[python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
这是参照《机器学习实战》中第15章“大数据与MapReduce”的内容,因为作者写作时hadoop版本和现在的版本相差很大,所以在Hadoop上运行python写的MapReduce程序时出现了很多问题,因此希望能够分享一些过程中的经验,但愿大家能够避开同样的坑。文章内容分为以下几个部分:(本文的代码和用到的数据集可以在这里下载)
1.代码分析
2.运行步骤
3.问题解决
1.代码分析
问题描述:在一个海量数据上分布式计算均值和方差的MapReduce作业。
设有一组数字,这组数字的均值和方差如下:
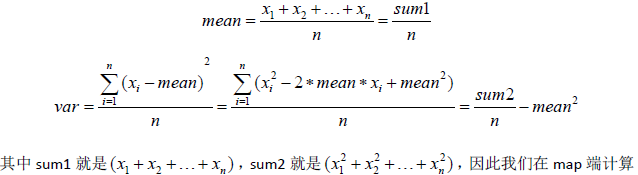
每个部分的{count(元素个数)、sum1/count、sum2/count},然后在reduce端将所有map端传入的sum1加起来在除以总个数n得到均值mean;将所有的sum2加起来除以n再减去均值mean的平方,就得到了方差var.
数据格式如下:一行包含一个数字,保存在inputFile.txt中

Map端的代码如下:(保存在Mapper.py文件中)
#!/usr/bin/env python
#coding=utf-8
import sys
from numpy import mat, mean, power def read_input(file):
for line in file:
yield line.rstrip()#rstrip()去除字符串右边的空格 input = read_input(sys.stdin)#依次读取每行的数据
input = [float(line) for line in input] #将每行转换成float型
numInputs = len(input)
input = mat(input)
sqInput = power(input,2) #输出数据个数,均值,以及平方和的均值,以'\t'隔开
print "%d\t%f\t%f" % (numInputs, mean(input), mean(sqInput))
这里补充说明一下,在read_input()函数中,为何要使用yield?这里使用的是海量数据集,如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过 yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取。
下面是Reduce端的代码(保存在Reducer.py文件中),它接收map端的输出,并将数据合并成全局的均值,并计算得到方差。
#!/usr/bin/env python
#coding=utf-8 import sys
from numpy import mat, mean, power def read_input(file):
for line in file:
yield line.rstrip() input = read_input(sys.stdin) #读取map端的输出,共有三个字段,按照'\t'分隔开来
mapperOut = [line.split('\t') for line in input] cumVal=0.0
cumSumSq=0.0
cumN=0.0
for instance in mapperOut:
nj = float(instance[0])#第一个字段是数据个数
cumN += nj
cumVal += nj*float(instance[1])#第二个字段是一个map输出的均值,均值乘以数据个数就是数据总和
cumSumSq += nj*float(instance[2])#第三个字段是一个map输出的平方和的均值,乘以元素个数就是所有元素的平方和 mean = cumVal/cumN#得到所有元素的均值
var = (cumSumSq/cumN-mean*mean)#得到所有元素的方差 print "%d\t%f\t%f" % (cumN, mean, var)
2.运行步骤
我使用的环境是:
|
Centos 64 Python 2.6 Hadoop 2.2.0 |
2.1 本地运行
在运行之前,首先在本地运行一下,看是否能通过。
首先将以上Mapper.py和Reducer.py文件,以及数据文件inputFile.txt放在同一个文件夹中(我这里是桌面的文件夹:/home/hadoop/Desktop/python_doc中),然后输入命令:chmod +x文件名,修改其权限变成可执行文件。
然后输入以下命令:
[hadoop@hadoop1 python_doc]$ python Mapper.py < inputFile.txt | python Reducer.py

出现上述结果表示运行通过。
2.2 hadoop上运行
1.启动HDFS,进入HADOOP_HOME目录(也就是hadoop的安装目录,我的是/app/hadoop/hadoop):
[hadoop@hadoop1 python_doc]$cd $HADOOP_HOME/sbin
[hadoop@hadoop1 sbin]$./start-dfs.sh
2.验证HDFS是否启动,在MasterNode上输入以下命令,将会出现:NameNode、SecondaryNameNode和DataNode
[hadoop@hadoop1 sbin]$./jps

3.在HDFS下创建一个存放“输入数据“的文件夹
[hadoop@hadoop1 Desktop]$ hadoop fs -mkdir /user/hadoop/mr-input
注意:这里不需要创建“输出数据“的文件夹,否则会出现以下错误:
ERROR security.UserGroupInformation: PriviledgedActionException as:hadoop (auth:SIMPLE) cause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop1:9000/user/hadoop/mr-ouput15 already exists
4.将数据文件inputFile.txt复制到HDFS:
[hadoop@hadoop1 python_doc]$ hadoop fs -put inputFile.txt /user/hadoop/mr-input
也可以查看一下,文件是否复制成功:
[hadoop@hadoop1 python_doc]$ hadoop fs –ls /user/hadoop/mr-input
5.下面重点来了,在命令窗口输入Hadoop Streaming命令:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-*streaming*.jar \
-input /user/hadoop/mr-input/* \
-output /user/hadoop/mr-ouput13 \
-file /home/hadoop/Desktop/python_doc/Mapper.py -mapper 'Mapper.py' \
-file /home/hadoop/Desktop/python_doc/Reducer.py -reducer 'Reducer.py'
注意:在hadoop2.2.0的版本中,streaming.jar的目录发生了改变,保存在:$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar
这里再补充一下,Hadoop Streaming的用法:
Hadoop Streaming用法
Usage: $HADOOP_HOME/bin/hadoop jar \
$HADOOP_HOME/contrib/streaming/hadoop-*streaming*.jar [options]
options:
(1)-input:输入文件路径
(2)-output:输出文件路径
(3)-mapper:用户自己写的mapper程序
(4)-reducer:用户自己写的reducer程序
(5)-file:打包文件到提交的作业中,可以是mapper或者reducer要用的输入文件。
(6)-partitioner:用户自定义的partitioner程序
(7)-combiner:用户自定义的combiner程序(必须用java实现)
(8)-D:作业的一些属性(以前用的是-jonconf),具体有:
1)mapred.map.tasks:map task数目
2)mapred.reduce.tasks:reduce task数目
3)stream.map.input.field.separator/stream.map.output.field.separator: map task输入/输出数据的分隔符,默认均为\t。
4)stream.num.map.output.key.fields:指定map task输出记录中key所占的域数目
5)stream.reduce.input.field.separator/stream.reduce.output.field.separator:reduce task输入/输出数据的分隔符,默认均为\t。
6)stream.num.reduce.output.key.fields:指定reduce task输出记录中key所占的域数目
6. 运行完成后:
查看在输出文件夹下的内容:
[hadoop@hadoop1 Desktop]$ hadoop fs -ls /user/hadoop/mr-ouput13
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2016-03-16 16:45 /user/hadoop/mr-ouput13/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 22 2016-03-16 16:45 /user/hadoop/mr-ouput13/part-00000
查看结果,结果是输出文件夹中的part-00000文件(显示计算结果与本地计算结果是一致的)
[hadoop@hadoop1 Desktop]$ hadoop fs -cat /user/hadoop/mr-ouput13/part-00000
3.问题解决
1. 出现“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1”的错误
解决方法:
- 确保Mapper.py Reducer.py这两个文件的权限是可执行的,如果不是可执行的,使用:chmod +x 文件名,修改其权限为可执行的。
- 确保安装numpy包,Centos下的安装方法是:
sudo yum -y install gcc gcc-c++ numpy python-devel scipy
这个命令会自动把依赖的包都装好。安装完成后,测试一下:
[hadoop@hadoop1 python_doc]$ python
Python 2.6.6 (r266:84292, Jul 23 2015, 15:22:56)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-11)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> from numpy import mat没有提示错误,说明numpy包已安装好。
在hadoop上实施MapReduce之前,一定要在本地运行一下你的python程序,看是否能够跑通。
首先进入包含map和reduce两个py脚本文件和数据文件inputFile.txt的文件夹中。然后输入一下命令,看是否执行通过:
[hadoop@hadoop1 python_doc]$ python Mapper.py < inputFile.txt | python Reducer.py
2.出现错误:“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 2”,或者出现jar文件找不到的情况,或者出现输出文件夹已经存在的情况。
- Mapper.py和Reduce.py的最前面要加上:#!/usr/bin/env python 这条语句
- 在Hadoop Streaming命令中,请确保按以下的格式来输入
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-*streaming*.jar \
-input /user/hadoop/mr-input/* \
-output /user/hadoop/mr-ouput13 \
-file /home/hadoop/Desktop/python_doc/Mapper.py -mapper 'Mapper.py' \
-file /home/hadoop/Desktop/python_doc/Reducer.py -reducer 'Reducer.py'- 要确保jar文件的路径正确,hadoop 2.2版本的该文件是保存在:$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar中,不同的hadoop版本可能略有不同;
- 保存数据文件的HDFS文件夹后要加上”/*”,我这里是“/user/hadoop/mr-input”目录,加上”/*”之后表示该文件夹下所有的文件作为输入的数据文件;
- HDFS中的输出文件夹(这里是HDFS下的/user/hadoop/mr-ouput13),一定要是一个新的(之前不存在)的文件夹,因为即使上条Hadoop Streaming命令没有执行成功,仍然会根据你的命令来创建输出文件夹,而后面再输入Hadoop Streaming命令如果使用相同的输出文件夹时,就会出现“输出文件夹已经存在的错误”;
- 参数 –file后面是map和reduce的脚本,路径是详细的绝对路径(我这里是/home/hadoop/Desktop/python_doc/Mapper.py),但是在参数 -mapper 和-reducer之后,文件名只需要python脚本的名字即可,而且用引号引起来(比如我这里是:-mapper 'Mapper.py')
Reference:
- Peter Harrington,《机器学习实战》,人民邮电出版社,2013
- http://stackoverflow.com/questions/4460522/hadoop-streaming-job-failed-error-in-python (Stackoverflow上关于Hadoop Streaming命令失败的解答)
- http://dongxicheng.org/mapreduce/hadoop-streaming-programming/ (Hadoop Streaming 的参数介绍)
[python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差的更多相关文章
- 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行
[TOC] 简单的java Hadoop MapReduce程序(计算平均成绩)从打包到提交及运行 程序源码 import java.io.IOException; import java.util. ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- 用Python语言写Hadoop MapReduce程序Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simple MapReduce program for Hadoop in the Python pr ...
- HDFS基本命令与Hadoop MapReduce程序的执行
一.HDFS基本命令 1.创建目录:-mkdir [jun@master ~]$ hadoop fs -mkdir /test [jun@master ~]$ hadoop fs -mkdir /te ...
- Caffe学习系列(15):计算图片数据的均值
图片减去均值后,再进行训练和测试,会提高速度和精度.因此,一般在各种模型中都会有这个操作. 那么这个均值怎么来的呢,实际上就是计算所有训练样本的平均值,计算出来后,保存为一个均值文件,在以后的测试中, ...
- Python实现Hadoop MapReduce程序
1.概述 Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,从而充分利用Had ...
- Intellij idea开发Hadoop MapReduce程序
1.首先下载一个Hadoop包,仅Hadoop即可. http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0 ...
- Hadoop MapReduce程序中解决第三方jar包问题方案
hadoop怎样提交多个第三方jar包? 方案1:把所有的第三方jar和自己的class打成一个大的jar包,这种方案显然笨拙,而且更新升级比较繁琐. 方案2: 在你的project里面建立一个lib ...
- 漫画揭秘Hadoop MapReduce | 轻松理解大数据
网址:http://www.iqiyi.com/w_19rtz04nh9.html
随机推荐
- 在HTML中为JavaScript传递变量
在html中为JavaScript传递变量是一个关键步骤,然后就可以通过对JavaScript变量操作,实现想要达到的目的 本节代码主要使用了JavaScript中的document对象中的getEl ...
- 网易云易盾朱星星:最容易被驳回的10大APP过检项
本文由 网易云发布. 1月20日,“走进网易:移动测试与安全实践”公开活动在杭州西湖区颐高创业大厦4F楼友会创业咖啡厅举行.本次活动的议题聚焦在如何实现应用的高效开发.安全过检.开发功耗降到最低等热 ...
- 为什么HashMap不是线程安全的
电面突然被问到这个问题,之前看到过,但是印象不深,导致自己没有答出来,现在总结一下. HashMap的内部存储结构 transient Node<K,V>[] table; static ...
- linux 远程连接报错 10038或者10061 或者10060
1.检查linux的mysql是否开启 2.检查mysql的user表的host是否是% 3.检查my.cnf文件是否绑定本地 4.防火墙3306端口是否开启 假如以上都没问题,那最大的原因就是我折腾 ...
- wifi
当自己流量不够用时,总想用点免费的wifi 但大部分的wifi都是需要密码的,所以,搜到一款软件,wifi万能钥匙,它的好处就是可以破解一些密码比较简单的wifi,相反,有利也有弊,因为大部分连接的还 ...
- Windows 使用 StarWind 创建的 Oracle RAC环境 异常关机之后的处理过程
创建好了 虚拟机之后发现 偶尔会出现 蓝屏重启的现象, 这个时候 需要进行 异常处理 确定虚拟机已经开机之后 1. 打开iscsi的连接设备, 确认 iscsi的正常连接到虚拟机的 存储设备 注意 r ...
- [财务知识]IFRS9
浅谈IFRS9 2018-07-10 23:15信用/收益 原创申明 本文原创作者为金融监管研究院助理研究员李健,未经授权谢绝转载.引用.抄袭. 引言 2018年6月6日,财政部会计司发布了“关于就& ...
- laravel(一)
laravel文档:https://d.laravel-china.org/docs/5.5/ 一.composer安装laravel 在文档中找的create-project命令,最后加上项目名称, ...
- MySQL 5.7 GA 新特性
转载自: http://www.chinaxing.org/articles/Database/2015/10/23/2015-10-22-mysql-5.7.html sys-schema http ...
- 【ARC076D/F】Exhausted?
Description 题目链接 Solution 场上尝试使用优化建图网络流实现,结果T到怀疑人生. 鉴于这是个匹配问题,考虑用贪心做一下. 先退一步,想一下如果每一个人只有\([1 ...