慢SQL优化实战:从一例线上慢SQL探究执行引擎工作过程
作者: vivo 互联网服务器团队- Li Xin
本文通过一个线上慢SQL案例,介绍了Join的两种算法和Order by的工作原理,并通过Explain和Optimizer_trace工具完整推演了慢SQL的执行过程。基于对原理和执行过程的分析,本文给出一种“引导执行引擎选择效率更高的算法”的方案,从而使查询性能得到大幅提升。
1、线上慢 SQL 背景
慢 SQL 会影响用户使用体验,降低数据库的整体性能,严重的甚至会导致服务器挂掉、整个系统瘫痪。笔者通过监控平台发现线上存在这样一条慢SQL(原始SQL已脱敏,表结构出于简化的目的做了一定删减,实际执行耗时以文中提供数据为准),其执行耗时在分钟级。
select t1.*,t2.x from t_table1 t1 leftjoin t_table2 t2 on t1.a = t2.a orderby t1.c desc;
表结构如下:
CREATETABLE `t_table1` (
`id` bigint(20) unsigned NOTNULL AUTO_INCREMENT COMMENT '主键',
`a` varchar(64) NOTNULL,
`b` varchar(64) NOTNULL,
`c` varchar(20) NOTNULL,
PRIMARYKEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB AUTO_INCREMENT=0DEFAULT CHARSET=utf8mb4;
CREATETABLE `t_table2` (
`id` bigint(20) unsigned NOTNULL AUTO_INCREMENT COMMENT '主键',
`a` varchar(64) NOTNULL,
`x` varchar(64) NOTNULL,
`y` varchar(20) NOTNULL,
PRIMARYKEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0DEFAULT CHARSET=utf8mb4;
其他信息:
当发现慢SQL时,笔者的第一反应是使用Explain查看SQL的执行计划,结果如下:

通过Explain初步分析:两张表均执行了全表扫描,结合两张表的数据规模分析全表扫描并非耗时达到分钟级的主要原因。另外执行计划extra种提示的Using temporary; Using filesort; Using join buffer (Block Nested Loop)又分别代表什么含义呢?
2、原理探究
2.1 Join 算法原理
2.1.1 驱动表和被驱动表
在Join语句中,执行引擎优先扫描的表被称为驱动表,另一张表被称为被驱动表。执行引擎在选择驱动表时,除了必须要遵守的特定语义外,最重要的考虑便是执行效率。
首先列举两种特定语义约束驱动表选取的场景:
场景一:Straight join指定连接顺序,强制要求执行引擎优先扫描左侧的表。
场景二:Left/Right [outer] join,方向连接的特点是反方向表中如果不存在关联的数据则填充NULL值,这一特性要求方向查询时优先扫描相同方向的表。倘若where条件中明确指明反方向表中的部分列非空,则驱动表的选择就不受此语义的限制,执行引擎会依据效率选取驱动表。
当没有特定语义的约束时,执行引擎便会依据执行效率选取驱动表,如何判断哪张表作为驱动表的效率更高呢?下文会结合Join的两种算法更深入地探讨这个问题。
2.1.2 Block Nested-Loop Join
假设一个数据量为m行的驱动表与一个数据量为n行的被驱动表进行join查询。
最简单的一种算法:
从驱动表扫描一行数据;
对被驱动表进行全表扫描,得到的结果依次与驱动表的数据进行join并把满足条件的数据加入结果集;
接着扫描驱动表,每扫描一行数据,均重复执行一次步骤2,直至驱动表的全部数据被扫描完毕。
这种算法的磁盘扫描开销为m*n,非常低效,MySQL在实际中并未直接使用该算法,而是采用缓存的思想(分配一块Join buffer)对该算法进行改进,并命名为Block Nested-Loop join(BNL)。
BNL的算法步骤为:
从驱动表一次扫描K条数据,并把数据缓存在Join buffer;
对被驱动表进行全表扫描,得到的结果依次与驱动表的K条数据进行join并把满足条件的数据加入结果集;
清空join_buffer;
接着从驱动表再取出K条数据,重复步骤2、3,直至扫描完驱动表的全部数据。
上述算法中,驱动表分段取数的次数记为l,整个算法的磁盘扫描开销为m+ln。由于分段的次数与驱动表的数据成正相关,所以公式可以记为m+λmn,λ的取值范围为(0,1)。
当两张表的行数(m、n大小)固定的情况下,m对结果的影响更大,m越小整体扫描的代价越小,所以执行引擎优先选择数据量更小的表作为驱动表(符合“小表驱动大表”的说法)。
2.1.3 Index Nested-Loop Join
BNL算法使用了Join buffer结构,虽然有可能通过减少重复扫描来降低磁盘扫描开销,然而驱动表分段扫描的次数过多依然可能会导致查询的低效。索引是MySQL查询提效的重要结构,当被驱动表的关联键存在索引时,MySQL会使用Index Nested-Loop Join(NLJ)算法。
该算法的步骤为:
从驱动表扫描一行数据;
使用驱动表的关联键搜索被驱动表的索引树,通过被驱动表的索引结构找到被驱动表的主键,再通过主键回表查询出被驱动表的关联数据(暂不考虑覆盖索引的情况);
接着扫描驱动表,每扫描一行数据,均重复执行一次步骤2,直至驱动表的全部数据被扫描完毕。
每次搜索一棵树的复杂度近似为log2 n,上述过程在被驱动表扫描一行数据的时间复杂度是2log2 n,算法的整体复杂度为m+2mlog2 n,在该算法中,依旧是m对结果的影响更大,m越小整体扫描的代价越小,所以执行引擎总是选择数据量更小的表作为驱动表(符合“小表驱动大表”的说法)。
2.2 Order by 算法原理
2.2.1 全字段排序
MySQL会为每个线程分配一块内存(Sort buffer)用于排序,当Sort buffer的空间不足时(通过系统参数sort_buffer_size设置Sort buffer的大小),执行引擎不得不开辟磁盘临时文件用于排序,此时排序的性能也会大幅降低。
全字段排序是将查询需要的所有字段进行暂存,并按照排序字段进行排序,并将排序后的结果集直接返回。
2.2.2 Rowid 排序
若要查询的数据单行占用空间较大,Sort buffer中可以容纳的排序行数将会减少,此时使用磁盘临时文件进行排序的概率将会增大。为了提高排序性能,执行引擎提供一种只存储排序字段的算法,称为Rowid排序算法。
该算法的步骤为:
将参与排序的字段和主键进行临时存储;
按照排序字段进行排序,得到有序的主键;
根据有序的主键进行回表,按顺序将所有要查询的数据返回。
Rowid排序在单行查询数据较大时可以通过节省临时排序空间从而达到降低排序开销的目的,然而该算法的代价是会增加磁盘扫描的次数(主键回表),所以是否选择使用该算法需要根据实际情况进行取舍(通过系统参数max_length_for_sort_data设置)。
3、调优过程
3.1 执行过程分析
了解了Join和Order by的工作原理,我们推测执行计划的大致过程为:
t_table_1与t_table_2进行Join查询,使用了BNL算法(Using join buffer (Block Nested Loop))
将Join的结果暂存临时表(Using temporary)
对临时表中的数据进行排序后返回(Using filesort)
为了佐证笔者的推测以及了解每一步的开销情况,Optimizer_trace命令可以提供更多执行过程细节。
{
"considered_execution_plans": [
{
"table": "`t_table1` `t1`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 3000,
"access_type": "scan",
"resulting_rows": 3000,
"cost": 615,
"chosen": true,
"use_tmp_table": true
}
] /* considered_access_paths */
} /* best_access_path */,
"rest_of_plan": [
{
"table": "`t_table2` `t2`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 69882,
"access_type": "scan",
"using_join_cache": true,
"buffers_needed": 5,
"resulting_rows": 69882,
"cost": 4.19e7,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"rows_for_plan": 2.1e8,
"cost_for_plan": 4.19e7,
"sort_cost": 2.1e8,
"new_cost_for_plan": 2.52e8,
"chosen": true
}
] /* rest_of_plan */
}
] /* considered_execution_plans */
}
上图展示的即为执行引擎预估的执行计划,从Optimizer_trace的输出结果中可以佐证上述对于执行过程的推测。另外我们可以得到执行代价的结果为:
t_table1的扫描行数为3000,代价为615;
t_table2的扫描行数为69882,由于BNL算法t_table2会被多次全表扫描,整体代价为4.19e7;
对Join结果进行排序的开销为2.1e8。
从执行引擎预估的执行计划可以看出执行引擎认为排序的开销最大,另外由于使用BNL算法会导致被驱动表执行多次全表扫描,其执行代价仅次于排序。然而预估的执行计划并不代表真正的执行结果,下面展示Optimizer_trace命令对于真实执行结果部分参数:
{
"join_execution": {
"select#": 1,
"steps": [
{
"creating_tmp_table": {
"tmp_table_info": {
"table": "intermediate_tmp_table",
"row_length": 655,
"key_length": 0,
"unique_constraint": false,
"location": "memory (heap)",
"row_limit_estimate": 25614
} /* tmp_table_info */
} /* creating_tmp_table */
},
{
"filesort_summary": {
"rows": 3000,
"examined_rows": 3000,
"number_of_tmp_files": 0,
"sort_buffer_size": 60200,
"sort_mode": "<sort_key, rowid>"
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
从执行结果参数来看:
执行引擎使用临时表保存Join的结果,且临时表是一张内存表。
参与排序的数据行数为3000行,没有使用磁盘临时文件进行排序,排序算法选择的是Rowid排序。
综合执行引擎的预估的执行计划和真实的执行结果参数可以得出,执行引擎预估最大的执行开销为排序,但实际上排序并未使用到磁盘临时文件,且Rowid排序的回表操作是在内存中进行的(在内存临时表中进行回表),3000条数据的内存排序开销是极快的,所以真实的最大开销是BNL算法导致的对被驱动表多次进行全表扫描的开销。
3.2 最终的优化
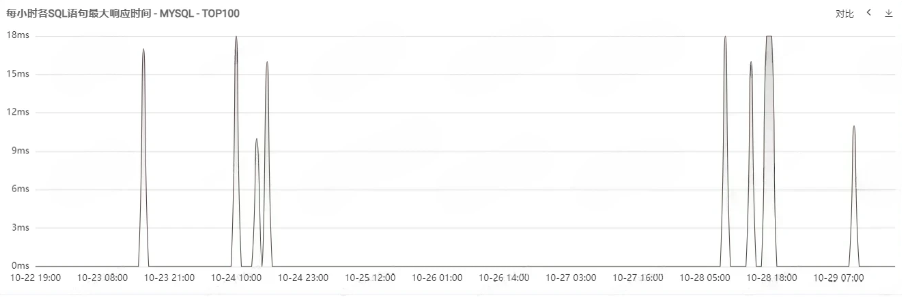
对于BNL算法,可以通过在被驱动表添加索引使其转化为NLJ算法来进行优化(此处注意一些索引失效的场景,笔者在实际调优中遇到了字符集不同导致的索引失效场景)。在t_table2表添加索引后,观察一周内的SQL监控如下,可以看到SQL最大响应时间不超过20ms,执行效率得到了大幅提升。
4、总结
本文完整的介绍了一个SQL调优案例,通过这个案例可以归纳出SQL调优的基本思想。首先,需要了解SQL语句中的关键字(Join、Order by...)的基本工作原理,并辅助一些执行过程数据(Explain、Optimizer_trace),通过实验验证猜想,最终达成调优的目的。
慢SQL优化实战:从一例线上慢SQL探究执行引擎工作过程的更多相关文章
- Hive使用Calcite CBO优化流程及SQL优化实战
目录 Hive SQL执行流程 Hive debug简单介绍 Hive SQL执行流程 Hive 使用Calcite优化 Hive Calcite优化流程 Hive Calcite使用细则 Hive向 ...
- SQL优化实战之加索引
有朋友和我说他的虚机里面的mysql无法跑sql,但是在本地环境是这个sql是可以跑出来的.碰到这个问题第一反应是:死锁. 于是让他查询数据库的几个状态: 发现连即时锁都非常少,不是锁的问题. 进一步 ...
- sql优化实战:从1353秒到135秒(删除索引+修改数据+重建索引)
最近在优化日结存储过程,日结存储过程中大概包含了20多个存储过程. 发现其有一个存储过程代码有问题,进一步发现结存的数据中有一个 日期字段business_date 是有问题的,这个字段对应的类型是v ...
- SQL语句优化 -- 以Mysql为例
本文参考下面的文章: 1: [真·干货]MySQL 索引及优化实战 2: Mysql语句的执行过程 3: sql优化的几种方法 我将 sql语句优化分为三个方面,(此处不包括 业务逻辑的 ...
- SQL优化指南
慢查询日志 开启撒网模式 开启了MySQL慢查询日志之后,MySQL会自动将执行时间超过指定秒数的SQL统统记录下来,这对于搜罗线上慢SQL有很大的帮助. SHOW VARIABLES LIKE 's ...
- 性能优化之永恒之道(实时sql优化vs业务字段冗余vs离线计算)
在项目中,随着时间的推移,数据量越来越大,程序的某些功能性能也可能会随之下降,那么此时我们不得不需要对之前的功能进行性能优化.如果优化方案不得当,或者说不优雅,那可能将对整个系统产生不可逆的严重影响. ...
- 基于Oracle的SQL优化(社区万众期待 数据库优化扛鼎巨著)
基于Oracle的SQL优化(社区万众期待数据库优化扛鼎巨著) 崔华 编 ISBN 978-7-121-21758-6 2014年1月出版 定价:128.00元 856页 16开 编辑推荐 本土O ...
- SQL优化的若干原则
SQL语句:是对数据库(数据)进行操作的惟一途径:消耗了70%~90%的数据库资源:独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低:可以有不同的写法:易 ...
- 史上最全存储引擎、索引使用及SQL优化的实践
史上最全存储引擎.索引使用及SQL优化的实践 1 MySQL的体系结构概述 2. 存储引擎 2.1 存储引擎概述 2.2 各种存储引擎特性 2.2.1 InnoDB 2.2.2 MyISAM 3. 优 ...
- 工作中遇到的99%SQL优化,这里都能给你解决方案
前几篇文章介绍了mysql的底层数据结构和mysql优化的神器explain.后台有些朋友说小强只介绍概念,平时使用还是一脸懵,强烈要求小强来一篇实战sql优化,经过周末两天的整理和总结,sql优化实 ...
随机推荐
- java RSA公私钥生成工具类
package cn.daenx.my.util; import java.security.*; import java.security.spec.PKCS8EncodedKeySpec; imp ...
- 图扑软件 | 带你体验 Low Poly 卡通三维世界
在三维场景搭建中,图扑软件提供了多样化的设计风格,以满足不同项目的视觉需求.无论是写实风格的细腻渲染.科幻未来的赛博质感,还是简约现代的几何美学,都能通过灵活的工具体系实现.而今天,我们将重点介绍一种 ...
- 关于打高版本java,cc6复现
关于打高版本java,cc6复现 从上一篇的cc1中我们发现他不能作用在jdk_8u71以上的版本,因此;为了解决这个问题,引入了cc6 之所以不能用cc1打高版本,是由于在Java 8u71以后, ...
- CentOS 使用 IUS _ SCL 第三方软件源
CentOS 使用 IUS / SCL 第三方软件源 使用centos 经常发现官方提供的软件包版本过低,很多时候大家会选择下载源码自行编译,带来了很多麻烦. centos安装最新版本软件包,例如gi ...
- 【前端AI实践】泛谈AI实践:技术大牛们早就在用的AI在前端领域的场景
写代码有时候就像点外卖 -- 你得选对工具.用好方法,才能又快又好地解决问题.AI 就像是你编程路上的"厨房助手",帮你搞定重复劳动.理清逻辑.甚至还能给你提建议. 下面我们就从几 ...
- 不得不说一下vite
vite简介 Vite 是一个由原生 ESM 驱动的 Web 开发构建工具.在开发环境下基于浏览器原生 ES imports 开发,在生产环境下基于 Rollup 打包. vite作用 快速的冷启动: ...
- 学习CAE软件有什么方法技巧?
在工程设计和制造领域,计算机辅助工程(CAE)软件已经成为不可或缺的工具.然而,学习使用这类复杂软件需要投入大量时间和精力.为了帮助您更快地掌握CAE软件,本文将分享一些高效的学习方法与技巧. 明确学 ...
- ET5.0运行--基础
nodejs转c#,刚刚开始使用ET,在运行Demo中记录了一下. ET5.0 githu: https://github.com/egametang/ET/tree/Branch_V5.0 环境: ...
- git 在C# 中常用的忽略文件配置
.gitignore文件 .vs *.vssscc obj bin /packages *.vspscc */Properties/PublishProfiles *.log 简易的命令行入门教程: ...
- Luogu P7276 送给好友的礼物 题解
P7276 送给好友的礼物 我们充分发扬人类智慧. 首先分析性质,如果一个有草莓的节点子树中存在有草莓的节点,那么我们就直接不管这个有草莓的节点,因为首先子树内的草莓已经会遍历这个点. 另外,根据 P ...