pig简介
Apache Pig是MapReduce的一个抽象。它是一个工具/平台,用于分析较大的数据集,并将它们表示为数据流。Pig通常与 Hadoop 一起使用;我们可以使用Apache Pig在Hadoop中执行所有的数据处理操作。
要使用 Apache Pig 分析数据,程序员需要使用Pig Latin语言编写脚本。所有这些脚本都在内部转换为Map和Reduce任务。Apache Pig有一个名为 Pig Engine 的组件,它接受Pig Latin脚本作为输入,并将这些脚本转换为MapReduce作业。
为什么要使用Apache Pig
使用 Pig Latin ,程序员可以轻松地执行MapReduce作业,而无需在Java中键入复杂的代码。
Apache Pig使用多查询方法,从而减少代码长度。例如,需要在Java中输入200行代码(LoC)的操作在Apache Pig中输入少到10个LoC就能轻松完成。最终,Apache Pig将开发时间减少了近16倍。
Pig Latin是类似SQL的语言,当你熟悉SQL后,很容易学习Apache Pig。
Apache Pig提供了许多内置操作符来支持数据操作,如join,filter,ordering等。此外,它还提供嵌套数据类型,例如tuple(元组),bag(包)和MapReduce缺少的map(映射)。
Apache Pig具有以下特点:
丰富的运算符集 - 它提供了许多运算符来执行诸如join,sort,filer等操作。
易于编程 - Pig Latin与SQL类似,如果你善于使用SQL,则很容易编写Pig脚本。
优化机会 - Apache Pig中的任务自动优化其执行,因此程序员只需要关注语言的语义。
可扩展性 - 使用现有的操作符,用户可以开发自己的功能来读取、处理和写入数据。
用户定义函数 - Pig提供了在其他编程语言(如Java)中创建用户定义函数的功能,并且可以调用或嵌入到Pig脚本中。
处理各种数据 - Apache Pig分析各种数据,无论是结构化还是非结构化,它将结果存储在HDFS中。
Apache Pig与MapReduce
下面列出的是Apache Pig和MapReduce之间的主要区别。
| Apache Pig | MapReduce |
|---|---|
| Apache Pig是一种数据流语言。 | MapReduce是一种数据处理模式。 |
|
它是一种高级语言。 |
MapReduce是低级和刚性的。 |
| 在Apache Pig中执行Join操作非常简单。 | 在MapReduce中执行数据集之间的Join操作是非常困难的。 |
| 任何具备SQL基础知识的新手程序员都可以方便地使用Apache Pig工作。 | 向Java公开是必须使用MapReduce。 |
| Apache Pig使用多查询方法,从而在很大程度上减少代码的长度。 | MapReduce将需要几乎20倍的行数来执行相同的任务。 |
| 没有必要编译。执行时,每个Apache Pig操作符都在内部转换为MapReduce作业。 | MapReduce作业具有很长的编译过程。 |
Apache Pig Vs SQL
下面列出了Apache Pig和SQL之间的主要区别。
| Pig | SQL |
| Pig Latin是一种程序语言。 | SQL是一种声明式语言。 |
| 在Apache Pig中,模式是可选的。我们可以存储数据而无需设计模式(值存储为$ 01,$ 02等) | 模式在SQL中是必需的。 |
| Apache Pig中的数据模型是嵌套关系。 | SQL 中使用的数据模型是平面关系。 |
| Apache Pig为查询优化提供有限的机会。 | 在SQL中有更多的机会进行查询优化。 |
除了上面的区别,Apache Pig Latin:
- 允许在pipeline(流水线)中拆分。
- 允许开发人员在pipeline中的任何位置存储数据。
- 声明执行计划。
- 提供运算符来执行ETL(Extract提取,Transform转换和Load加载)功能。
Apache Pig VS Hive
Apache Pig和Hive都用于创建MapReduce作业。在某些情况下,Hive以与Apache Pig类似的方式在HDFS上运行。在下表中,我们列出了几个重要的点区分Apache Pig与Hive。
| Apache Pig | Hive |
|---|---|
| Apache Pig使用一种名为 Pig Latin 的语言(最初创建于 Yahoo )。 | Hive使用一种名为 HiveQL 的语言(最初创建于Facebook )。 |
| Pig Latin是一种数据流语言。 | HiveQL是一种查询处理语言。 |
| Pig Latin是一个过程语言,它适合流水线范式。 | HiveQL是一种声明性语言。 |
| Apache Pig可以处理结构化,非结构化和半结构化数据。 | Hive主要用于结构化数据。 |
Apache Pig的应用程序
Apache Pig通常被数据科学家用于执行涉及特定处理和快速原型设计的任务。使用Apache Pig:
- 处理巨大的数据源,如Web日志。
- 为搜索平台执行数据处理。
- 处理时间敏感数据的加载
用于使用Pig分析Hadoop中的数据的语言称为 Pig Latin ,是一种高级数据处理语言,它提供了一组丰富的数据类型和操作符来对数据执行各种操作。
要执行特定任务时,程序员使用Pig,需要用Pig Latin语言编写Pig脚本,并使用任何执行机制(Grunt Shell,UDFs,Embedded)执行它们。执行后,这些脚本将通过应用Pig框架的一系列转换来生成所需的输出。
Apache Pig的架构
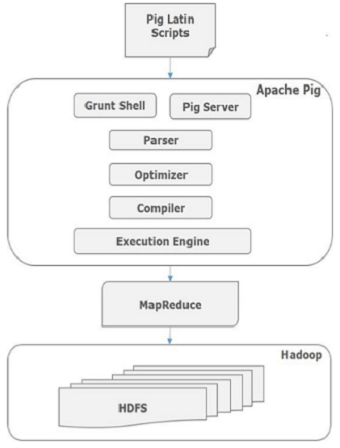
Apache Pig组件
如图所示,Apache Pig框架中有各种组件。让我们来看看主要的组件。
Parser(解析器)
最初,Pig脚本由解析器处理,它检查脚本的语法,类型检查和其他杂项检查。解析器的输出将是DAG(有向无环图),它表示Pig Latin语句和逻辑运算符。在DAG中,脚本的逻辑运算符表示为节点,数据流表示为边。
Optimizer(优化器)
逻辑计划(DAG)传递到逻辑优化器,逻辑优化器执行逻辑优化,例如投影和下推。
Compiler(编译器)
编译器将优化的逻辑计划编译为一系列MapReduce作业。
Execution engine(执行引擎)
最后,MapReduce作业以排序顺序提交到Hadoop。这些MapReduce作业在Hadoop上执行,产生所需的结果。
Pig Latin数据模型
Pig Latin的数据模型是完全嵌套的,它允许复杂的非原子数据类型,例如 map 和 tuple 。
Atom(原子)
Pig Latin中的任何单个值,无论其数据类型,都称为 Atom 。它存储为字符串,可以用作字符串和数字。int,long,float,double,chararray和bytearray是Pig的原子值。一条数据或一个简单的原子值被称为字段。例:“raja“或“30"
Tuple(元组)
由有序字段集合形成的记录称为元组,字段可以是任何类型。元组与RDBMS表中的行类似。例:(Raja,30)
Bag(包)
一个包是一组无序的元组。换句话说,元组(非唯一)的集合被称为包。每个元组可以有任意数量的字段(灵活模式)。包由“{}"表示。它类似于RDBMS中的表,但是与RDBMS中的表不同,不需要每个元组包含相同数量的字段,或者相同位置(列)中的字段具有相同类型。
例:{(Raja,30),(Mohammad,45)}
包可以是关系中的字段;在这种情况下,它被称为内包(inner bag)。
例:{Raja,30, {9848022338,raja@gmail.com,} }
Map(映射)
映射(或数据映射)是一组key-value对。key需要是chararray类型,且应该是唯一的。value可以是任何类型,它由“[]"表示,
例:[name#Raja,age#30]
Relation(关系)
一个关系是一个元组的包。Pig Latin中的关系是无序的(不能保证按任何特定顺序处理元组)。
源自:https://www.w3cschool.cn/apache_pig
pig简介的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pig简介
实验目的 了解pig的该概念和原理 了解pig的思想和用途 了解pig与hadoop的关系 实验原理 1.Pig 相比Java的MapReduce API,Pig为大型数据集的处理提供了更高层次的抽象 ...
- Hadoop Pig简介、安装、试用
相比Java的MapReduce api,Pig为大型数据集的处理提供了更高层次的抽象,与MapReduce相比,Pig提供了更丰富的数据结构,一般都是多值和嵌套的数据结构.Pig还提供了一套更强大的 ...
- Hadoop学习笔记—16.Pig框架学习
一.关于Pig:别以为猪不能干活 1.1 Pig的简介 Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换 ...
- Pig实战
1. pig简介 2. 安装pig 3. 实战pig 4. 深入pig 5. 参考资料及代码下载 <1>. Pig简介 pig是hadoop项目的一个拓展项目, 用以简化hadoop编程 ...
- hadoop pig入门总结
在这里贴一个pig源码的分析,做pig很长时间没做笔记,不包含任何细节,以后有机会再说吧 http://blackproof.iteye.com/blog/1769219 hadoop pig入门总结 ...
- 大数据笔记(十七)——Pig的安装及环境配置、数据模型
一.Pig简介和Pig的安装配置 1.最早是由Yahoo开发,后来给了Apache 2.支持语言:PigLatin 类似SQL 3.翻译器 PigLatin ---> MapReduce(Spa ...
- Hadoop以及其外围生态系统的安装参考
在研究Hadoop的过程中使用到的参考文档: 1.Hadoop2.2 参考文档 在CentOS上安装Hadoop 2.x 集群: http://cn.soulmachine.me/blog/201 ...
- 思数云hadoop目录
全文检索.数据分析挖掘.推荐系统.广告系统.图像识别.海量存储.快速查询 l Hadoop介绍 n Hadoop来源与历史 n Hadoop版本 n Hadoop开源与商业 l HDFS系统架构 n ...
- Hadoop权威指南(中文版-带目录索引)pdf电子书
Hadoop权威指南(中文版-带目录索引)pdf电子书下载地址:百度网盘点击下载:链接:https://pan.baidu.com/s/1E-8eLaaqTCkKESNPDqq0jw 提取码:g6 ...
随机推荐
- ie8 报错:意外地调用了方法或属性访问
在某场景中一句简单的js: $("#changeOption").text("增加"); 在 IE8 下面报错:'意外地调用了方法或属性访问' 改成:$(&qu ...
- git 查看提交的信息diff
git log --stat git show <hashcode> <filename> git log --pretty=oneline <filename> ...
- Selenium2+python自动化38-显式等待(WebDriverWait)
From: https://www.cnblogs.com/yoyoketang/p/6517477.html 前言: 在脚本中加入太多的sleep后会影响脚本的执行速度,虽然implicitly_w ...
- Centos7 安装sz,rz命令
yum install lrzsz 我记得以前某个我敬佩的人说过压缩分很多种,有空,补充这篇笔记.加油~
- [蓝桥杯]ALGO-79.算法训练_删除数组零元素
从键盘读入n个整数放入数组中,编写函数CompactIntegers,删除数组中所有值为0的元素,其后元素向数组首端移动.注意,CompactIntegers函数需要接受数组及其元素个数作为参数,函数 ...
- Lzma(7-zip)和zlib
Lzma(7-zip) 使用: 在C目录中有算法文件,进入Util\LzmaLib目录,编译生成LIB库,导出了以下两函数,LzmaCompress 为压缩函数,LzmaUncompress 为解压缩 ...
- django获取表单数据
django获取单表数据的三种方式 v1 = models.Business.objects.all() # v1是QuerySet的列表 ,内部元素都是对象 v2 = models.Business ...
- appium工具 录制的方法
参考: https://www.jianshu.com/p/5eef1bfa42ae
- RPM包安装软件 -- 详细解读
一.RPM包命名规则 1.RPM包在哪 RPM包在光盘中 2.RPM包命名原则 httpd-2.2.15-15.e16.centos.1.i686.rpm httpd 软件包名 2.2.15 软件版本 ...
- 后台对象转化成json数据返回给前端
一.介绍 JSON-lib包是一个beans,collections,maps,java arrays 和XML和JSON互相转换的包,主要就是用来解析Json数据 二.下载jar依赖包:可以去这里下 ...