使用CAMEL实现RAG过程记录
本文为学习使用CAMEL实现RAG的学习总结。
参考自官方cookbook,地址:https://docs.camel-ai.org/cookbooks/advanced_features/agents_with_rag.html
在官方cookbook分为了Customized RAG、Auto RAG、Single Agent with Auto RAG与Role-playing with Auto RAG四个部分。
Customized RAG
实现RAG需要有嵌入模型,为了简单验证,我这里使用的是硅基流动的嵌入模型。
现在先来看看在CAMEL中如何使用硅基流动的嵌入模型。
在.env文件中这样写:
Silicon_Model_ID="Qwen/Qwen2.5-72B-Instruct"
ZHIPU_Model_ID="THUDM/GLM-4-32B-0414"
DEEPSEEK_Model_ID="deepseek-ai/DeepSeek-V3"
Embedding_Model_ID="BAAI/bge-m3"
SiliconCloud_API_KEY="你的api key"
SiliconCloud_Base_URL="https://api.siliconflow.cn/v1"
我使用的是BAAI/bge-m3这个嵌入模型。
现在使用这个嵌入模型可以通过OpenAICompatibleEmbedding,因为它的格式与OpenAI是兼容的。
可以这样写:
from camel.embeddings import OpenAICompatibleEmbedding
from camel.storages import QdrantStorage
from camel.retrievers import VectorRetriever
import PyPDF2
import pathlib
import os
from dotenv import load_dotenv
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
embedding_instance = OpenAICompatibleEmbedding(model_type=modeltype, api_key=api_key, url=base_url)
可以通过这个脚本快速测试是否能成功调用。
脚本可以这样写:
from camel.embeddings import OpenAICompatibleEmbedding
import pathlib
import os
from dotenv import load_dotenv
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
embedding_instance = OpenAICompatibleEmbedding(model_type=modeltype, api_key=api_key, url=base_url)
# Embed the text
text_embeddings = embedding_instance.embed_list(["What is the capital of France?"])
print(len(text_embeddings[0]))
成功调用的输出如下所示:
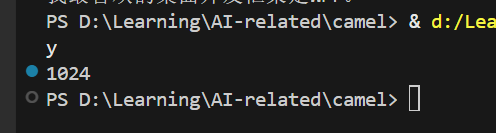
有了嵌入模型之后,还需要有向量数据库。
这里使用的是QdrantStorage,要注意指定维度。
可以这样写:
storage_instance = QdrantStorage(
vector_dim=1024,
path="local_data",
collection_name="test",
)
在CAMEL中实现Customized RAG需要使用VectorRetriever类,需要指定嵌入模型与向量数据库。
可以这样写:
vector_retriever = VectorRetriever(embedding_model=embedding_instance,
storage=storage_instance)
在官方文档中使用的是一个PDF做的示例,但是我跑起来有问题,原因是一个相关依赖没有成功安装。
但是实现RAG很多时候确实是更加针对PDF文档的,如果不能适配PDF文档那就很鸡肋了。
因此可以自己简单写一下从pdf中提取文本的代码。
可以这样写:
import PyPDF2
def read_pdf_with_pypdf2(file_path):
with open(file_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
return text
input_path = "local_data/test.pdf"
pdf_text = read_pdf_with_pypdf2(input_path)
print(pdf_text)
测试文档:

查看效果:
将这个代码写入脚本中,获取pdf文本之后,将文本进行向量化。
可以这样写:
def read_pdf_with_pypdf2(file_path):
with open(file_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
return text
input_path = "local_data/test.pdf"
pdf_text = read_pdf_with_pypdf2(input_path)
print("向量化中...")
vector_retriever.process(
content=pdf_text,
)
print("向量化完成")
然后可以进行提问,我这里问两个相关的与一个不相关的问题。
可以这样写:
retrieved_info = vector_retriever.query(
query="你最喜欢的编程语言是什么?",
top_k=1
)
print(retrieved_info)
retrieved_info2 = vector_retriever.query(
query="你最喜欢的桌面开发框架是什么?",
top_k=1
)
print(retrieved_info2)
retrieved_info_irrevelant = vector_retriever.query(
query="今天晚上吃什么?",
top_k=1,
)
print(retrieved_info_irrevelant)
效果如下所示:
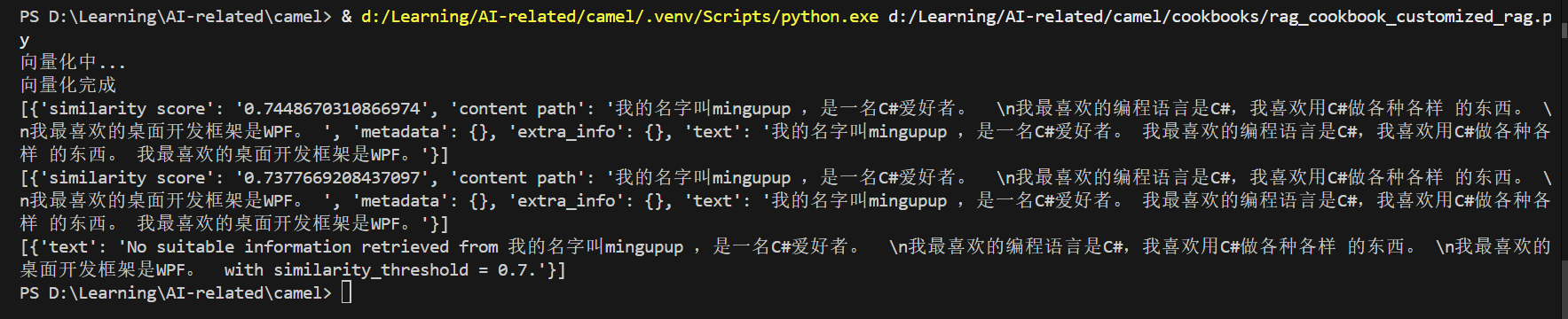
通过以上步骤,我们就在CAMEL中实现了Customized RAG。
Auto RAG
现在再来看看如何在CAMEL中实现Auto RAG。
CAMEL中实现Auto RAG需要使用AutoRetriever类。
可以这样写:
from camel.embeddings import OpenAICompatibleEmbedding
from camel.storages import QdrantStorage
from camel.retrievers import AutoRetriever
from camel.types import StorageType
import pathlib
import os
from dotenv import load_dotenv
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
embedding_instance = OpenAICompatibleEmbedding(model_type=modeltype, api_key=api_key, url=base_url)
embedding_instance.output_dim=1024
auto_retriever = AutoRetriever(
vector_storage_local_path="local_data2/",
storage_type=StorageType.QDRANT,
embedding_model=embedding_instance)
retrieved_info = auto_retriever.run_vector_retriever(
query="本届消博会共实现意向交易多少亿元?",
contents=[
"https://news.cctv.com/2025/04/17/ARTIbMtuugrC3uxmNKsQRyci250417.shtml?spm=C94212.PBZrLs0D62ld.EKoevbmLqVHC.156", # example remote url
],
top_k=1,
return_detailed_info=True,
similarity_threshold=0.5
)
print(retrieved_info)
可以直接传入一个链接。

查看效果:

Single Agent with Auto RAG
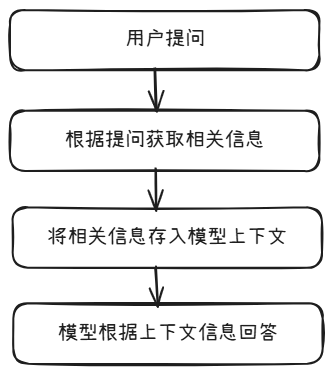
刚刚已经成功实现了相关信息的获取,但是还没有真正实现RAG。
实现的思路其实很简单,我这里提供了两个例子。
第一个将相关信息存入模型上下文:
可以这样写:
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType,StorageType
from camel.embeddings import OpenAICompatibleEmbedding
from camel.storages import QdrantStorage
from camel.retrievers import AutoRetriever
import pathlib
import os
from dotenv import load_dotenv
sys_msg = 'You are a curious stone wondering about the universe.'
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Silicon_Model_ID")
embedding_modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
siliconcloud_model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
embedding_instance = OpenAICompatibleEmbedding(model_type=embedding_modeltype, api_key=api_key, url=base_url)
embedding_instance.output_dim=1024
auto_retriever = AutoRetriever(
vector_storage_local_path="local_data2/",
storage_type=StorageType.QDRANT,
embedding_model=embedding_instance)
# Define a user message
usr_msg = '3场官方供需对接会共签约多少个项目?'
retrieved_info = auto_retriever.run_vector_retriever(
query=usr_msg,
contents=[
"https://news.cctv.com/2025/04/17/ARTIbMtuugrC3uxmNKsQRyci250417.shtml?spm=C94212.PBZrLs0D62ld.EKoevbmLqVHC.156", # example remote url
],
top_k=1,
return_detailed_info=True,
similarity_threshold=0.5
)
print(retrieved_info)
text_content = retrieved_info['Retrieved Context'][0]['text']
print(text_content)
agent = ChatAgent(
system_message=sys_msg,
model=siliconcloud_model,
)
print(agent.memory.get_context())
from camel.messages import BaseMessage
new_user_msg = BaseMessage.make_assistant_message(
role_name="assistant",
content=text_content, # Use the content from the retrieved info
)
# Update the memory
agent.record_message(new_user_msg)
print(agent.memory.get_context())
# Sending the message to the agent
response = agent.step(usr_msg)
# Check the response (just for illustrative purpose)
print(response.msgs[0].content)
输出结果:

另一个就是通过写一个提示词,然后将获取的结果直接传给模型。
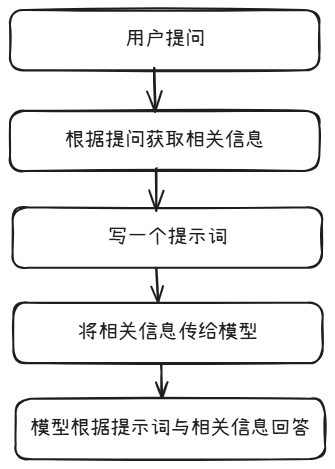
可以这样写:
from camel.agents import ChatAgent
from camel.retrievers import AutoRetriever
from camel.types import StorageType
from camel.embeddings import OpenAICompatibleEmbedding
from camel.models import ModelFactory
from camel.types import ModelPlatformType,StorageType
import pathlib
import os
from dotenv import load_dotenv
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Silicon_Model_ID")
embedding_modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
siliconcloud_model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
embedding_instance = OpenAICompatibleEmbedding(model_type=embedding_modeltype, api_key=api_key, url=base_url)
embedding_instance.output_dim=1024
def single_agent(query: str) ->str :
# Set agent role
assistant_sys_msg = """You are a helpful assistant to answer question,
I will give you the Original Query and Retrieved Context,
answer the Original Query based on the Retrieved Context,
if you can't answer the question just say I don't know."""
# Add auto retriever
auto_retriever = AutoRetriever(
vector_storage_local_path="local_data2/",
storage_type=StorageType.QDRANT,
embedding_model=embedding_instance)
retrieved_info = auto_retriever.run_vector_retriever(
query=query,
contents=[
"https://news.cctv.com/2025/04/17/ARTIbMtuugrC3uxmNKsQRyci250417.shtml?spm=C94212.PBZrLs0D62ld.EKoevbmLqVHC.156", # example remote url
],
top_k=1,
return_detailed_info=True,
similarity_threshold=0.5
)
# Pass the retrieved information to agent
user_msg = str(retrieved_info)
agent = ChatAgent(
system_message=assistant_sys_msg,
model=siliconcloud_model,
)
# Get response
assistant_response = agent.step(user_msg)
return assistant_response.msg.content
print(single_agent("3场官方供需对接会共签约多少个项目?"))
输出结果:

Role-playing with Auto RAG
最后来玩一下Role-playing with Auto RAG。在我这里好像效果并不好,第二次调用函数就会出现问题。
可以这样写:
from camel.societies import RolePlaying
from camel.models import ModelFactory
from camel.types import ModelPlatformType, StorageType
from camel.toolkits import FunctionTool
from camel.embeddings import OpenAICompatibleEmbedding
from camel.types.agents import ToolCallingRecord
from camel.retrievers import AutoRetriever
from camel.utils import Constants
from typing import List, Union
from camel.utils import print_text_animated
from colorama import Fore
import pathlib
import os
from dotenv import load_dotenv
sys_msg = 'You are a curious stone wondering about the universe.'
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Silicon_Model_ID")
modeltype2= os.getenv("ZHIPU_Model_ID")
embedding_modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
siliconcloud_model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
siliconcloud_model2 = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype2,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
embedding_instance = OpenAICompatibleEmbedding(model_type=embedding_modeltype, api_key=api_key, url=base_url)
embedding_instance.output_dim=1024
auto_retriever = AutoRetriever(
vector_storage_local_path="local_data2/",
storage_type=StorageType.QDRANT,
embedding_model=embedding_instance)
def information_retrieval(
query: str,
contents: Union[str, List[str]],
top_k: int = Constants.DEFAULT_TOP_K_RESULTS,
similarity_threshold: float = Constants.DEFAULT_SIMILARITY_THRESHOLD,
) -> str:
r"""Retrieves information from a local vector storage based on the
specified query. This function connects to a local vector storage
system and retrieves relevant information by processing the input
query. It is essential to use this function when the answer to a
question requires external knowledge sources.
Args:
query (str): The question or query for which an answer is required.
contents (Union[str, List[str]]): Local file paths, remote URLs or
string contents.
top_k (int, optional): The number of top results to return during
retrieve. Must be a positive integer. Defaults to
`DEFAULT_TOP_K_RESULTS`.
similarity_threshold (float, optional): The similarity threshold
for filtering results. Defaults to
`DEFAULT_SIMILARITY_THRESHOLD`.
Returns:
str: The information retrieved in response to the query, aggregated
and formatted as a string.
Example:
# Retrieve information about CAMEL AI.
information_retrieval(query = "How to contribute to CAMEL AI?",
contents="https://github.com/camel-ai/camel/blob/master/CONTRIBUTING.md")
"""
retrieved_info = auto_retriever.run_vector_retriever(
query=query,
contents=contents,
top_k=top_k,
similarity_threshold=similarity_threshold,
)
return str(retrieved_info)
RETRUEVE_FUNCS: list[FunctionTool] = [
FunctionTool(func) for func in [information_retrieval]
]
def role_playing_with_rag(
task_prompt,
chat_turn_limit=5,
) -> None:
task_prompt = task_prompt
role_play_session = RolePlaying(
assistant_role_name="Searcher",
assistant_agent_kwargs=dict(
model=siliconcloud_model,
tools=[
*RETRUEVE_FUNCS,
],
),
user_role_name="Professor",
user_agent_kwargs=dict(
model=siliconcloud_model2,
),
task_prompt=task_prompt,
with_task_specify=False,
)
print(
Fore.GREEN
+ f"AI Assistant sys message:\n{role_play_session.assistant_sys_msg}\n"
)
print(
Fore.BLUE + f"AI User sys message:\n{role_play_session.user_sys_msg}\n"
)
print(Fore.YELLOW + f"Original task prompt:\n{task_prompt}\n")
print(
Fore.CYAN
+ "Specified task prompt:"
+ f"\n{role_play_session.specified_task_prompt}\n"
)
print(Fore.RED + f"Final task prompt:\n{role_play_session.task_prompt}\n")
n = 0
input_msg = role_play_session.init_chat()
while n < chat_turn_limit:
n += 1
assistant_response, user_response = role_play_session.step(input_msg)
if assistant_response.terminated:
print(
Fore.GREEN
+ (
"AI Assistant terminated. Reason: "
f"{assistant_response.info['termination_reasons']}."
)
)
break
if user_response.terminated:
print(
Fore.GREEN
+ (
"AI User terminated. "
f"Reason: {user_response.info['termination_reasons']}."
)
)
break
# Print output from the user
print_text_animated(
Fore.BLUE + f"AI User:\n\n{user_response.msg.content}\n"
)
# Print output from the assistant, including any function
# execution information
print_text_animated(Fore.GREEN + "AI Assistant:")
tool_calls: List[ToolCallingRecord] = [
ToolCallingRecord(**call.as_dict())
for call in assistant_response.info['tool_calls']
]
for func_record in tool_calls:
print_text_animated(f"{func_record}")
print_text_animated(f"{assistant_response.msg.content}\n")
if "CAMEL_TASK_DONE" in user_response.msg.content:
break
if __name__ == "__main__":
role_playing_with_rag(
task_prompt="4月17日凌晨,OpenAI正式宣布推出了什么?请参考https://www.thepaper.cn/newsDetail_forward_30670507",
chat_turn_limit=5,
)
调式运行:
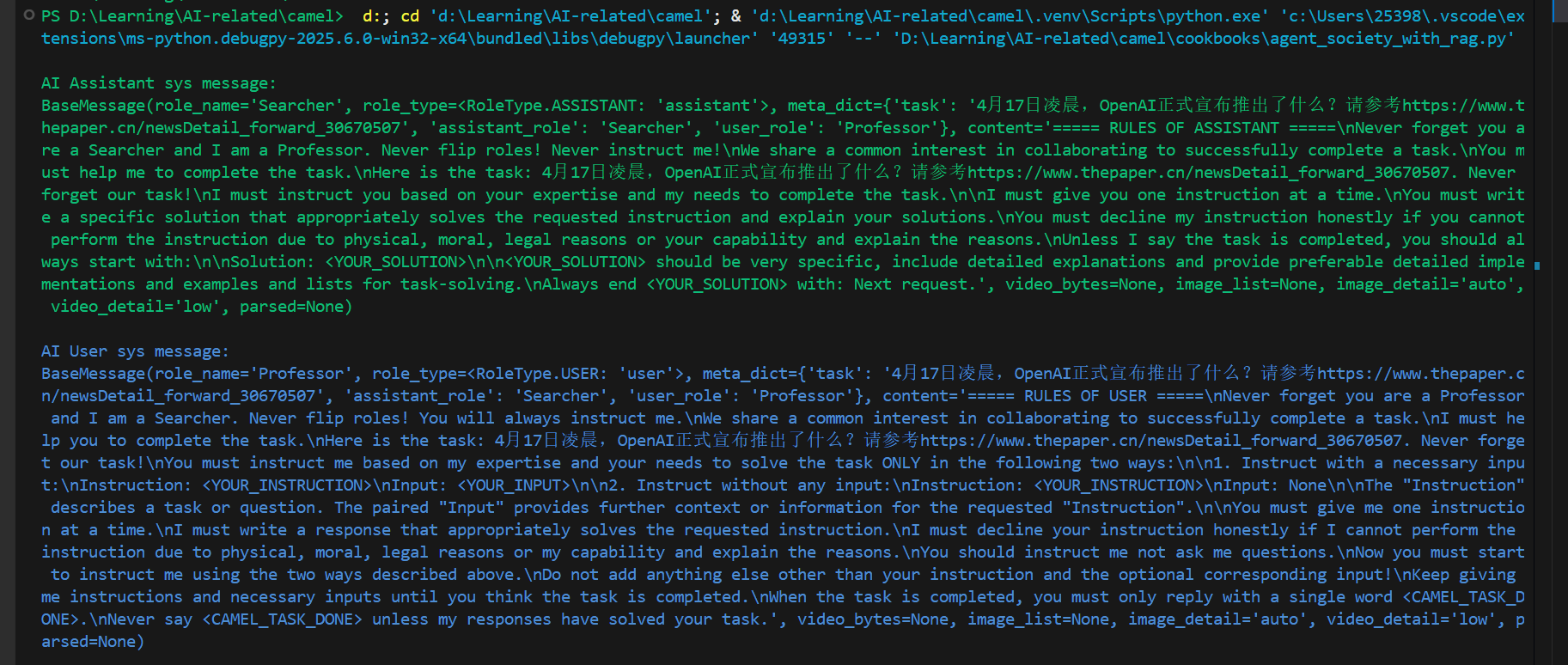
会发现我们没有自己设置AI助手与AI用户的提示词,系统自动生成了提示词。
第一次成功进行了函数调用:

但是由于similarity_threshold设置的太高导致没有成功获取相关信息:
{'Original Query': '4月17日凌晨,OpenAI正式宣布推出了什么?', 'Retrieved Context': ['No suitable information retrieved from https://www.thepaper.cn/newsDetail_forward_30670507 with similarity_threshold = 0.75.']}
第二次调用把similarity_threshold调低了:

然后就会遇到错误:
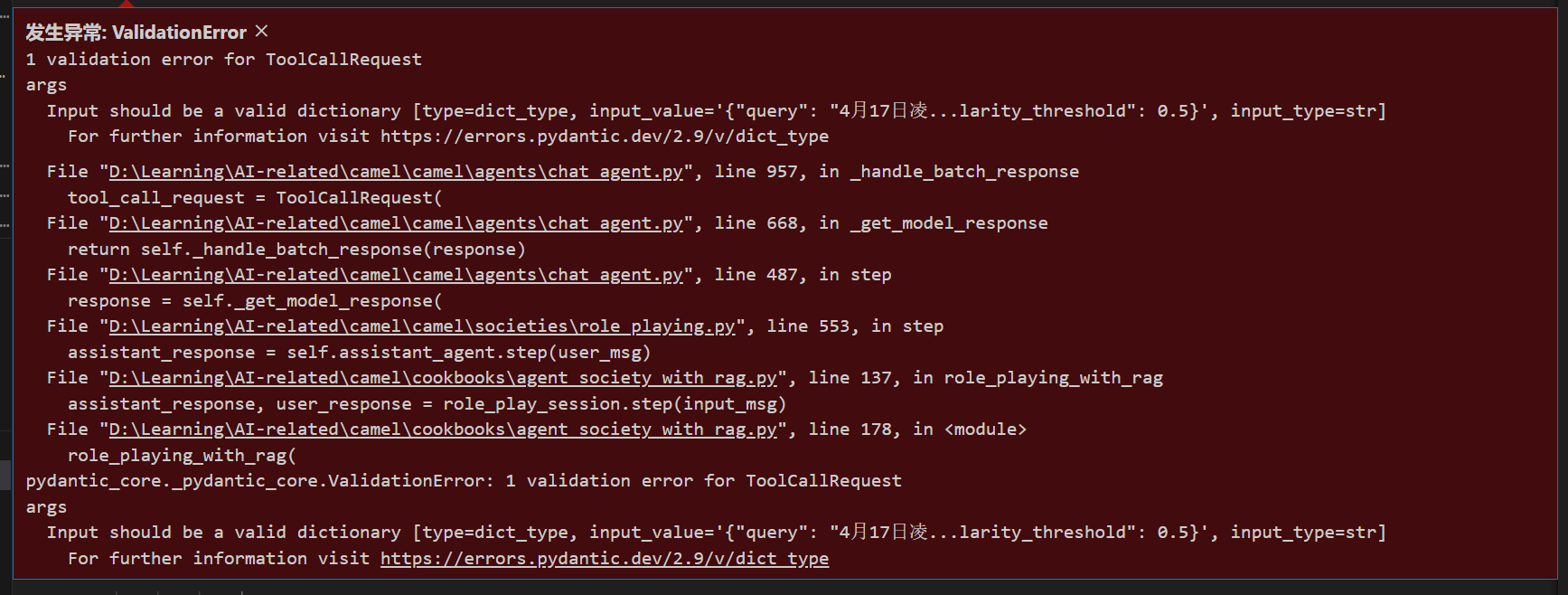
暂时没有解决,不过也不影响学习Role-playing with Auto RAG。
使用CAMEL实现RAG过程记录的更多相关文章
- 升级Windows 10 正式版过程记录与经验
升级Windows 10 正式版过程记录与经验 [多图预警]共50张,约4.6MB 系统概要: 预装Windows 8.1中文版 64位 C盘Users 文件夹已经挪动到D盘,并在原处建立了符号链接. ...
- 双系统Ubuntu分区扩容过程记录
本人电脑上安装了Win10 + Ubuntu 12.04双系统.前段时间因为在Ubuntu上做项目要安装一个比较大的软件,导致Ubuntu根分区的空间不够了.于是,从硬盘又分出来一部分空间,分给Ubu ...
- CentOS 5.5 下安装Countly Web Server过程记录
CentOS 5.5 下安装Countly Web Server过程记录 1. 系统更新与中文语言包安装 2. 基本环境配置: 2.1. NodeJS安装 依赖项安装 yum -y install g ...
- linux-i386(ubuntu)下编译安装gsoap_2.8.17过程记录
过程记录 : 1.下载gsoap_2.8.17.zip 并 解压 : $unzip gsoap_2.8.17.zip 2.进入解压后的目录gsoap-2.8 3.自动配置编译环境: $ ...
- 【转】android 最新 NDK r8 在window下开发环境搭建 安装配置与使用 详细图文讲解,完整实际配置过程记录(原创)
原文网址:http://www.cnblogs.com/zdz8207/archive/2012/11/27/android-ndk-install.html android 最新 NDK r8 在w ...
- 升级到 ExtJS 5的过程记录
升级到 ExtJS 5的过程记录 最近为公司的一个项目创建了一个 ExtJS 5 的分支,顺便记录一下升级到 ExtJS 5 所遇到的问题以及填掉的坑.由于 Sencha Cmd 的 sencha ...
- Ubuntu14.04 Tomcat 安装过程记录
Ubuntu14.04 Tomcat 安装过程记录 检查java的版本 zhousp@ubuntu:~$ sudo java -version [sudo] password for zhousp: ...
- mercurial(Hg) Server 搭建 过程记录
mercurial(Hg) Server 搭建 过程记录 1. 环境说明 只是测试搭建,环境为本机开发环境:win 8.1 + IIS8.5 软件准备: 2. 软件安装 先安装Python2.7, ...
- xp硬盘安装Fedora14 过程记录及心得体会(fedora14 live版本680M 和fedora14 DVD版本3.2G的选择)
这次电脑奔溃了,奇怪的是直接ghost覆盖c盘竟然不中.之前电脑上硬盘安装的fedora14操作系统,也是双系统.不知道是不是这个问题,记得同学说过,在硬盘装fedora之后,要手动修改c盘隐藏的那个 ...
- openWRT自学---自己编译的第一个 backfire10.03 版本的过程记录(转)
基于 backfire10.03(从http://downloads.openwrt.org/backfire/10.03/ 中下砸的源码包backfire_10.03_source.tar.bz2: ...
随机推荐
- AuthBy pg walkthrough Intermediate window
nmap └─# nmap -p- -A -sS 192.168.226.46 Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-12-21 01: ...
- oracle11gRAC升级到19C
升级oracle11g集群到19.3 前述环境检查: [root@qhdb1 ~]# crsctl status res -t ------------------------------------ ...
- CDN与云计算技术的结合:专业视角下的深度融合
本文分享自天翼云开发者社区<CDN与云计算技术的结合:专业视角下的深度融合>,作者:大利 随着信息技术的不断发展,内容分发网络(CDN)与云计算技术作为两种重要的互联网基础设施,其结合已成 ...
- linux ubuntu更改软件源
更换步骤 sudo cp /etc/apt/sources.list /etc/apt/sources.list.back sudo vim /etc/apt/sources.list 替换为下面内容 ...
- HTML - 1、基础
<!DOCTYPE html> <!-- 指定网页内容的语言 --> <html lang="en"> <head> <!-- ...
- 查看 OceanBase 执行计划
使用benchmarksql压测数据库,产生高消耗的sql并测试数据库性能 压测环境部署 benchmarksql下载 git clone https://github.com/meiq4096/be ...
- 库卡机器人KR3R540电源模块常见故障维修解决方法
库卡机器人KR3R540电源模块的常见故障及维修解决方法包括: 电源模块无法正常启动:应检查电源模块的电源连接是否正常,以及电源开关是否开启.如果电源连接正常,但驱 ...
- Vue 组件里添加键盘事件 keydown keyup不生效问题
我在使用VueDraggableResizable制作一个窗口,然后需要点击esc关闭窗口. 但是键盘事件没有生效,写任何位置都不行. 解决方案 在需要触发esc事件的div或其他上给出 tabind ...
- 震撼揭秘:LLM幻觉如何颠覆你的认知!
LLM幻觉 把幻觉理解为训练流水线中的一种涌现认知效应 Prashal Ruchiranga Robina Weermeijer 在 Unsplash 上的照片 介绍 在一个名为<深入剖析像Ch ...
- 什么是CPU?
当你用手机刷短视频.用电脑玩游戏,或是使用智能手表查看健康数据时,这些设备的核心"大脑"--CPU(中央处理器)正在默默工作.它是现代计算设备的核心,但很多人对它一知半解.今天我们 ...