python 阿狸的进阶之路(5)
一.模块
1.什么是模块:
包含了一组功能的python文件,文件名是xxx.py,模块名是module.
可以使用 import module,四个通用的类别:
(1)用python编写的py文件
(2)已经编译为共享库或DLL的c或c++扩展
(3)把一系列模块组织到一起的文件夹(一般在文件夹下设置__init__.py,该文件夹称之为包)
(4)使用c编写并且连接到python解释器的内置模块
2.模块的使用场景
(1)从文件级别组织程序,更方便管理
(2)拿来主义,节省时间,提升开发效率
3.如何使用模块
import 模块名(spam)
<1>.第一次导入模块发生的事件
(1)先产生一个新的命名空间
(2)运行源文件(spam)代码,产生的名字都存放于(1)的名称空间中,
运行过程中global的关键字指向的就是该命名空间
即在全局的命名空间中,开辟出一个模块名(spam)的命名空间,
(3)在当前的名称空间拿到一个名字spam,该名字指向1的命名空间
引用spam.py中的名称的方式: spam.xxx
(4)重复导入模块 import spam 重新引用的意思,并不会重新执行。
重点:被导入的模块在执行过程中使用自己独立的名称空间作为全局名称空间
<2>.别名: import spam as sm
(1)用途一:模块名字太长可以进行缩短
(2)用途二:利用别名进行判断
<3>.可以在一行导入多个模块:import time,os
engine =input ('>>:')
if engine == 'myslq':
import mysql as sql
elif engine == 'oracle':
import orcle as sql
sql.parse()
<4>.如何使用模块--》from 模块名 import 名字
优点,引用时不用加前缀,简单
缺点,有可能跟当前名称空间的名字冲突
from spam import money as m
from spam import * (用于模块太多的时候,但是你不知道你导入的都是什么模块)
(而且*包含了除了下划线开头的以外的所有的名字)
可以在模块的文件中写入一个列表: __all__ = ['read1', 'read2']
这时候 import * 导入的就是__all__ 列表中的变量或者函数了。
4. python 为每个文件都内置了一个变量 print (__name__)
一个python文件的两种用途
<1>当做脚本执行: __name__ == ' __main__'
<2>当做模块被导入使用: __name__ == '模块名'
可以使用测试功能:(控制文件的两种用途)
if __name__ == '__main__': #利用文件__name__属性,如果当做脚本运行,则打印read1函数
print(read1())
6.模块的搜索路径
内存----》内置模块---》sys.path(环境变量) (以执行文件为准)
import sys
print(sys.path) #打印当前的环境变量 ['F:\\pycharm\\python\\day5', 'F:\\pycharm', 'F:\\Python30\\python36.zip', 'F:\\Python30\\DLLs', 'F:\\Python30\\lib', 'F:\\Python30', 'F:\\Python30\\lib\\site-packages']
打印出来是个列表,如果想要新加入环境变量,则可以sys.path.append() 加入之后就可找到模块
内置模块如果没有导入,则不会出现在内存中。
import package1
print(package1.x)
import sys
print('time' in sys.modules)
import time
print('time' in sys.modules)
print('package1' in sys.modules )
查看包有没有导入成功
ps: sys.modules是一个字典,模块名字为key
二.包
1.什么是包
包就是包含了__init__.py 文件的文件夹(可以往该文件夹下放一堆子模块)
python2 中必须有 __init__.py
python3中可以没有这个文件
__init__.py文件说明:
相当于package的名称空间
这个文件的作用是将文件夹下的模块,进行组合
当在一个文件中导入包时,先在本目录下找包的名字,然后直接进入 __init__文件查找,
在__init__.py 中可以写变量,函数,也可以写路径,即在__init__.py文件
中能导入的模块(导包时写全路径,即从执行文件开始直接找路径),
其他文件在能找到__init__.py的前提下也能导入。
example:
文件关系如下,import为执行文件,package1文件夹下有__init__.py m1.py 和package2文件夹,package2文件夹下有__init__.py n1.py
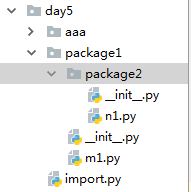
import package1
print(package1.m1)
print(package1.m1.funcm)
print(package1.package2)
print(package1.package2.n1.funcn)
import.py(执行文件)
x =1
from package1 import m1
from package1 import package2
package1下的__init__.py
x= 10000000
def funcm():
print('m1m1m1m1m1m1m1m1')
package1下的m1.py
from package1.package2 import n1
package2下的__init__.py
def funcn():
print('n1n1n1n1n1n1n1n1n1')
package2下的n1.py
2.相对导入和绝对导入
相对导入用 ‘’ .‘’ 一个点表示本文件的顶级目录,之后以此类推。例如 from .package2 import m1
绝对导入 直接写全用户路径 例如:from package1.package2 import m1 (注意:'.'的左边必须是包)
3. 如果包和执行文件不在一个地方,在执行文件中,将包的文件夹导入环境变量即可
可能用到的模块,sys os.path.abspath(__file__)当前文件的绝对路径,__file__为内置变量,
os.path.dirname(“文件的路径”) 文件的目录
4.软件开发规范
python 阿狸的进阶之路(5)的更多相关文章
- python 阿狸的进阶之路(9)
tcp传输: 传输需要ack回应,然后才清空缓存,服务端先起来. tcp流式协议,tcp的Nagle的优化算法,会将时间间隔短,数据量小的打包成一个,然后发送给对方,减少发送的次数. UDP协议: 不 ...
- python 阿狸的进阶之路(6)
常用模块 json # 序列化 #将内存的数据存到硬盘中,中间的格式,可以被多种语言识别,跨平台交互数据 #json 可以将字典之类的数据类型存到字典中 import json dic = {&quo ...
- day3 python 阿狸的进阶之路
函数概念: 1.为什要有函数 组织结构不清晰,可读性差,代码冗余,可扩展性差. 2.什么是函数 具备某一个功能的工具--->函数 事先准备工具->函数的定义 拿来就用. ...
- python 阿狸的进阶之路(8)
异常处理 http://www.cnblogs.com/linhaifeng/articles/6232220.html(转) 网络编程socket http://www.cnblogs.com/li ...
- python 阿狸的进阶之路(7)
面向对象 转自林海峰的博客 http://www.cnblogs.com/linhaifeng/articles/6182264.html 面向对象的理解: 将数据分类,比如学生类.数据有关的函数, ...
- python 阿狸的进阶之路(4)
装饰器 #1.开放封闭原则:对扩展开放,对修改是封闭#2.装饰器:装饰它人的,器指的是任意可调用对象,现在的场景装饰器->函数,被装饰的对象也是->函数#原则:1.不修改被装饰对象的源代码 ...
- Python 从入门到进阶之路(一)
人生苦短,我用 Python. Python 无疑是目前最火的语言之一,在这里就不再夸他的 NB 之处了,本着对计算机编程的浓厚兴趣,便开始了对 Python 的自学之路,并记录下此学习记录的心酸历程 ...
- Python 从入门到进阶之路(七)
之前的文章我们简单介绍了一下 Python 中异常处理,本篇文章我们来看一下 Python 中 is 和 == 的区别及深拷贝和浅拷贝. 我们先来看一下在 Python 中的双等号 == . == 是 ...
- Python 从入门到进阶之路(六)
之前的文章我们简单介绍了一下 Python 的面向对象,本篇文章我们来看一下 Python 中异常处理. 我们在写程序时,有可能会出现程序报错,但是我们想绕过这个错误执行操作.即使我们的程序写的没问题 ...
随机推荐
- 查看app日志的方法
可以打开SDk里面的 ddms.bat 查看日志 路径: android-sdk-macosx/tools/ddms SDK下载的地址: http://www.androiddevtools.cn/ ...
- 循环语句中,break和continue分别有什么作用?
break用于强行退出循环,不执行循环中剩余的语句 continue用于跳过本次循环, 不执行continue后的语句, 继续下一次循环
- switch语句的功能是否完全可以使用if else多选择结构来代替?如果是,为什么还需要switch结构?
- [UE4]如何编译部署独立专用服务端(Standalone Dedicated Server)
这是论坛上对UE服务端功能的回答,意思是UE4提供了网游服务端所具备的特性,包括位移修正.物理碰撞检测.这些特性不是UE4才加入,早期UE版本就有了. https://answers.unrealen ...
- 【架构师之路】集群/分布式环境下5种session处理策略
[架构师之路]集群/分布式环境下5种session处理策略 转自:http://www.cnblogs.com/jhli/p/6557929.html 在搭建完集群环境后,不得不考虑的一个问题就是 ...
- 第一章 :zabbix监控
1.1 为什么要监控 在需要的时刻,提前提醒我们服务器出问题了 当出问题之后,可以找到问题的根源 网站/服务器 的可用性 1.1.1 网站可用性 在软件系统的高可靠性(也称为可用性,英文描述为HA ...
- Jensen不等式
- FileMaker Server连接SQL Server测试
用FM测试了一把扫二维码.效果还不错,简单的设置几下就可以上线,使用Iphone扫二维码进行盘点以及更新照片功能.接下来测试下下ODBC连接. FMS连接SQL Server测试 1. 在FMS服务器 ...
- MyBatis配置Mapping,JavaType和JDBCType的对应关系,#与$区别
Mybatis中javaType和jdbcType对应关系:JDBC Type Java TypeCHAR StringVARCHAR StringLONGVARCHAR StringNUMERIC ...
- crm 2016 tabstatechange event
1 tabstatechange事件在窗体中定义 2 问题是如果选项卡默认为折叠的.且选项卡中包含了iFrame网页. 3 在网页内容加载完成之后,点击选项卡 折叠/展开 按钮, iFrame网页没有 ...