Flink mysql-cdc同步主键分布不均匀的mysql表
一、背景
1、遇到问题描述
通过Flink同步mysql到iceberg中,任务一直在运行中,但是在目标表看不到数据。经排查发现job manager一直在做切片工作,切了一小时还没开始同步数据,日志如下:
2023-12-28 16:58:36.251 [snapshot-splitting] INFO com.ververica.cdc.connectors.mysql.source.assigners.ChunkSplitter [] - ChunkSplitter has split 600 chunks for table
2023-12-29 14:06:08.754 [snapshot-splitting] INFO com.ververica.cdc.connectors.mysql.source.assigners.ChunkSplitter [] -
The distribution factor of table sn_source.leads_data is 3.894905163297E8 according to the min split key 14415117481467904, max split key 200015469389810688 and approximate row count 476520850二、Flink全量阶段核心设计
1、数据切片划分
全量阶段数据读取方式为分布式读取,会先对当前表数据按主键划分成多个Chunk,后续子任务读取Chunk 区间内的数据。根据主键列是否为自增整数类型,对表数据划分为均匀分布的Chunk及非均匀分布的Chunk。
(1)均匀分布方式(数值类型)
满足主键列自增且类型为整数类型(int,bigint,decimal)。查询出主键列的最小值,最大值,按 chunkSize 大小将数据均匀划分,因为主键为整数类型,根据当前chunk 起始位置、chunkSize 大小,直接计算 chunk 的结束位置。
注意:最新版本均匀分布的触发条件不再依赖主键列是否自增,要求主键列卫整数类型且根据 max(id) - min(id)/rowcount 计算出数据分布系数,只有分布系数 <= 配置的分布系数 (evenly-distribution.factor 默认为 1000.0d) 才会进行数据均匀划分。
// 计算主键列数据区间
select min(`order_id`), max(`order_id`) from demo_orders;
// 将数据划分为 chunkSize 大小的切片
chunk-0: [min,start + chunkSize)
chunk-1: [start + chunkSize, start + 2chunkSize)
.......
chunk-last: [max,null)(2)非均匀分布方式(字符串或时间戳等其它类型)
主键列非自增或者类型为非整数类型。主键为非数值类型,每次划分需要对未划分的数据按主键进行升序排列,取出前 chunkSize 的最大值为当前 chunk 的结束位置。
注意:最新版本非均匀分布触发条件为主键列为非整数类型,或者计算出的分布系数 (distributionFactor) > 配置的分布系数 (evenly-distribution.factor)。
// 未拆分的数据排序后,取 chunkSize 条数据取最大值,作为切片的终止位置。
chunkend = SELECT MAX(`order_id`) FROM (
SELECT `order_id` FROM `demo_orders`
WHERE `order_id` >= [前一个切片的起始位置]
ORDER BY `order_id` ASC
LIMIT [chunkSize]
) AS T
真实执行sql
SELECT MAX(`leads_id`) FROM (SELECT `leads_id` FROM `sn_source`.`leads_data`
WHERE `leads_id` >= 152117209080009728 ORDER BY `leads_id` ASC LIMIT 50000) AS T2、全量切片数据读取
Flink 将表数据划分为多个 Chunk,子任务在不加锁的情况下,并行读取 Chunk 数据。因为全程无锁在数据分片读取过程中,可能有其他事务对切片范围内的数据进行修改,此时无法保证数据一致性。因此,在全量阶段 Flink 使用快照记录读取 + Binlog 数据修正的方式来保证数据的一致性。
三、mysql-cdc连接器参数
|
参数
|
说明
|
是否必填
|
备注
|
|
connector
|
源表类型
|
是
|
固定值为mysql-cdc
|
|
hostname
|
MySQL 数据库的 IP 地址或者 Hostname
|
是
|
-
|
|
port
|
MySQL 数据库服务的端口号
|
否
|
默认值为3306
|
|
username
|
MySQL 数据库服务的用户名
|
是
|
有特定权限(包括 SELECT、RELOAD、SHOW DATABASES、REPLICATION SLAVE 和 REPLICATION CLIENT)的 MySQL 用户
|
|
password
|
MySQL 数据库服务的密码
|
是
|
-
|
|
database-name
|
MySQL 数据库名称
|
是
|
数据库名称支持正则表达式以读取多个数据库的数据
|
|
table-name
|
MySQL 表名
|
是
|
表名支持正则表达式以读取多个表的数据
|
|
server-id
|
数据库客户端的一个 ID
|
否
|
该 ID 必须是 MySQL 集群中全局唯一的。建议针对同一个数据库的每个作业都设置不同的 ID 范围值,例如
5400-5405。默认会随机生成一个6400 - Integer.MAX_VALUE 的值 |
|
server-time-zone
|
数据库在使用的会话时区
|
否
|
例如 Asia/Shanghai,该参数控制了 MySQL 中的 TIMESTAMP 类型如何转成 STRING 类型
|
|
append-mode
|
开启 append 流模式
|
否
|
Flink1.13及以上版本支持, 例如:将 mysql-cdc 数据以 append 的方式同步到 hive
|
|
filter-duplicate-pair-records
|
过滤未在 Flink DDL 语句中定义的源表字段变更记录
|
否
|
例如 MySQL 源表有 a, b, c, d 四个字段,而用户在 Flink SQL 建表时只定义了 a, b 两个字段;开启该参数后,仅涉及 c 或 d 字段的变更记录会被忽略,不会输出到下游,可减少计算量和处理压力
|
|
scan.lastchunk.optimize.enable
|
对全量阶段的最后一个分片做重划分
|
否
|
如果全量同步期间,源表持续有大量写入和变更,则可能导致最后一个分片过大,引起 TaskManager OOM 崩溃重启。 开启本功能后(值设置为 true),Flink 会自动将过大的最后一个分片分成若干的小分片,提升作业的稳定性
|
|
debezium.min.row.count.to.stream.results
|
当表的条数大于该值时,会使用分批读取模式
|
否
|
默认值为1000。Flink 采用以下方式读取 MySQL 源表数据:
全量读取:直接将整个表的数据读取到内存里。优点是速度快,缺点是会消耗对应大小的内存,如果源表数据量非常大,可能会有 OOM 风险
分批读取:分多次读取,每次读取一定数量的行数,直到读取完所有数据。优点是读取数据量比较大的表没有 OOM 风险,缺点是读取速度相对较慢
|
|
debezium.snapshot.fetch.size
|
在 Snapshot 阶段,每次读取 MySQL 源表数据行数的最大值
|
否
|
仅当分批读取模式时,该参数生效
|
|
debezium.skipped.operations
|
需要过滤的 oplog 操作。操作包括 c 表示插入,u 表示更新,d 表示删除。默认情况下,不跳过任何操作,以逗号分隔
|
否
|
-
|
|
scan.incremental.snapshot.enabled
|
增量快照
|
否
|
默认为 true
增量快照是一种读取表快照的新机制,与旧的快照机制相比, 增量快照有许多优点,包括: (1)在快照读取期间,Source 支持并发读取, (2)在快照读取期间,Source 支持进行 chunk 粒度的 checkpoint, (3)在快照读取之前,Source 不需要数据库锁权限。 如果希望 Source 并行运行,则每个并行 Readers 都应该具有唯一的 Server id,所以 Server id 必须是类似 `5400-6400` 的范围,并且该范围必须大于并行度。 请查阅 增量快照读取 章节了解更多详细信息。
|
|
scan.incremental.snapshot.chunk.size
|
当读取表的快照时,表快照捕获的表的块大小(行数)
|
否
|
默认为 8096
|
|
scan.lazy-calculate-splits.enabled
|
全量阶段JM中数据分片懒加载避免数据量太大,分片数据太多导致JM OOM
|
否
|
默认为 true
|
|
scan.snapshot.fetch.size
|
读取表快照时每次读取数据的最大条数。 |
否
|
默认1024
|
|
scan.newly-added-table.enabled
|
否
|
默认为 false
|
|
|
scan.split-key.mode
|
联合主键作为 splitkey 的模式
|
否
|
取值为 default / specific;其中 default 为默认逻辑,采用联合主键的第一个字段作为 split key;设置为 specific 需要设置 scan.split-key.specific-column 指定联合主键中的某个字段
|
|
scan.split-key.specific-column
|
指定联合主键中某个字段作为 splitkey
|
否
|
当 scan.split-key.mode 为 specific 时必填。取值为联合主键中某个字段名
|
|
scan.startup.mode
|
MySQL CDC 消费者可选的启动模式
|
否
|
合法的模式为 "initial"(默认),"earliest-offset","latest-offset","specific-offset" 和 "timestamp"
|
|
scan.startup.specific-offset.file
|
在 "specific-offset" 启动模式下,启动位点的 binlog 文件位置
|
否
|
-
|
|
scan.startup.specific-offset.pos
|
在 "specific-offset" 启动模式下,启动位点的 binlog 文件位置
|
否
|
-
|
|
scan.startup.specific-offset.gtid-set
|
在 "specific-offset" 启动模式下,启动位点的 GTID 集合
|
否
|
-
|
|
scan.startup.timestamp-millis
|
在 "timestamp" 启动模式下,启动时间的毫秒时间戳
|
否
|
-
|
|
scan.startup.specific-offset.skip-events
|
在指定的启动位点后需要跳过的事件数量
|
否
|
-
|
|
scan.startup.specific-offset.skip-rows
|
在指定的启动位点后需要跳过的数据行数量
|
否
|
-
|
|
connect.timeout
|
尝试连接到 MySQL 数据库服务器后在超时之前等待的最长时间
|
否
|
默认 30s
|
|
connect.max-retries
|
建立MySQL连接尝试最大的次数
|
否
|
默认 3
|
|
connection.pool.size
|
连接池大小
|
否
|
默认 20
|
|
jdbc.properties.*
|
自定义JDBC URL参数,例如:
'jdbc.properties.useSSL' = 'false' |
否
|
默认 20
|
|
heartbeat.interval
|
发送心跳事件的时间间隔,用于跟踪最新可用的binlog偏移量, 一般用于解决慢表的问题(更新缓慢的数据表)
|
否
|
默认 20
|
|
debezium.*
|
Debezium 属性参数
|
否
|
从更细粒度控制 Debezium 客户端的行为。例如
'debezium.snapshot.mode' = 'never',详情请参见 配置属性 |
四、调整后效果
1、调整内容
块大小调为20万:'scan.incremental.snapshot.chunk.size'='200000'
因job manager扫描是顺序执行,探查一个chunk大小1-4秒,总体特别费时。checkpoint失败固定次数后job manager会重启,调整检查点超时时间为5小时,这样最多可探查时间5小时。
2023-12-29 14:06:08.754 [snapshot-splitting] INFO com.ververica.cdc.connectors.mysql.source.assigners.ChunkSplitter [] -
The distribution factor of table database.test is 3.894905163297E8 according to the min split key 14415117481467904, max split key 200015469389810688 and approximate row count 4765208502023-12-29 17:42:39.784 [snapshot-splitting] INFO com.ververica.cdc.connectors.mysql.source.assigners.ChunkSplitter [] -
ChunkSplitter has split 2580 chunks for table database.test
2023-12-29 17:43:19.462 [snapshot-splitting] INFO com.ververica.cdc.connectors.mysql.source.assigners.LazyChunkSplitter [] -
Split table database.test into 2591 chunks, time cost: 13032688ms.开始抽取数据
2023-12-29 17:43:19.464 [SourceCoordinator-Source: source_ods_sn_source_leads_data[1]] INFO com.ververica.cdc.connectors.mysql.source.assigners.MySqlSnapshotSplitAssigner [] -
Snapshot split MySqlSnapshotSplit{tableId=database.test, splitId='database.test:0', splitKeyType=[`leads_id` BIGINT NOT NULL], splitStart=null, splitEnd=[14415117481467904], highWatermark=null} is going to be assigned. Current assigned splits: 1/25913、业务库负载
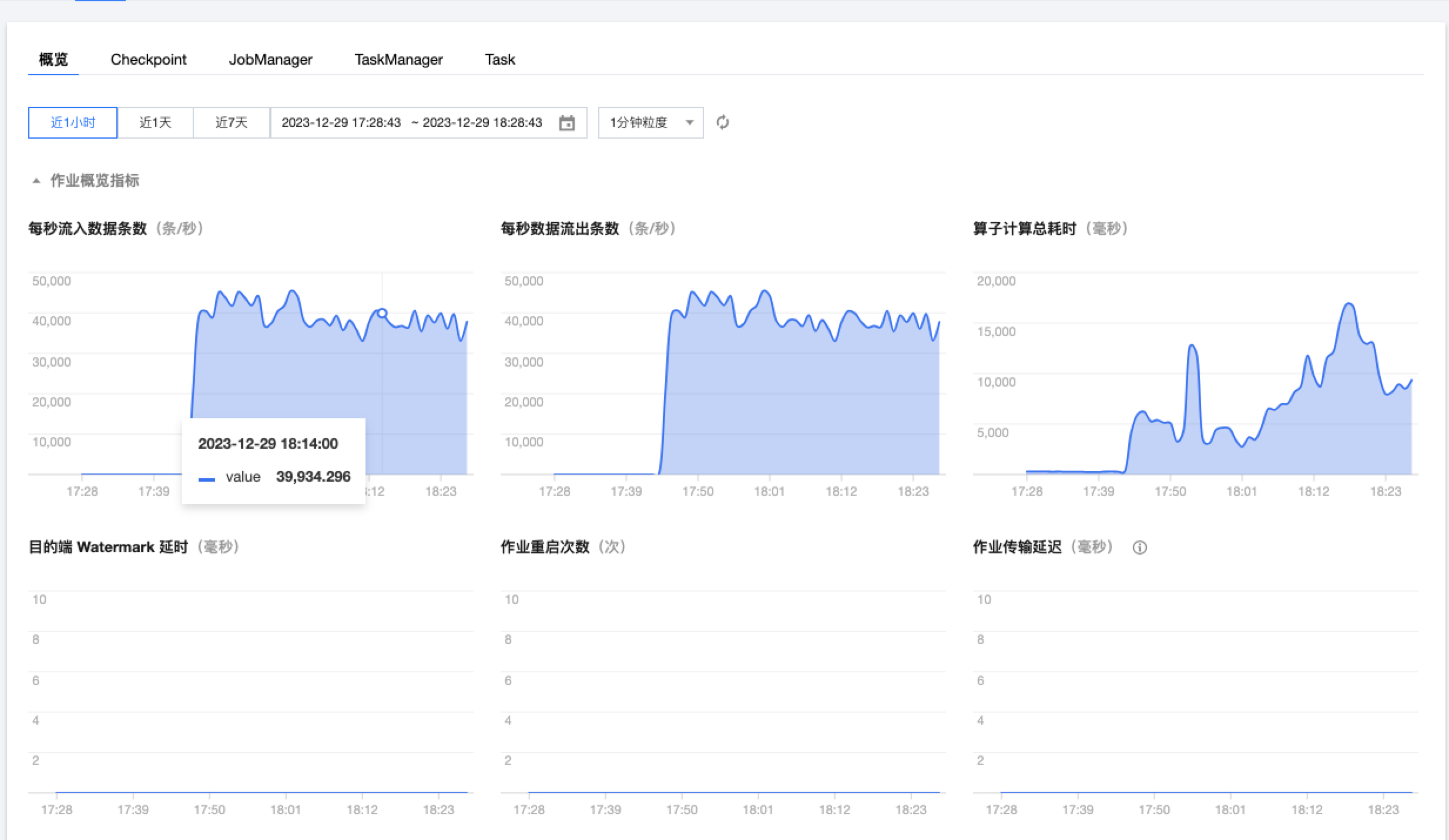
4核 16GB 阿里polardb数据库,在切片阶段,业务库无明显负载,抽数阶段开10*1CU,负载波动不大,可适当调大并发
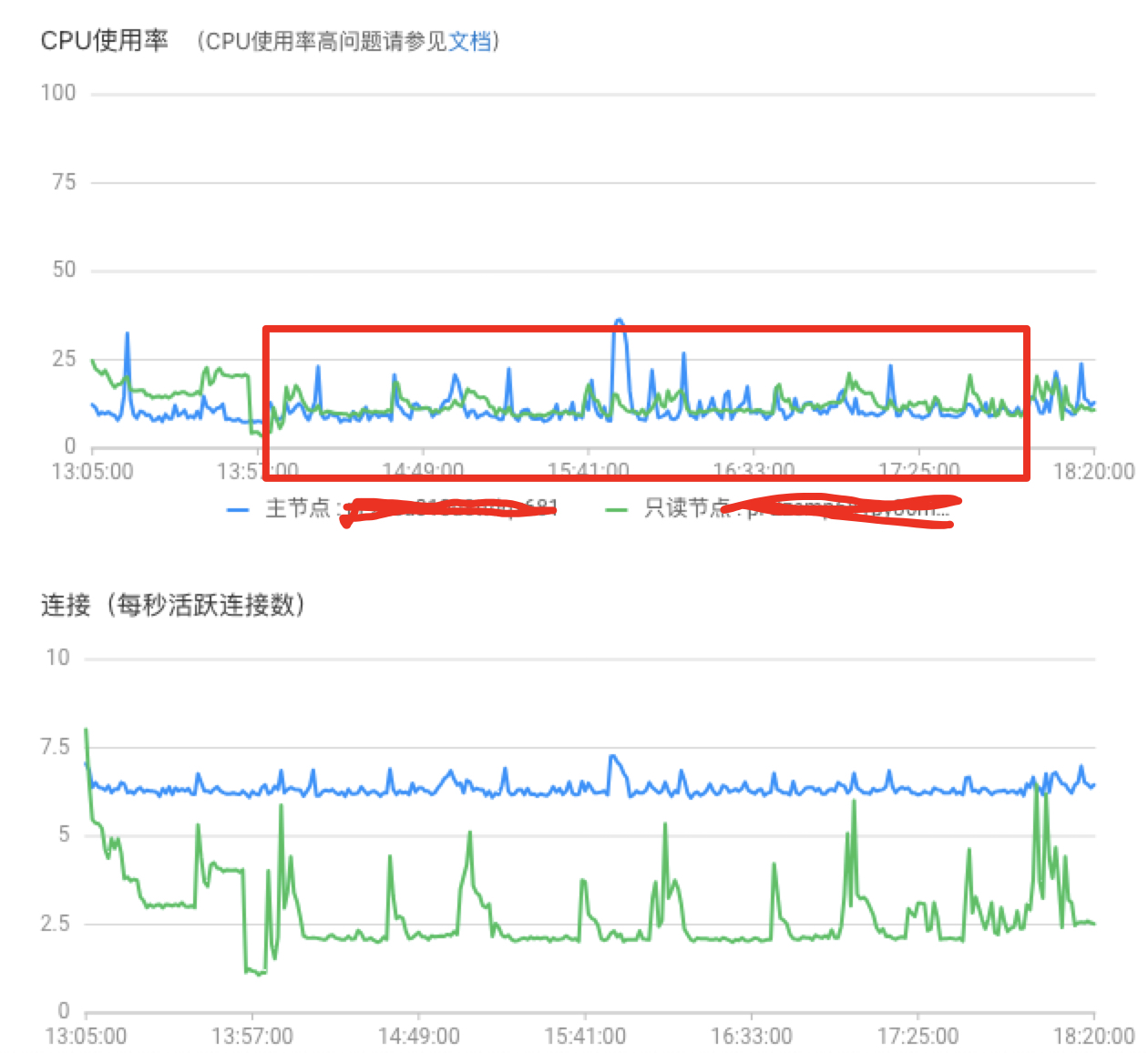
数据抽取速度4-5万条/s
参考博客:https://developer.aliyun.com/article/801797
https://ververica.github.io/flink-cdc-connectors/release-2.2/content/connectors/mysql-cdc%28ZH%29.html#a-name-id-001-a
Flink mysql-cdc同步主键分布不均匀的mysql表的更多相关文章
- mybatis的执行流程 #{}和${} Mysql自增主键返回 resultMap 一对多 多对一配置
n Mybatis配置 全局配置文件SqlMapConfig.xml,配置了Mybatis的运行环境等信息. Mapper.xml文件即Sql映射文件,文件中配置了操作数据库的Sql语句.此文件需要在 ...
- mysql中,主键与普通索引
一.什么是索引?索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表里 ...
- MySQL与Oracle主键Query性能测试结果
测试结果总结如下: 1. 按主键读:SQL形式:SELECT * FROM table WHERE id=?. 1.1. 主键为数字.如果所有ID均不存在,纯比较SQL解析能力.MySQL解析SQL的 ...
- Mysql 创建联合主键
Mysql 创建联合主键2008年01月11日 星期五 下午 5:21使用primary key (fieldlist) 比如: create table mytable ( ...
- MySQL中的主键,外键有什么作用详解
MySQL中的主键,外键有什么作用详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 学关系型数据库的同学,尤其在学习主键和外键时会产生一定的困惑.那么今天我们就把这个困惑连根拔起 ...
- 关于MySQL自增主键的几点问题(上)
前段时间遇到一个InnoDB表自增锁导致的问题,最近刚好有一个同行网友也问到自增锁的疑问,所以抽空系统的总结一下,这两个问题下篇会有阐述. 1. 划分三种插入类型 这里区分一下几种插入数据行的类型,便 ...
- mysql死锁-非主键索引更新引起的死锁
背景:最近线上经常抛出mysql的一个Deadlock,细细查来,长了知识! 分析:错误日志如下: 21:02:02.563 ERROR dao.CommonDao [pool-15-t ...
- mysql update获取主键
mysql update获取主键<pre>SET @update_id := 0;UPDATE mobantestinfo1 SET info2 = 'value', id = (SELE ...
- mysql自增主键字段重排
不带外键模式的 mysql 自增主键字段重排 1.备份表结构 create table table_bak like table_name; 2.备份表数据 insert into table_bak ...
- mysql 原有的主键情况下设置自增字段
mysql 的自增字段只能是主键,如果原表已经有主键,需要设置自增字段应该怎么做呢? 1.alter table bu_staff drop primary key; 先删除表的主键 id为原表 ...
随机推荐
- vue2-路由Router
Vue 中的路由用于实现单页应用(SPA)中的页面导航.它允许你在不刷新整个页面的情况下,根据不同的 URL 路径显示不同的组件,提供了类似于多页面应用的用户体验.例如,在一个电商应用中,可以通过 ...
- UUID和雪花(Snowflake)算法该如何选择?
UUID 和 Snowflake 都可以生成唯一标识,在分布式系统中可以说是必备利器,那么我们该如何对不同的场景进行不同算法的选择呢,UUID 简单无序十分适合生成 requestID, Snowfl ...
- Vue.js slot插槽
1.插槽的基本用法 组件的插槽允许用户将其他组件或者html片段插入到组件当中 // App.vue <template> <div id="app"> & ...
- canvas(五)绘制文本
1.绘制描边文本 说明:描边的属性是共用的,无论是绘制直线还是文字,所以有需要的话要单独设置描边颜色,相关语法如下 语法 说明 ctx.strokeStyle 设置描边的颜色(文本颜色) ctx.fo ...
- Prime2_解法二:openssl解密凭据
Prime2_解法二:openssl解密凭据 本博客提供的所有信息仅供学习和研究目的,旨在提高读者的网络安全意识和技术能力.请在合法合规的前提下使用本文中提供的任何技术.方法或工具.如果您选择使用本博 ...
- 论文解读《The Philosopher’s Stone: Trojaning Plugins of Large Language Models》
发表时间:2025 期刊会议:Network and Distributed System Security (NDSS) Symposium 论文单位:Shanghai Jiao Tong Univ ...
- vscode本地调试gitbook
1. windows下载安装git 2.安装nodejs 下载安装nvm https://github.com/coreybutler/nvm-windows/releases/download/1. ...
- 2.猿人学爬虫攻防第二题 JS 混淆 动态cookie
题目链接:请点击 抓取到发布日热度的值,计算所有值的加和 1.分析网页 由于是动态Cookie,为了避免其他Cookie的影响,所以使用浏览器的无痕模式进行调试,按f12并选中[Preserve lo ...
- Qt数据库应用3-数据打印到pdf
一.前言 自从数据可以导出到xls,又有客户提出了不同的需求,比如既然可以将数据导出到xls,那是否可以导出到pdf文件呢?因为xls打开以后用户可以修改数据造假之类的,而pdf默认是不可编辑的,除非 ...
- Qt编写安防视频监控系统51-功能激活
一.前言 随着视频监控系统本身功能的增多,以及用户定制功能的增多(比如视频监控系统摇身一变成了机器人监控.无人机监控.挖掘机监控等),除了提供工作模式这个切换开关,还需要对不同的工作模式启用禁用不同的 ...