L3-3、从单轮到链式任务:设计协作型 Prompt 系统
一、链式任务设计的概念与价值
在人工智能应用开发中,单轮对话往往无法满足复杂业务场景的需求。链式任务设计允许我们将复杂问题分解为一系列相互关联的子任务,每个子任务的输出可以作为下一个子任务的输入,从而实现更加复杂和精确的功能。
链式任务的核心价值:
- 复杂问题分解:将难以一次性解决的问题拆分为可管理的小任务
- 专业化处理:每个环节可以针对特定任务进行优化
- 质量控制:在流程的各个环节进行验证和调整
- 可扩展性:轻松添加或修改流程中的特定环节
应用场景示例:
- 多轮对话客服系统
- 分阶段内容生成(如先生成提纲,再扩展详细内容)
- 复杂数据处理和分析流程
- 多模型协同工作的系统
二、Prompt 串联方式:任务流、输出中继、结构约束
链式 Prompt 系统可以通过多种方式进行串联,以下是三种主要方法:
1. 任务流(Task Flow)
任务流是最直接的串联方式,将多个独立的 Prompt 按照预定义的顺序执行,每个任务完成后触发下一个任务。
def task_flow(input_data):
# 第一个任务
result_1 = model.generate(prompt_1 + input_data)
# 第二个任务
result_2 = model.generate(prompt_2 + result_1)
# 第三个任务
final_result = model.generate(prompt_3 + result_2)
return final_result
2. 输出中继(Output Relay)
输出中继不仅传递结果,还可以传递上下文信息、中间状态或元数据,使得后续任务能够了解先前任务的处理过程。
def output_relay(input_data):
# 初始化上下文
context = {"input": input_data, "stage": "initial"}
# 第一个任务
result_1 = model.generate(prompt_1 + context["input"])
context["result_1"] = result_1
context["stage"] = "after_stage_1"
# 第二个任务
result_2 = model.generate(prompt_2 + json.dumps(context))
context["result_2"] = result_2
context["stage"] = "after_stage_2"
# 最终任务
final_result = model.generate(prompt_3 + json.dumps(context))
return final_result
3. 结构约束(Structural Constraints)
结构约束通过预定义的格式或模板确保每个环节的输出能够被下一个环节正确解析和使用。
def structural_constraint(input_data):
# 定义输出格式
output_template = {
"analysis": "",
"key_points": [],
"next_steps": ""
}
# 第一个任务处理分析部分
analysis_prompt = prompt_1 + input_data + "输出格式: " + json.dumps({"analysis": "your analysis here"})
analysis_result = json.loads(model.generate(analysis_prompt))
output_template["analysis"] = analysis_result["analysis"]
# 第二个任务处理关键点
key_points_prompt = prompt_2 + output_template["analysis"] + "输出格式: " + json.dumps({"key_points": ["point1", "point2"]})
key_points_result = json.loads(model.generate(key_points_prompt))
output_template["key_points"] = key_points_result["key_points"]
# 第三个任务生成下一步建议
next_steps_prompt = prompt_3 + json.dumps(output_template) + "输出格式: " + json.dumps({"next_steps": "your suggestions here"})
next_steps_result = json.loads(model.generate(next_steps_prompt))
output_template["next_steps"] = next_steps_result["next_steps"]
return output_template
三、模拟流程构建技巧:客服场景、招聘面试等案例
客服场景模拟
客服场景需要处理多轮对话,同时保持上下文连贯性和问题解决能力。
案例:电商售后服务流程
def customer_service_flow(customer_query):
# 步骤1:问题分类
classification_prompt = f"""
将以下客户查询进行分类:
客户查询: {customer_query}
将查询分为以下类别之一:
- 退款请求
- 产品信息
- 配送问题
- 账户问题
- 其他
仅输出类别名称。
"""
query_type = model.generate(classification_prompt).strip()
# 步骤2:根据类型生成初始回复
response_prompt = f"""
生成对客户查询的专业回复:
客户查询: {customer_query}
查询类型: {query_type}
回复应该:
1. 表达理解客户问题
2. 提供初步解决方案
3. 请求任何必要的额外信息
4. 保持礼貌和专业
仅输出回复内容。
"""
initial_response = model.generate(response_prompt)
return {
"query_type": query_type,
"response": initial_response,
"next_step": "等待客户回复" if "请提供" in initial_response else "问题解决"
}
招聘面试场景
面试流程需要评估候选人的多个维度,并根据回答动态调整后续问题。
def interview_simulation(position, candidate_resume):
# 步骤1:简历分析,生成针对性问题
resume_analysis_prompt = f"""
分析以下候选人简历,生成3个针对{position}职位的技术面试问题:
职位: {position}
简历: {candidate_resume}
问题应该:
1. 与候选人经验相关
2. 测试关键技能
3. 包含一个实际场景问题
以JSON格式输出三个问题。
"""
questions = json.loads(model.generate(resume_analysis_prompt))
# 模拟候选人回答(此处简化,实际使用时会是真实回答)
candidate_answers = []
for q in questions:
# 在实际应用中,这里会等待真实候选人的回答
simulated_answer = f"这是候选人对问题「{q}」的模拟回答"
candidate_answers.append({"question": q, "answer": simulated_answer})
# 步骤2:评估回答
evaluation_prompt = f"""
评估候选人对以下问题的回答:
职位: {position}
面试问答:
{json.dumps(candidate_answers, indent=2)}
对每个回答评分(1-5)并提供简短评价。
最后给出整体评估和是否推荐进入下一轮。
以JSON格式输出结果。
"""
evaluation = json.loads(model.generate(evaluation_prompt))
return evaluation
四、角色协作提示结构:多角色联动如何实现
角色协作模式允许模拟不同专业背景或职责的角色进行协作,共同完成复杂任务。
多角色协作的核心优势
- 专业视角:每个角色专注于自己擅长的领域
- 辩证思考:不同角色可以提供不同观点,形成辩证分析
- 全面性:多角色配合可以覆盖问题的各个方面
角色协作实现方法
1. 串行角色协作
def serial_collaboration(project_description):
roles = [
{"name": "产品经理", "task": "根据项目描述,制定产品需求文档(PRD)"},
{"name": "系统架构师", "task": "根据PRD,设计系统架构"},
{"name": "开发工程师", "task": "根据系统架构,编写实现计划"},
{"name": "测试工程师", "task": "根据实现计划,设计测试用例"}
]
current_output = project_description
results = {}
for role in roles:
role_prompt = f"""
你现在是{role['name']},你的任务是: {role['task']}
前序输出: {current_output}
请基于前序输出完成你的任务。
"""
role_output = model.generate(role_prompt)
results[role["name"]] = role_output
current_output = role_output
return results
2. 并行角色协作
def parallel_collaboration(problem_statement):
roles = [
{"name": "乐观视角", "task": "分析问题的积极方面和机会"},
{"name": "批判视角", "task": "分析问题的风险和挑战"},
{"name": "创新视角", "task": "提出创新的解决思路"},
{"name": "实用视角", "task": "提出实际可行的执行方案"}
]
# 并行获取各角色观点
perspectives = {}
for role in roles:
role_prompt = f"""
你现在代表{role['name']},你的任务是: {role['task']}
问题: {problem_statement}
请从你的视角给出分析。
"""
role_output = model.generate(role_prompt)
perspectives[role["name"]] = role_output
# 综合各角色观点
integration_prompt = f"""
综合以下不同视角的分析,形成全面的解决方案:
问题: {problem_statement}
各视角分析:
{json.dumps(perspectives, indent=2, ensure_ascii=False)}
请给出一个平衡各方观点的最终方案。
"""
final_solution = model.generate(integration_prompt)
return {
"perspectives": perspectives,
"final_solution": final_solution
}
3. 辩论型角色协作
def debate_collaboration(topic, rounds=3):
roles = [
{"name": "正方", "position": "支持"},
{"name": "反方", "position": "反对"}
]
debate_history = []
# 初始立场陈述
for role in roles:
initial_prompt = f"""
你代表{topic}辩论的{role['name']},你的立场是{role['position']}。
请给出你的初始立场陈述,包含3个关键论点。
"""
statement = model.generate(initial_prompt)
debate_history.append({
"round": 0,
"role": role["name"],
"statement": statement
})
# 多轮辩论
for round_num in range(1, rounds + 1):
for i, role in enumerate(roles):
opponent = roles[1-i]
previous_statements = [entry for entry in debate_history if entry["round"] == round_num - 1]
opponent_statement = [s for s in previous_statements if s["role"] == opponent["name"]][0]["statement"]
debate_prompt = f"""
你代表{topic}辩论的{role['name']},你的立场是{role['position']}。
这是第{round_num}轮辩论。
对方在上一轮的陈述:
{opponent_statement}
请针对对方的论点进行反驳,并进一步强化自己的立场。
"""
response = model.generate(debate_prompt)
debate_history.append({
"round": round_num,
"role": role["name"],
"statement": response
})
# 辩论总结
summary_prompt = f"""
总结以下关于"{topic}"的辩论内容:
{json.dumps(debate_history, indent=2, ensure_ascii=False)}
请客观分析双方论点的强弱,并给出此次辩论的整体评价。
不要表明自己支持哪一方。
"""
debate_summary = model.generate(summary_prompt)
return {
"debate_history": debate_history,
"summary": debate_summary
}
五、实际案例:一个多阶段智能流程的 Prompt 构建全流程
下面我们将构建一个内容创作助手系统,该系统通过多个阶段协作完成从构思到最终内容的全流程。这个实例将结合前面介绍的各种技术,并使用 Streamlit 构建交互界面。
内容创作助手系统架构
- 创意构思阶段:生成内容主题和大纲
- 专家反馈阶段:多角色评审和改进建议
- 内容生成阶段:根据大纲和反馈生成完整内容
- 质量优化阶段:润色和调整最终内容
核心代码实现
首先,我们定义系统的核心功能模块:
import openai
import streamlit as st
import json
import time
# 配置OpenAI API(也可以使用其他兼容的API)
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0.7,
)
return response.choices[0].message["content"]
# 第一阶段:创意构思
def ideation_stage(topic_area, target_audience, content_type):
prompt = f"""
作为内容创意专家,请根据以下信息生成内容创意:
主题领域: {topic_area}
目标受众: {target_audience}
内容类型: {content_type}
请提供:
1. 3个引人注目的标题选项
2. 一个详细的内容大纲,包含引言、主要部分和结论
3. 关键的吸引点和价值主张
以JSON格式返回结果。
"""
response = get_completion(prompt)
try:
return json.loads(response)
except:
# 处理非JSON响应
return {
"titles": ["解析错误 - 请重试"],
"outline": "API返回了非JSON格式",
"value_props": []
}
# 第二阶段:专家评审
def expert_review_stage(ideation_result):
roles = [
{"name": "内容营销专家", "focus": "受众吸引力和市场定位"},
{"name": "SEO专家", "focus": "搜索引擎优化和关键词策略"},
{"name": "用户体验专家", "focus": "内容结构和可读性"}
]
reviews = {}
for role in roles:
prompt = f"""
你是一位{role['name']},专注于{role['focus']}。
请评审以下内容创意:
{json.dumps(ideation_result, indent=2, ensure_ascii=False)}
提供:
1. 总体评分(1-10)
2. 3个具体优点
3. 2个改进建议
4. 一个创新想法
以JSON格式返回评审结果。
"""
response = get_completion(prompt)
try:
reviews[role["name"]] = json.loads(response)
except:
reviews[role["name"]] = {
"rating": 0,
"strengths": ["解析错误"],
"improvements": ["请重试"],
"innovation": "API返回了非JSON格式"
}
return reviews
# 第三阶段:内容生成
def content_generation_stage(ideation_result, expert_reviews, selected_title):
prompt = f"""
作为专业内容创作者,根据以下信息创作完整内容:
选定标题: {selected_title}
内容大纲:
{ideation_result['outline']}
专家评审意见:
{json.dumps(expert_reviews, indent=2, ensure_ascii=False)}
请创作一篇完整、引人入胜且结构清晰的内容。
内容应该整合专家的改进建议,并保持专业性和吸引力。
使用markdown格式。
"""
return get_completion(prompt)
# 第四阶段:质量优化
def quality_enhancement_stage(generated_content):
prompt = f"""
作为内容编辑,请优化以下内容:
{generated_content}
请:
1. 检查并修正任何语法或拼写错误
2. 提高表达的清晰度和简洁性
3. 确保标题和小标题吸引人
4. 优化段落和句子结构以提高可读性
5. 增强整体的专业性和说服力
返回优化后的完整内容(使用markdown格式)。
"""
return get_completion(prompt)
Streamlit 交互界面实现
接下来,我们构建一个交互式的 Streamlit 界面,允许用户完成整个内容创作流程:
st.set_page_config(page_title="AI内容创作助手", page_icon="✍️", layout="wide")
st.title("AI内容创作助手:多阶段智能流程演示")
st.markdown("这个应用展示了如何使用链式任务和角色协作来构建复杂的AI应用")
# 侧边栏 - API设置
st.sidebar.header("设置")
api_key = st.sidebar.text_input("OpenAI API Key", type="password")
if api_key:
openai.api_key = api_key
# 主界面 - 分阶段标签页
tab1, tab2, tab3, tab4 = st.tabs(["1. 创意构思", "2. 专家评审", "3. 内容生成", "4. 质量优化"])
# 初始化会话状态
if "ideation_result" not in st.session_state:
st.session_state.ideation_result = None
if "expert_reviews" not in st.session_state:
st.session_state.expert_reviews = None
if "generated_content" not in st.session_state:
st.session_state.generated_content = None
if "enhanced_content" not in st.session_state:
st.session_state.enhanced_content = None
# 阶段1: 创意构思
with tab1:
st.header("第一阶段:创意构思")
col1, col2 = st.columns(2)
with col1:
topic_area = st.text_input("主题领域", placeholder="例如:人工智能、健康饮食、投资策略")
target_audience = st.text_input("目标受众", placeholder="例如:初创企业创始人、健身爱好者、新手投资者")
with col2:
content_type = st.selectbox(
"内容类型",
["博客文章", "社交媒体帖子", "新闻稿", "教程", "电子书章节", "播客脚本"]
)
if st.button("生成创意", key="ideation_btn"):
if not api_key:
st.error("请先在侧边栏设置OpenAI API Key")
elif not topic_area or not target_audience:
st.warning("请填写主题领域和目标受众")
else:
with st.spinner("正在生成创意..."):
st.session_state.ideation_result = ideation_stage(topic_area, target_audience, content_type)
if st.session_state.ideation_result:
st.subheader("创意结果")
st.write("**推荐标题选项:**")
for i, title in enumerate(st.session_state.ideation_result.get("titles", [])):
st.write(f"{i+1}. {title}")
st.write("**内容大纲:**")
st.write(st.session_state.ideation_result.get("outline", ""))
st.write("**价值主张:**")
for prop in st.session_state.ideation_result.get("value_props", []):
st.write(f"- {prop}")
st.success("创意构思完成!请继续到「专家评审」阶段")
# 阶段2: 专家评审
with tab2:
st.header("第二阶段:专家评审")
if not st.session_state.ideation_result:
st.info("请先完成创意构思阶段")
else:
if st.button("获取专家评审", key="review_btn"):
with st.spinner("专家正在评审中..."):
st.session_state.expert_reviews = expert_review_stage(st.session_state.ideation_result)
if st.session_state.expert_reviews:
for role, review in st.session_state.expert_reviews.items():
with st.expander(f"{role} 评审 (评分: {review.get('rating', 'N/A')}/10)"):
st.write("**优点:**")
for strength in review.get("strengths", []):
st.write(f" {strength}")
st.write("**改进建议:**")
for improvement in review.get("improvements", []):
st.write(f" {improvement}")
st.write("**创新想法:**")
st.write(f" {review.get('innovation', 'N/A')}")
st.success("专家评审完成!请继续到「内容生成」阶段")
# 阶段3: 内容生成
with tab3:
st.header("第三阶段:内容生成")
if not st.session_state.expert_reviews:
st.info("请先完成专家评审阶段")
else:
selected_title = st.selectbox(
"选择要使用的标题",
st.session_state.ideation_result.get("titles", ["无标题选项"])
)
if st.button("生成内容", key="generate_btn"):
with st.spinner("正在生成内容...这可能需要一些时间"):
st.session_state.generated_content = content_generation_stage(
st.session_state.ideation_result,
st.session_state.expert_reviews,
selected_title
)
if st.session_state.generated_content:
st.subheader("生成的内容")
st.markdown(st.session_state.generated_content)
st.success("内容生成完成!请继续到「质量优化」阶段")
# 阶段4: 质量优化
with tab4:
st.header("第四阶段:质量优化")
if not st.session_state.generated_content:
st.info("请先完成内容生成阶段")
else:
if st.button("优化内容", key="enhance_btn"):
with st.spinner("正在优化内容质量..."):
st.session_state.enhanced_content = quality_enhancement_stage(
st.session_state.generated_content
)
if st.session_state.enhanced_content:
col1, col2 = st.columns(2)
with col1:
st.subheader("优化前")
st.markdown(st.session_state.generated_content)
with col2:
st.subheader("优化后")
st.markdown(st.session_state.enhanced_content)
# 下载按钮
st.download_button(
label="下载最终内容(Markdown)",
data=st.session_state.enhanced_content,
file_name="ai_generated_content.md",
mime="text/markdown",
)
st.success(" 恭喜!完整内容创作流程已完成")
运行说明
- 安装必要的依赖:
pip install streamlit openai
- 将上述代码保存为
content_creation_assistant.py
import streamlit as st
import json
import time
from typing import Dict, List, Any, Optional, Union, Tuple
from functools import lru_cache
from openai import OpenAI
client = OpenAI(
)
# OpenAI配置
class OpenAIConfig:
DEFAULT_MODEL = "deepseek/deepseek-r1-distill-llama-8b"
DEFAULT_TEMPERATURE = 0.7
API_TIMEOUT = 30
# 配置OpenAI API
@st.cache_data(ttl=3600, show_spinner=False)
def get_completion(prompt: str, model: str = OpenAIConfig.DEFAULT_MODEL) -> str:
"""调用OpenAI API获取响应,使用缓存提高性能
Args:
prompt: 提示词
model: 使用的模型名称
Returns:
模型的文本响应
"""
try:
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
)
return response.choices[0].message.content
except Exception as e:
st.error(f"API调用失败: {str(e)}")
return ""
def parse_json_response(response: str) -> Dict[str, Any]:
"""将API响应解析为JSON格式
Args:
response: API返回的文本响应
Returns:
解析后的JSON对象,如果解析失败则返回错误对象
"""
if not response:
return {"error": "API返回内容为空"}
try:
return json.loads(response)
except json.JSONDecodeError:
# 尝试修复常见的JSON错误
try:
# 有时API返回的JSON格式不标准,尝试添加引号
fixed_response = response.replace("'", "\"")
return json.loads(fixed_response)
except:
# 处理非JSON响应
return {
"error": "无法解析API响应",
"titles": ["解析错误 - 请重试"],
"outline": "API返回了非JSON格式",
"value_props": []
}
# 第一阶段:创意构思
def ideation_stage(topic_area: str, target_audience: str, content_type: str) -> Dict[str, Any]:
"""内容创意构思阶段
Args:
topic_area: 主题领域
target_audience: 目标受众
content_type: 内容类型
Returns:
创意构思结果,包含标题选项、内容大纲和价值主张
"""
prompt = f"""
作为内容创意专家,请根据以下信息生成内容创意:
主题领域: {topic_area}
目标受众: {target_audience}
内容类型: {content_type}
请提供:
1. 3个引人注目的标题选项
2. 一个详细的内容大纲,包含引言、主要部分和结论
3. 关键的吸引点和价值主张
以JSON格式返回结果,格式如下:
{{
"titles": ["标题1", "标题2", "标题3"],
"outline": "详细大纲...",
"value_props": ["价值主张1", "价值主张2", ...]
}}
"""
response = get_completion(prompt)
return parse_json_response(response)
# 第二阶段:专家评审
def expert_review_stage(ideation_result: Dict[str, Any]) -> Dict[str, Dict[str, Any]]:
"""多专家视角评审内容创意
Args:
ideation_result: 第一阶段的创意构思结果
Returns:
各专家的评审结果
"""
roles = [
{"name": "内容营销专家", "focus": "受众吸引力和市场定位"},
{"name": "SEO专家", "focus": "搜索引擎优化和关键词策略"},
{"name": "用户体验专家", "focus": "内容结构和可读性"}
]
reviews = {}
for role in roles:
prompt = f"""
你是一位{role['name']},专注于{role['focus']}。
请评审以下内容创意:
{json.dumps(ideation_result, indent=2, ensure_ascii=False)}
提供:
1. 总体评分(1-10)
2. 3个具体优点
3. 2个改进建议
4. 一个创新想法
以JSON格式返回评审结果,格式如下:
{{
"rating": 评分,
"strengths": ["优点1", "优点2", "优点3"],
"improvements": ["建议1", "建议2"],
"innovation": "创新想法"
}}
"""
response = get_completion(prompt)
result = parse_json_response(response)
if "error" in result:
reviews[role["name"]] = {
"rating": 0,
"strengths": ["API返回错误"],
"improvements": ["请重试"],
"innovation": "无法获取创新想法"
}
else:
reviews[role["name"]] = result
return reviews
# 第三阶段:内容生成
def content_generation_stage(
ideation_result: Dict[str, Any],
expert_reviews: Dict[str, Dict[str, Any]],
selected_title: str
) -> str:
"""根据创意和评审生成完整内容
Args:
ideation_result: 创意构思结果
expert_reviews: 专家评审意见
selected_title: 用户选择的标题
Returns:
生成的完整内容(Markdown格式)
"""
# 提取关键评审意见,减少提示词长度
condensed_reviews = {}
for role, review in expert_reviews.items():
condensed_reviews[role] = {
"improvements": review.get("improvements", []),
"innovation": review.get("innovation", "")
}
prompt = f"""
作为专业内容创作者,根据以下信息创作完整内容:
选定标题: {selected_title}
内容大纲:
{ideation_result.get('outline', '未提供大纲')}
专家评审意见:
{json.dumps(condensed_reviews, indent=2, ensure_ascii=False)}
请创作一篇完整、引人入胜且结构清晰的内容。
内容应该整合专家的改进建议,并保持专业性和吸引力。
使用markdown格式,确保添加适当的标题层级、列表和强调。
"""
return get_completion(prompt)
# 第四阶段:质量优化
def quality_enhancement_stage(generated_content: str) -> str:
"""优化生成的内容质量
Args:
generated_content: 生成的初始内容
Returns:
优化后的内容(Markdown格式)
"""
prompt = f"""
作为内容编辑,请优化以下内容:
{generated_content}
请:
1. 检查并修正任何语法或拼写错误
2. 提高表达的清晰度和简洁性
3. 确保标题和小标题吸引人
4. 优化段落和句子结构以提高可读性
5. 增强整体的专业性和说服力
返回优化后的完整内容(使用markdown格式)。
不要对内容进行重写,只做必要的优化。
"""
return get_completion(prompt)
#
# # 主界面
# def main():
# 设置页面配置
st.set_page_config(
page_title="AI内容创作助手",
page_icon="✍️",
layout="wide",
initial_sidebar_state="expanded"
)
# 应用样式
st.markdown("""
<style>
.main .block-container {
padding-top: 2rem;
padding-bottom: 2rem;
}
.stTabs [data-baseweb="tab-list"] {
gap: 2px;
}
.stTabs [data-baseweb="tab"] {
padding: 10px 16px;
font-size: 16px;
}
.success-msg {
padding: 10px;
border-radius: 5px;
background-color: #d4edda;
border: 1px solid #c3e6cb;
color: #155724;
margin: 10px 0;
}
</style>
""", unsafe_allow_html=True)
# 页面标题
st.title("AI内容创作助手:多阶段智能流程")
st.markdown("### 将复杂的内容创作过程分解为可管理的链式任务")
# 侧边栏 - API设置与系统信息
st.sidebar.header("⚙️ 设置")
api_key = st.sidebar.text_input("OpenAI API Key", type="password")
model_choice = st.sidebar.selectbox(
"选择模型",
["deepseek/deepseek-r1-distill-llama-8b", "gpt-4"],
index=0
)
# 显示系统信息
st.sidebar.markdown("---")
st.sidebar.subheader(" 系统说明")
st.sidebar.markdown("""
**内容创作流程:**
1. 创意构思 - 生成内容构思
2. 专家评审 - 多角色评估反馈
3. 内容生成 - 完整内容创作
4. 质量优化 - 编辑润色完善
**提示:** 在每个步骤完成后才能进行下一步
""")
# 设置API密钥
if api_key:
api_key = api_key
# 主界面 - 分阶段标签页
tab1, tab2, tab3, tab4 = st.tabs([
" 创意构思",
" 专家评审",
" 内容生成",
" 质量优化"
])
# 初始化会话状态
for key in ["ideation_result", "expert_reviews", "generated_content", "enhanced_content"]:
if key not in st.session_state:
st.session_state[key] = None
# 记录当前状态
if "current_stage" not in st.session_state:
st.session_state.current_stage = 1
# 阶段1: 创意构思
with tab1:
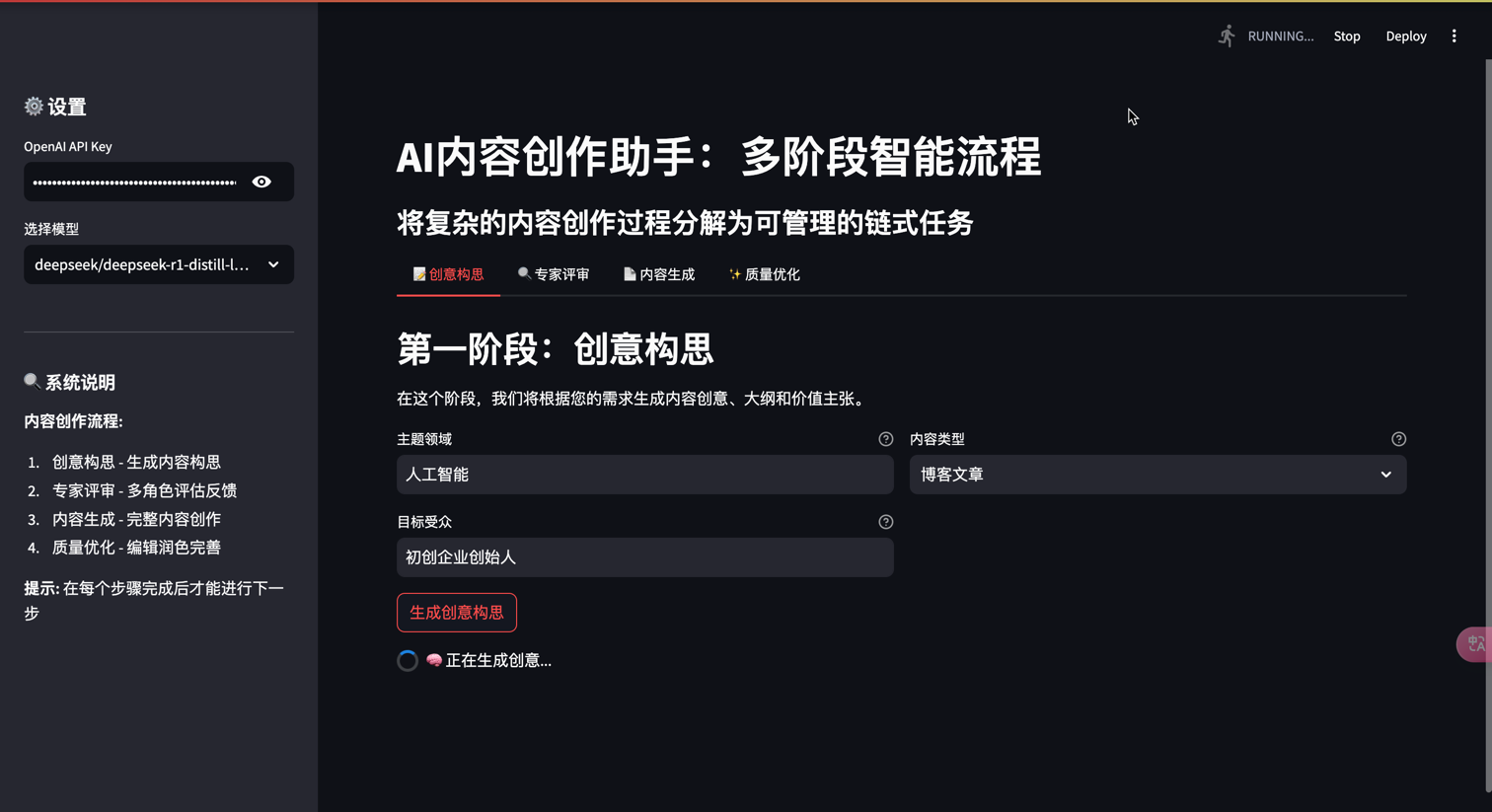
st.header("第一阶段:创意构思")
st.markdown("在这个阶段,我们将根据您的需求生成内容创意、大纲和价值主张。")
col1, col2 = st.columns(2)
with col1:
topic_area = st.text_input(
"主题领域",
placeholder="例如:人工智能、健康饮食、投资策略",
help="您想要创作内容的主题范围"
)
target_audience = st.text_input(
"目标受众",
placeholder="例如:初创企业创始人、健身爱好者、新手投资者",
help="您希望内容面向的读者群体"
)
with col2:
content_type = st.selectbox(
"内容类型",
["博客文章", "社交媒体帖子", "新闻稿", "教程", "电子书章节", "播客脚本", "产品介绍"],
help="您想要创作的内容形式"
)
# 是否有必填字段为空
has_empty_fields = not topic_area or not target_audience
if st.button(
"生成创意构思",
key="ideation_btn",
disabled=not api_key or has_empty_fields,
help="点击开始生成内容创意"
):
if not api_key:
st.error("请先在侧边栏设置OpenAI API Key")
elif has_empty_fields:
st.warning("请填写所有必要字段")
else:
with st.spinner(" 正在生成创意..."):
st.session_state.ideation_result = ideation_stage(
topic_area,
target_audience,
content_type
)
if "error" in st.session_state.ideation_result:
st.error(f"创意生成失败: {st.session_state.ideation_result['error']}")
else:
st.session_state.current_stage = 2
if st.session_state.ideation_result and "error" not in st.session_state.ideation_result:
st.subheader(" 创意结果")
titles = st.session_state.ideation_result.get("titles", [])
if titles:
st.markdown("**️ 推荐标题选项:**")
for i, title in enumerate(titles):
st.markdown(f"**{i + 1}.** {title}")
outline = st.session_state.ideation_result.get("outline", "")
if outline:
st.markdown("** 内容大纲:**")
st.markdown(outline)
value_props = st.session_state.ideation_result.get("value_props", [])
if value_props:
st.markdown("** 价值主张:**")
for prop in value_props:
st.markdown(f"- {prop}")
st.success(" 创意构思完成!请继续到「专家评审」阶段")
if st.session_state.current_stage == 2:
st.markdown(" **提示:** 请点击上方的「专家评审」标签继续")
# 阶段2: 专家评审
with tab2:
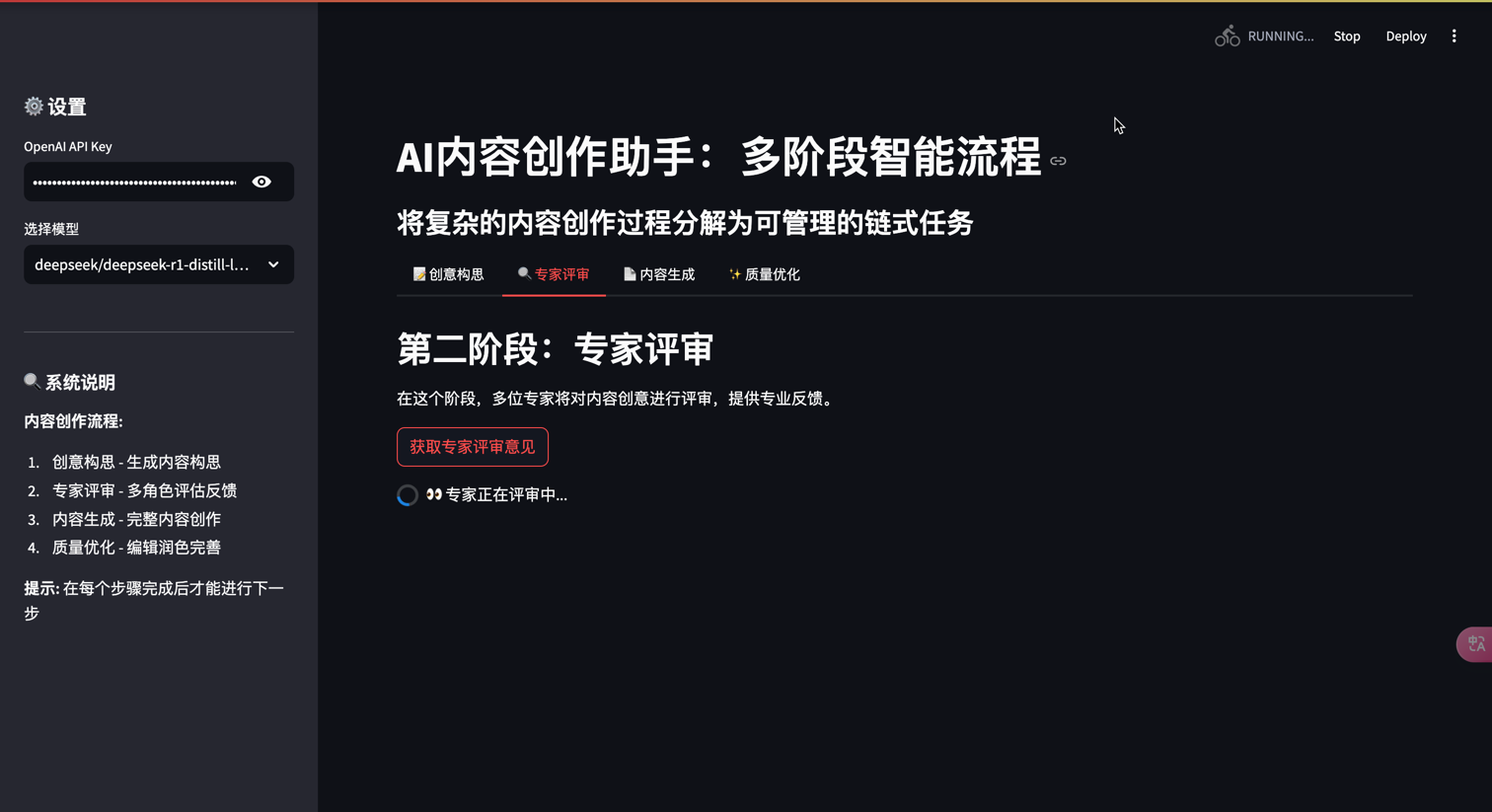
st.header("第二阶段:专家评审")
st.markdown("在这个阶段,多位专家将对内容创意进行评审,提供专业反馈。")
if not st.session_state.ideation_result or "error" in st.session_state.ideation_result:
st.info("️ 请先完成创意构思阶段")
else:
if st.button(
"获取专家评审意见",
key="review_btn",
help="点击获取多位专家的评审意见"
):
with st.spinner(" 专家正在评审中..."):
st.session_state.expert_reviews = expert_review_stage(
st.session_state.ideation_result
)
st.session_state.current_stage = 3
if st.session_state.expert_reviews:
st.subheader(" 专家评审结果")
for role, review in st.session_state.expert_reviews.items():
rating = review.get('rating', 'N/A')
rating_display = f"{rating}/10" if isinstance(rating, (int, float)) else rating
with st.expander(f" {role} 评审 (评分: {rating_display})"):
st.markdown("**优点:**")
for strength in review.get("strengths", []):
st.markdown(f" {strength}")
st.markdown("**改进建议:**")
for improvement in review.get("improvements", []):
st.markdown(f" {improvement}")
st.markdown("**创新想法:**")
st.markdown(f" {review.get('innovation', 'N/A')}")
st.success(" 专家评审完成!请继续到「内容生成」阶段")
if st.session_state.current_stage == 3:
st.markdown(" **提示:** 请点击上方的「内容生成」标签继续")
# 阶段3: 内容生成
with tab3:
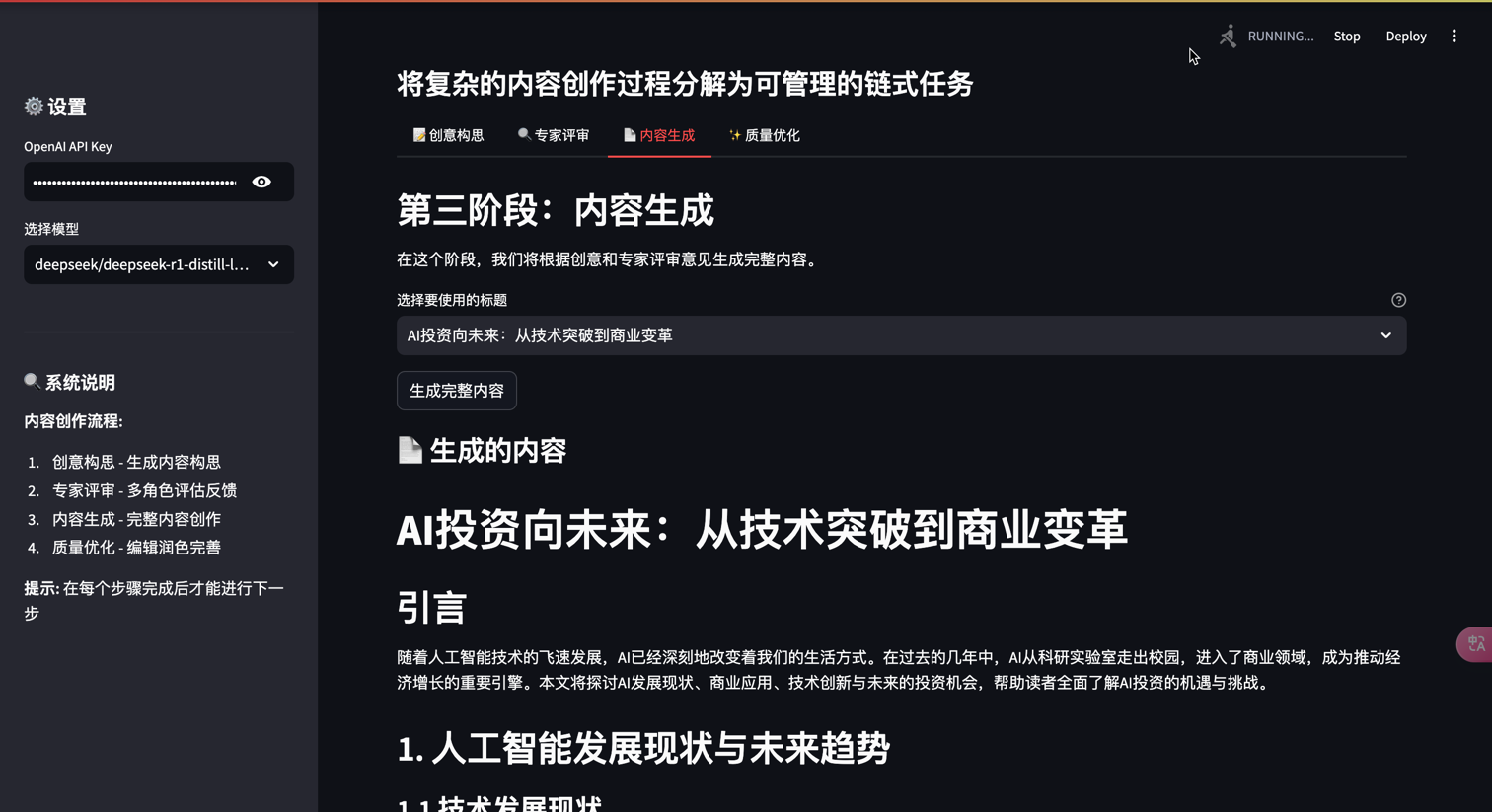
st.header("第三阶段:内容生成")
st.markdown("在这个阶段,我们将根据创意和专家评审意见生成完整内容。")
if not st.session_state.expert_reviews:
st.info("️ 请先完成专家评审阶段")
else:
selected_title = st.selectbox(
"选择要使用的标题",
st.session_state.ideation_result.get("titles", ["无标题选项"]),
help="从创意阶段生成的标题中选择一个用于最终内容"
)
if st.button(
"生成完整内容",
key="generate_btn",
help="点击开始生成完整内容"
):
with st.spinner(" 正在生成内容...这可能需要一些时间"):
st.session_state.generated_content = content_generation_stage(
st.session_state.ideation_result,
st.session_state.expert_reviews,
selected_title
)
st.session_state.current_stage = 4
if st.session_state.generated_content:
st.subheader(" 生成的内容")
# 显示内容预览部分
content_preview = st.session_state.generated_content
if len(content_preview) > 1000:
# 只显示前1000个字符作为预览
st.markdown(content_preview[:1000] + "...**[内容过长,仅显示部分预览]**")
# 提供完整查看选项
with st.expander("查看完整内容"):
st.markdown(content_preview)
else:
st.markdown(content_preview)
st.success(" 内容生成完成!请继续到「质量优化」阶段")
if st.session_state.current_stage == 4:
st.markdown(" **提示:** 请点击上方的「质量优化」标签继续")
# 阶段4: 质量优化
with tab4:
st.header("第四阶段:质量优化")
st.markdown("在这个阶段,我们将优化内容的质量,修正错误并提升可读性。")
if not st.session_state.generated_content:
st.info("️ 请先完成内容生成阶段")
else:
if st.button(
"优化内容质量",
key="enhance_btn",
help="点击开始优化内容质量"
):
with st.spinner(" 正在优化内容质量..."):
st.session_state.enhanced_content = quality_enhancement_stage(
st.session_state.generated_content
)
if st.session_state.enhanced_content:
# 创建标签页显示优化前后对比
before_tab, after_tab = st.tabs(["优化前", "优化后"])
with before_tab:
st.markdown(st.session_state.generated_content)
with after_tab:
st.markdown(st.session_state.enhanced_content)
# 提供下载功能
st.download_button(
label=" 下载最终内容(Markdown)",
data=st.session_state.enhanced_content,
file_name=f"ai_content_{int(time.time())}.md",
mime="text/markdown",
help="下载优化后的完整内容为Markdown文件"
)
# 复制到剪贴板按钮(需要JavaScript)
st.markdown("""
<div class="success-msg">
<h3> 恭喜!完整内容创作流程已完成</h3>
<p>您现在可以下载生成的内容或进行新的创作。</p>
</div>
""", unsafe_allow_html=True)
# 提供重新开始选项
if st.button(" 开始新的创作", help="清除当前状态并开始新的创作流程"):
# 重置会话状态
for key in ["ideation_result", "expert_reviews", "generated_content", "enhanced_content"]:
st.session_state[key] = None
st.session_state.current_stage = 1
st.rerun()


- 运行 Streamlit 应用:
streamlit run content_creation_assistant.py
在浏览器中访问应用(通常是 http://localhost:8501)
在侧边栏输入你的 OpenAI API 密钥
按照界面提示完成多阶段内容创作流程
系统特点与优势
- 模块化设计:各阶段明确分离,便于维护和扩展
- 多角色协作:专家评审阶段引入多个专业角色视角
- 渐进式增强:每个阶段都基于前一阶段的结果进行优化
- 用户参与:在关键决策点(如标题选择)允许用户介入
- 直观界面:Streamlit 提供了简洁明了的多阶段操作流程
总结
链式任务设计和协作型 Prompt 系统为复杂 AI 应用的开发提供了强大的框架。通过将复杂问题分解为一系列相互关联的子任务,并模拟多个专业角色的协作,我们可以构建出远超单轮对话能力的智能系统。
本文介绍的技术适用于各种场景,从简单的多步骤处理流程到复杂的多角色协作系统。特别是在需要深度思考、专业评估或创意生成的应用场景中,这些技术可以显著提升 AI 系统的输出质量和实用性。
最重要的是,这些方法不依赖于特定的模型或平台,可以应用于各种大语言模型和应用场景,为 AI 应用开发提供了一种可扩展、可维护的方法论。
希望本文的理论讲解和实际案例能够帮助你理解和应用链式任务设计的原理,构建更加强大的协作型 Prompt 系统。
L3-3、从单轮到链式任务:设计协作型 Prompt 系统的更多相关文章
- java开发中的链式思维 —— 设计一个链式过滤器
概述 最近在弄阿里云的sls日志服务,该服务提供了一个搜索接口,可根据各种运算.逻辑等表达式搜出想要的内容.具体语法可见https://help.aliyun.com/document_detail/ ...
- 队列链式存储 - 设计与实现 - API函数
队列相关基础内容参我的博文:队列顺序存储 - 设计与实现 - API函数 队列也是一种特殊的线性表:可以用线性表链式存储来模拟队列的链式存储. 主要代码: // linkqueue.h // 队列链式 ...
- java链式编程设计
一般情况下,对一个类的实例和操作,是采用这种方法进行的: Channel channel = new Channel(); channel.queueDeclare(QUEUE_NAME, true, ...
- C++编程练习(2)----“实现简单的线性表的链式存储结构“
单链表采用链式存储结构,用一组任意的存储单元存放线性表的元素. 对于查找操作,单链表的时间复杂度为O(n). 对于插入和删除操作,单链表在确定位置后,插入和删除时间仅为O(1). 单链表不需要分配存储 ...
- 由表单验证说起,关于在C#中尝试链式编程的实践
在web开发中必不可少的会遇到表单验证的问题,为避免数据在写入到数据库时出现异常,一般比较安全的做法是前端会先做一次验证,通过后把数据提交到后端再验证一次,因为仅仅靠前端验证是不安全的,有太多的htt ...
- Scala 深入浅出实战经典 第79讲:单例深入讲解及单例背后的链式表达式
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- c数据结构 -- 线性表之 顺序存储结构 于 链式存储结构 (单链表)
线性表 定义:线性表是具有相同特性的数据元素的一个有限序列 类型: 1:顺序存储结构 定义:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构 算法: #include <stdio. ...
- 洛谷P3371单源最短路径Dijkstra版(链式前向星处理)
首先讲解一下链式前向星是什么.简单的来说就是用一个数组(用结构体来表示多个量)来存一张图,每一条边的出结点的编号都指向这条边同一出结点的另一个编号(怎么这么的绕) 如下面的程序就是存链式前向星.(不用 ...
- C语言 线性表 链式表结构 实现
一个单链式实现的线性表 mList (GCC编译). /** * @brief 线性表的链式实现 (单链表) * @author wid * @date 2013-10-21 * * @note 若代 ...
- 数据结构Java实现07----队列:顺序队列&顺序循环队列、链式队列、顺序优先队列
一.队列的概念: 队列(简称作队,Queue)也是一种特殊的线性表,队列的数据元素以及数据元素间的逻辑关系和线性表完全相同,其差别是线性表允许在任意位置插入和删除,而队列只允许在其一端进行插入操作在其 ...
随机推荐
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Map Kit(5)
1.问题描述: 提供两套标准方案,可根据体验需求选择: 1.地图Picker(地点详情) 用户体验:①展示地图 ②标记地点 ③用户选择已安装地图应用 接入文档:https://developer.hu ...
- Abaqus-Steady-State-Dynamic-Analysis的求解原理
0. 总括 基于模态的谐响应分析,可以通过扫频的方式求解频率范围内结构的线性稳态响应情况.阻尼是和频率相关的,但模态叠加法只需要知道n个模态阻尼即可推广到其他频率范围(原因详见文内公式). 1. 谐响 ...
- Cordova基本使用(二)
cordova的打包发布版app流程简介 除了第一遍官网给的打包发布版的方法,我们可以自己多敲几次命令来实现. 基本上使用如下的几个命令就完成这个过程,先列出整个过程: 1.cordova选定ando ...
- PDF转换:从Word到Excel
一.引言 在数字化的浪潮中,PDF文件格式以其稳定性和兼容性成为了信息交流的宠儿.然而,当我们需要编辑这些PDF文件时,往往会遇到各种难题.今天,我要和大家分享的,是如何将PDF文件轻松转换成Word ...
- 容器引擎-Docker
Docker是一个开源的应用容器引擎,可以轻松的为任何应用创建一个轻量级.可移植的.自给自足的容器.Docker类似于集装箱,各式各样的货物,经过集装箱的标准化进行托管,而集装箱和集装箱之间没有影响. ...
- .NET周刊【3月第2期 2025-03-09】
国内文章 记一次.NET内存居高不下排查解决与启示 https://www.cnblogs.com/huangsheng/p/18731382 本文讲述了一个ASP.NET Core gRPC服务迁移 ...
- Ubuntu 下查看 ip
博客地址:https://www.cnblogs.com/zylyehuo/ ip a
- 懂了 OpenLDAP
轻型目录访问协议(英文: LightweightDirectoryAccessProtocol,缩写: LDAP)是一个开放的,中立的,工业标准的应用协议,通过IP协议提供访问控制和维护分布式信息的目 ...
- Vite CVE-2025-30208 安全漏洞
Vite CVE-2025-30208 安全漏洞 一.漏洞概述 CVE-2025-30208 是 Vite(一个前端开发工具提供商)在特定版本中存在的安全漏洞.此漏洞允许攻击者通过特殊的 URL 参数 ...
- .net 跨域 config中配置
<system.webServer> <validation validateIntegratedModeConfiguration="false" /> ...