主动学习——active learning
1. 写在前面
在机器学习(Machine learning)领域,监督学习(Supervised learning)、非监督学习(Unsupervised learning)以及半监督学习(Semi-supervised learning)是三类研究比较多,应用比较广的学习技术,wiki上对这三种学习的简单描述如下:
- 监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。
- 非监督学习:直接对输入数据集进行建模,例如聚类。
- 半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
其实很多机器学习都是在解决类别归属的问题,即给定一些数据,判断每条数据属于哪些类,或者和其他哪些数据属于同一类等等。这样,如果我们上来就对这一堆数据进行某种划分(聚类),通过数据内在的一些属性和联系,将数据自动整理为某几类,这就属于非监督学习。如果我们一开始就知道了这些数据包含的类别,并且有一部分数据(训练数据)已经标上了类标,我们通过对这些已经标好类标的数据进行归纳总结,得出一个 “数据-->类别” 的映射函数,来对剩余的数据进行分类,这就属于监督学习。而半监督学习指的是在训练数据十分稀少的情况下,通过利用一些没有类标的数据,提高学习准确率的方法。
2. 什么是active learning?
在真实的数据分析场景中,我们可以获取海量的数据,但是这些数据都是未标注数据,很多经典的分类算法并不能直接使用。那肯定会有人说,数据是没有标注的,那我们就标注数据喽!这样的想法很正常也很单纯,但是数据标注的代价是很大的,及时我们只标注几千或者几万训练数据,标注数据的时间和金钱成本也是巨大的。
在介绍active learning的概念之前,首先先谈一下样本信息的问题。
什么是样本信息呢?简单地来讲,样本信息就是说在训练数据集当中每个样本带给模型训练的信息是不同的,即每个样本为模型训练的贡献有大有小,它们之间是有差异的。
因此,为了尽可能地减小训练集及标注成本,在机器学习领域中,提出主动学习(active learning)方法,优化分类模型。
主动学习(active learning),指的是这样一种学习方法:
有的时候,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵,这时候,学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给专家进行标注。
这个筛选过程也就是主动学习主要研究的地方了。
3. active learning的基本思想
主动学习算法可以由以下五个组件进行建模:
A=(C,L,S,Q,U)A=(C,L,S,Q,U)
其中 CC 为一个或一组分类器;LL 为一组已标注的训练样本集;QQ 为查询函数,用于在未标注的样本中查询信息量大的样本;UU 为整个未标注样本集;SS 为督导者,可以对未标注样本进行标注。
主动学习算法主要分为两阶段:
第一阶段为初始化阶段,随机从未标注样本中选取小部分,由督导者标注,作为训练集 建立初始分类器模型;
第二阶段为循环查询阶段,SS 从未标注样本集 UU 中,按照某种查询标准 QQ,选取一定的未标注样本进行标注,并加到训练样本集 LL 中, 重新训练分类器,直至达到训练停止标准为止。
主动学习算法是一个迭代的过程,分类器使用 迭代时反馈的样本进行训练,不断提升分类效率。
主动学习的实例:qq空间相册中的人脸识别技术
下图为Action learning在相同的标注样本数目下与监督学习算法的比较:
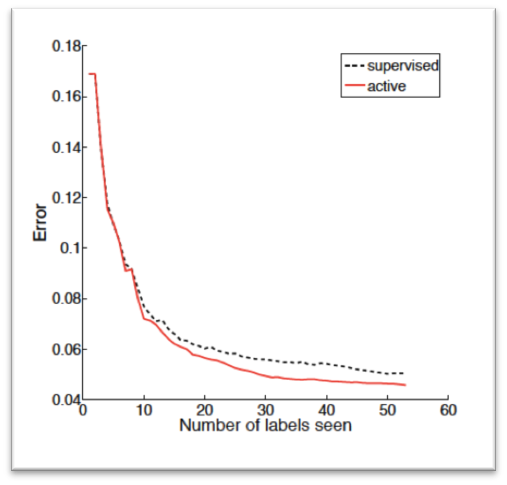
从上图也可以看出来,在相同数目的标注数据中,主动学习算法比监督学习算法的分类误差要低。这里注意横轴是标注数据的数目,对于主动学习而言,相同的标注数据下,主动学习的样本数>监督学习,这个对比主要是为了说明两者对于训练样本的使用效率不同:主动学习训练使用的样本都是经过算法筛选出来对于模型训练有帮助的数据,所以效率高。但是如果是相同样本的数量下去对比两者的误差,那肯定是监督学习占优,这是毋庸置疑的。
4. active learning与半监督学习的不同
很多人认为主动学习也属于半监督学习的范畴了,但实际上是不一样的,半监督学习和直推学习(transductive learning)以及主动学习,都属于利用未标记数据的学习技术,但基本思想还是有区别的。
如上所述,主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。
而半监督学习,特指的是学习算法不需要人工的干预,基于自身对未标记数据加以利用。
5. 参考文献
[2] 2012,主动学习算法综述
主动学习——active learning的更多相关文章
- 主动学习(Active Learning)
主动学习简介 在某些情况下,没有类标签的数据相当丰富而有类标签的数据相当稀少,并且人工对数据进行标记的成本又相当高昂.在这种情况下,我们可以让学习算法主动地提出要对哪些数据进行标注,之后我们要将这些数 ...
- Active Learning主动学习
Active Learning主动学习 我们使用一些传统的监督学习方法做分类的时候,往往是训练样本规模越大,分类的效果就越好.但是在现实生活的很多场景中,标记样本的获取是比较困难的,这需要领域内的专家 ...
- [Machine Learning] Active Learning
1. 写在前面 在机器学习(Machine learning)领域,监督学习(Supervised learning).非监督学习(Unsupervised learning)以及半监督学习(Semi ...
- Active Learning
怎么办?进行Active Learning主动学习 Active Learning是最近又流行起来了的概念,是一种半监督学习方法. 一种典型的例子是:在没有太多数据的情况下,算法通过不断给出在决策边界 ...
- [Active Learning] 01 A Brief Introduction to Active Learning 主动学习简介
目录 什么是主动学习? 主动学习 vs. 被动学习 为什么需要主动学习? 主动学习与监督学习.弱监督学习.半监督学习.无监督学习之间的关系 主动学习的种类 主动学习的一个例子 主动学习工具包 ALiP ...
- 【主动学习】Variational Adversarial Active Learning
本文记录了博主阅读ICCV2019一篇关于主动学习论文的笔记,第一篇博客,以后持续更新哈哈 论文题目:<Variational AdVersarial Active Learning> 原 ...
- 简要介绍Active Learning(主动学习)思想框架,以及从IF(isolation forest)衍生出来的算法:FBIF(Feedback-Guided Anomaly Discovery)
1. 引言 本文所讨论的内容为笔者对外文文献的翻译,并加入了笔者自己的理解和总结,文中涉及到的原始外文论文和相关学习链接我会放在reference里,另外,推荐读者朋友购买 Stephen Boyd的 ...
- Active Learning 主动学习
Active Learning 主动学习 2015年09月30日 14:49:29 qrlhl 阅读数 21374 文章标签: 算法机器学习 更多 分类专栏: 机器学习 版权声明:本文为博主原创文 ...
- Recorder︱深度学习小数据集表现、优化(Active Learning)、标注集网络获取
一.深度学习在小数据集的表现 深度学习在小数据集情况下获得好效果,可以从两个角度去解决: 1.降低偏差,图像平移等操作 2.降低方差,dropout.随机梯度下降 先来看看深度学习在小数据集上表现的具 ...
随机推荐
- 【Vijos1404】遭遇战(最短路)
[Vijos1404]遭遇战(最短路) 题面 Vijos 题解 显然可以树状数组之类的东西维护一下\(dp\).这里考虑一种最短路的做法. 首先对于一个区间\([l,r]\),显然可以连边\((l,r ...
- POJ 2251 Dungeon Master /UVA 532 Dungeon Master / ZOJ 1940 Dungeon Master(广度优先搜索)
POJ 2251 Dungeon Master /UVA 532 Dungeon Master / ZOJ 1940 Dungeon Master(广度优先搜索) Description You ar ...
- LeetCode 6罗马数字转整数
罗马数字包含以下七种字符:I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两个并列 ...
- 借读:分布式锁和双写Redis
本帖最后由 howtodown 于 2016-10-3 16:01 编辑问题导读1.为什么会产生分布式锁?2.使用分布式锁的方法有哪些?3.本文创造的分布式锁的双写Redis框架都包含哪些内容? ...
- python---django中模板布局
对于页面大部分一样,我们可以使用模板布局来简化 可以查看tornado中的模板引擎,基本一致 python---tornado模板引擎 对于相同代码部分,我们可以提取出来,放在布局文件layout.p ...
- SQL语句(六)成批导入导出数据
(六) 成批导入导出数据 假设已经存在teaching数据库, 存在一张Student表,如图: 右键teaching->任务->导入数据 下一步->数据源(Microsoft Ex ...
- 那些年的 网络通信之 UDP 数据报包传输---
下面是 一个多线程,基于 UDP 用户数据报包 协议 的 控制台聊天小程序 import java.io.*; import java.net.*; class Send implements Run ...
- Spring: 读取 .properties 文件地址,json转java对象,el使用java类方法相关 (十三)
1. 在Java中获取 .properties 文件的路径 (src/main/resources 下) ProjectName |---src/main/java |---src/main/reso ...
- python的__get__、__set__、__delete__(1)
内容: 描述符引导 摘要 定义和介绍 描述符协议 调用描述符 样例 Properties 函数和 ...
- python中的*号
from:https://www.douban.com/note/231603832/ 传递实参和定义形参(所谓实参就是调用函数时传入的参数,形参则是定义函数是定义的参数)的时候,你还可以使用两个特殊 ...