的唯一标识符,必须包含唯一值(因此不能为NULL).由于主键在关系中数据库的重要性,因此它是所有键和约束中最重要的.一个表最 ...
- SQL笔记-第五章,函数
一.数学函数 功能 函数名 用法 绝对值 ABS() 指数 POWER() POWER(FWeight,-0.5) 平方根 SQRT() 求随机数 RAND() 舍入到最 ...
随机推荐
- 史陶比尔Stabli机器人维修小细节
在工业自动化领域,史陶比尔机器人以其卓越的性能和可靠性而著称.然而,即使是尖端的设备,也难免会遇到Stabli机械手故障和问题.对于机器人维护和修理,每一个小细节都显得至关重要. 一.观察 首先,我们 ...
- pnpm 安装和使用
1. 简介 Fast, disk space efficient package manager: Fast. Up to 2x faster than the alternatives (see b ...
- PyCharm一直indexing,且永不停止。
- 搭建个人多机器ssh连接平台
最近新配了个主机,有了多个设备,ssh连接的功能可以优化很多体验,便又开始鼓捣.以前都是windows连各种linux,比较方便:这次是在windows之间,还是小查了好一会儿,留个记录 SSH连接的 ...
- go sync.map的使用
前言 数据竞争是并发情况下,存在多线程/协程读写相同数据的情况,必须存在至少一方写.另外,全是读的情况下是不存在数据竞争的. Go语言中的 map 在并发情况下,只读是线程安全的,同时读写是线程不安全 ...
- 手把手教你安装TrueNas(基础篇)
玩过蜗牛星际,体验过黑群晖系统崩掉导致里面珍藏12t大姐姐全没了(此处有哭声),我技术又菜,自己恢复是不可能恢复的,装的盗版系统,又不可能联系群晖官方售后恢复.于是乎就想要一个稳定.开 ...
- PostgreSQL 密码忘了
许久不登, 倒是把默认的 postgres 用户的密码给忘了... 首先关闭 PostgreSQL. 我这是 Windows 上安装的, 所以到服务 (services.msc) 里关闭. 然后修改配 ...
- GitLab 服务器宕机时的项目代码恢复方法
重要前提:GitLab 数据挂载盘必须能够正常读取,且 /var/opt/gitlab/git-data/repositories 目录下的数据可以完整拷贝. 当 GitLab 服务器意外宕机且没有备 ...
- MCP (Model Context Protocol)初体验:企业数据与大模型融合初探
简介 模型上下文协议(Model Context Protocol,简称MCP)是一种创新的开放标准协议,旨在解决大语言模型(LLM)与外部数据和工具之间的连接问题.它为AI应用提供了一种统一.标准化 ...
- 从零开始:在Qt中使用OpenGL绘制指南
本文只介绍基本的 QOpenGLWidget 和 QOpenGLFunctions 的使用,想要学习 OpenGL 的朋友,建议访问经典 OpenGL 学习网站:LearnOpenGL CN 本篇文章 ...