ubantu18.04下Hadoop安装与伪分布式配置
1 下载
下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/stable2/
2 解压
将文件解压到 /usr/local/hadoop
cd ~/下载 tar -zxf hadoop-2.9..tar.gz sudo mv ./hadoop-2.9./ /usr/local/hadoop cd /usr/local/hadoop
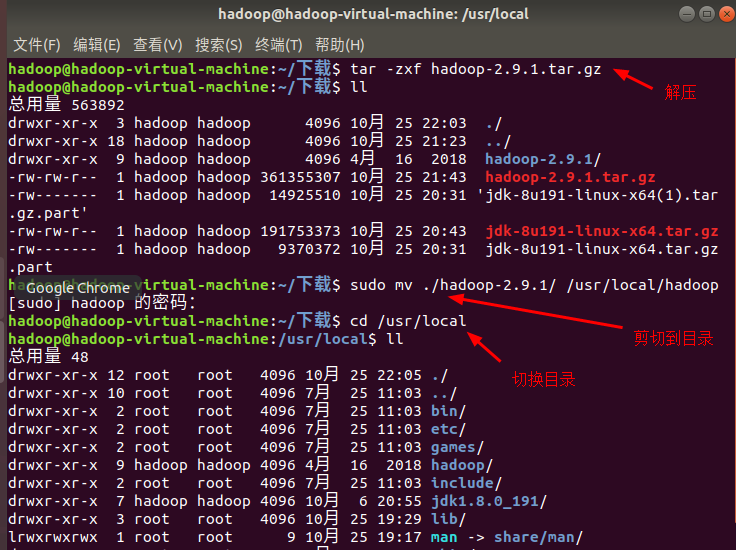
此时可以查看Hadoop版本信息:
./bin/hadoop version

3 hadoop伪分布式配置
3.1 配置hadoop中的JAVA_HOME
到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“ export JAVA_HOME=/usr/local/jdk1.8.0_191”,然后,再次启动Hadoop。

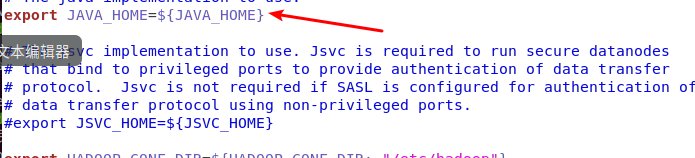
修改后:

令文件生效:

3.2 ssh登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa # 会有提示,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加入授权
3.3 配置HADOOP_HOME
在 ~/.bashrc 中,增加如下内容(设置过程与 JAVA_HOME 变量一样,其中 HADOOP_HOME 为 Hadoop 的安装目录)
#hadoop
export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME$/bin export PATH=$PATH:$HADOOP_HOME$/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
修改后如下图所示:

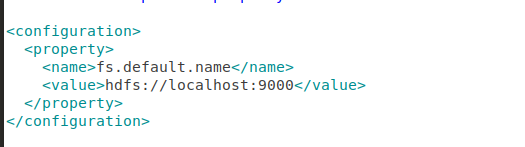
修改/usr/local/hadoop/etc/hadoop/core-site.xml文件配置:
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
修改为一下内容:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改YARN-site.xml文件配置:
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
修改为以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

复制文件:
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
然后进行编辑:
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
修改为以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置hdfs-site.xml文件:
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
修改为以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
3.4 格式化
配置完成后,执行 NameNode 的格式化,执行以下命令:
创建namenode数据存放目录:
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
创建爱你datanode数据存放目录:
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
将Hadoop目录的所有者更改为chb:
sudo chown chb:chb -R /usr/local/hadoop
格式化:
hadoop namenode -format
运行上述命令之后,出现“successfully formatted.“则证明格式化成功。

启动HDFS:
start-dfs.sh
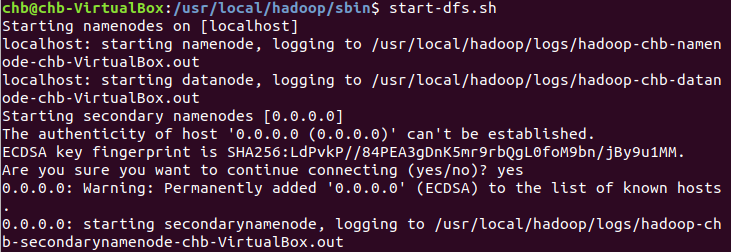
启动Hadoop MapReduce框架的Yarn:

当然,也可以同时启动上述两者:
start-all.sh
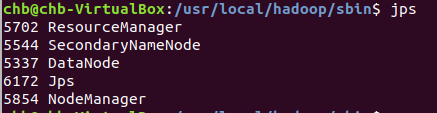
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
jps#可不是jsp
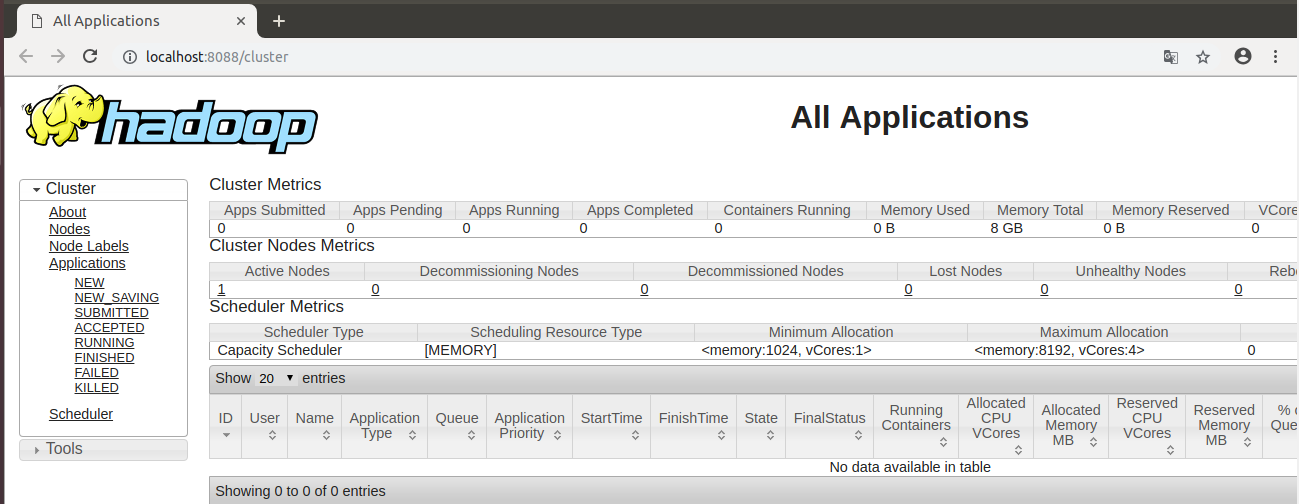
打开浏览器,输入地址:http://localhost:8088/可以看到如下界面:
ubantu18.04下Hadoop安装与伪分布式配置的更多相关文章
- Win10环境下Hadoop(单节点伪分布式)的安装与配置--bug(yarn的8088端口打不开+)
一.本文思路 [1].配置java环境–JDK12(Hadoop的底层实现语言是java,hadoop运行需要JDK环境) [2].安装Hadoop 1.解压hadop 2.配置hadoop环境变量 ...
- Hadoop安装-单机-伪分布式简单部署配置
最近在搞大数据项目支持所以有时间写下hadoop随笔吧. 环境介绍: Linux: centos7 jdk:java version "1.8.0_181 hadoop:hadoop-3.2 ...
- CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2) https://hadoop.apache.org/releases.html 准备工作 关闭防火墙 (也可放行) # 停止防火墙 systemctl stop f ...
- Ubuntu14.04或16.04下Hadoop及Spark的开发配置
对于Hadoop和Spark的开发,最常用的还是Eclipse以及Intellij IDEA. 其中,Eclipse是免费开源的,基于Eclipse集成更多框架配置的还有MyEclipse.Intel ...
- Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一.准备 1.1创建hadoop用户 $ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell $ sudo pass ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- 新手推荐:Hadoop安装教程_单机/伪分布式配置_Hadoop-2.7.1/Ubuntu14.04
下述教程本人在最新版的-jre openjdk-7-jdk OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/ ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04(转)
http://www.powerxing.com/install-hadoop/ http://blog.csdn.net/beginner_lee/article/details/6429146 h ...
随机推荐
- jQuery EasyUI API 中文文档 - 消息框(Messager)
http://www.cnblogs.com/Philoo/archive/2011/11/15/jeasyui_api_messager.html Messager 消息框 博客园 风流涕淌 (p ...
- OpenStack 网络服务 Neutron 多网卡(提供者网络)(十八)
OpenStack 网络服务 Neutron 多网卡,分为内部网络.外部网络 使用vmware模拟两张网卡 添加网卡 网卡配置 cd /etc/sysconfig/network-scripts cp ...
- Hadoop生态圈-kafka事务控制以及性能测试
Hadoop生态圈-kafka事务控制以及性能测试 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Kafka 0.8 sever:源代码High level分析
本文主要介绍了Kafka High level的代码架构和主要的类. 这张图是0.8版本的架构 Boker 架构 1 network layer Kafka使用NIO自己实现了网络层的代码, 而不是采 ...
- POJ-3295 Tautology (构造)
https://vjudge.net/problem/POJ-3295 题意 有五种运算符和五个参数,现在给你一个不超过100字符的算式,问最后结果是否恒为1? 分析 首先明确各运算符的意义,K(&a ...
- HDU 5299 圆扫描线 + 树上删边
几何+博弈的简单组合技 给出n个圆,有包含关系,以这个关系做游戏,每次操作可以选择把一个圆及它内部的圆全部删除,不能操作者输. 圆的包含关系显然可以看做是树型结构,所以也就是树上删边的游戏. 而找圆的 ...
- Java SpringMVC框架学习(三)springMVC的执行流程
具体执行逻辑如下: 浏览器提交请求到中央调度器. 中央调度器将请求转给处理器映射器. 处理器映射器根据请求, 找到请求对应的处理器, 并将其封装为处理器执行链返回给中央调度器. 中央调度器根据处理器执 ...
- CF989C A Mist of Florescence (构造)
CF989C A Mist of Florescence solution: 作为一道构造题,这题确实十分符合构造的一些通性----(我们需要找到一些规律,然后无脑循环).个人认为这题规律很巧妙也很典 ...
- 转:Citrix虚拟化--转自CSDN
http://blog.csdn.net/kkfloat/article/category/1430751/3
- 八、mini2440裸机程序之UART(1)简单介绍【转】
转自:http://blog.csdn.net/shengnan_wu/article/details/8298869 一.概述 S3C2440通用异步接收和发送(UART)提供了三 ...