python爬虫:一些常用的爬虫技巧
python爬虫:一些常用的爬虫技巧
1、基本抓取网页
get方法:
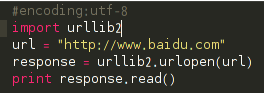
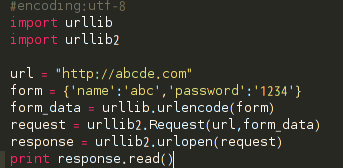
post方法:
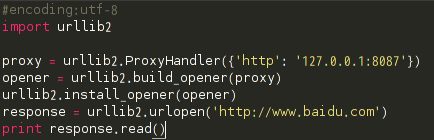
2、使用代理IP
在开发爬虫过程中经常会遇到IP被封掉的情况,这时就需要用到代理IP;
在urllib2包中有ProxyHandler类,通过此类可以设置代理访问网页,如下代码片段:
3、Cookies处理
cookies是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密),python提供了 cookielib模块用于处理cookies,cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用 来访问Internet资源.
代码片段:
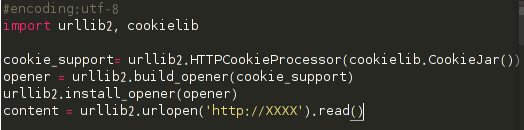
关键在于CookieJar(),它用于管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对 CookieJar实例进行垃圾回收后cookie也将丢失,所有过程都不需要单独去操作。手动添加cookie

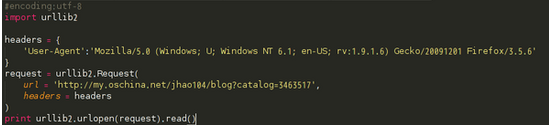
4、伪装成浏览器
某些网站反感爬虫的到访,于是对爬虫一律拒绝请求。所以用urllib2直接访问网站经常会出现HTTP Error 403: Forbidden的情况
对有些 header 要特别留意,Server 端会针对这些 header 做检查
1.User-Agent 有些 Server 或 Proxy 会检查该值,用来判断是否是浏览器发起的 Request
2.Content-Type 在使用 REST 接口时,Server 会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
这时可以通过修改http包中的header来实现,代码片段如下:
5、页面解析
对于页面解析最强大的当然是正则表达式,这个对于不同网站不同的使用者都不一样,就不用过多的说明,附两个比较好的网址:
正则表达式入门: Python正则表达式指南
正则表达式在线测试: 在线正则表达式测试
其次就是解析库了,常用的有两个lxml和BeautifulSoup,对于这两个的使用介绍两个比较好的网站:
lxml: http:// my.oschina.net/jhao104/ blog/639448
BeautifulSoup: Python爬虫利器二之Beautiful Soup的用法
对于这两个库,我的评价是,都是HTML/XML的处理库,Beautifulsoup纯python实现,效率低,但是功能实用,比如能用通过结果搜索获得某个HTML节点的源码;lxmlC语言编码,高效,支持Xpath
6、gzip压缩
有没有遇到过某些网页,不论怎么转码都是一团乱码。哈哈,那说明你还不知道许多web服务具有发送压缩数据的能力,这可以将网络线路上传输的大量数据消减 60% 以上。这尤其适用于 XML web 服务,因为 XML 数据 的压缩率可以很高。
但是一般服务器不会为你发送压缩数据,除非你告诉服务器你可以处理压缩数据。
于是需要这样修改代码:
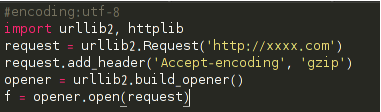
这是关键:创建Request对象,添加一个 Accept-encoding 头信息告诉服务器你能接受 gzip 压缩数据
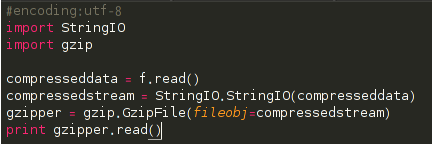
然后就是解压缩数据:
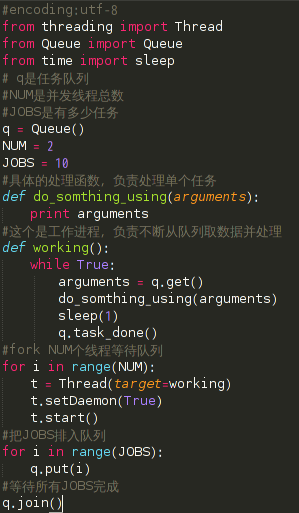
7、多线程并发抓取
单线程太慢的话,就需要多线程了,这里给个简单的线程池模板 这个程序只是简单地打印了1-10,但是可以看出是并发的。
虽然说python的多线程很鸡肋,但是对于爬虫这种网络频繁型,还是能一定程度提高效率的。
python爬虫:一些常用的爬虫技巧的更多相关文章
- python爬虫抓站的一些技巧总结
使用python爬虫抓站的一些技巧总结:进阶篇 一.gzip/deflate支持现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,以VeryCD的主页为例,未压缩版本247K,压缩了以后45 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- 转载:用python爬虫抓站的一些技巧总结
原文链接:http://www.pythonclub.org/python-network-application/observer-spider 原文的名称虽然用了<用python爬虫抓站的一 ...
- 用python爬虫抓站的一些技巧总结 zz
用python爬虫抓站的一些技巧总结 zz 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自动收邮件的脚本, ...
- Python爬虫beautifulsoup4常用的解析方法总结(新手必看)
今天小编就为大家分享一篇关于Python爬虫beautifulsoup4常用的解析方法总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧摘要 如何用beau ...
- python网络爬虫之初始网络爬虫
第一次接触到python是一个很偶然的因素,由于经常在网上看连载小说,很多小说都是上几百的连载.因此想到能不能自己做一个工具自动下载这些小说,然后copy到电脑或者手机上,这样在没有网络或者网络信号不 ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫随笔(2)—启动爬虫与xpath
启动爬虫 在上一节中,我们已经创建好了我们的scrapy项目,看着这一大堆文件,想必很多人都会一脸懵逼,我们应该怎么启动这个爬虫呢? 既然我们采用cmd命令创建了scrapy爬虫,那就得有始有终有逼格 ...
- python网络爬虫之初识网络爬虫
第一次接触到python是一个很偶然的因素,由于经常在网上看连载小说,很多小说都是上几百的连载.因此想到能不能自己做一个工具自动下载这些小说,然后copy到电脑或者手机上,这样在没有网络或者网络信号不 ...
随机推荐
- Java 判断文件夹、文件是否存在、否则创建文件夹
1.判断文件是否存在,不存在创建文件 File file=new File("C:\\Users\\QPING\\Desktop\\JavaScript\\2.htm"); if( ...
- eclipse @override注解出错
在工程中新建了一个接口,定义了一个methodA,然后写一个接口类实现该方法,并加上@override注解 项目提示@override出错,必须覆盖原方法XXX,解决办法 1)项目右键-project ...
- js生成GUID
//表示全局唯一标识符 (GUID). function Guid(g) { var arr = new Array(); //存放32位数值的数组 if (typeof(g) == "st ...
- 01-C#入门(函数一)
只有在动手写代码的时候,才能真正理解到代码的逻辑思想,所以,开始写代码吧. 函数的意义:降低相同功能的代码重复编写,提高重复代码的维护效率. 函数 一个文件由命令空间(namespace).类(cla ...
- IIS6批量添加主机头,修改IIS数据库
首先,找到IIS的数据库.默认是在C:\WINDOWS\system32\inetsrv 下的MetaBase.xml文件. 如果找不到,请右键右键站点->所有服务->将配置保存到一个文件 ...
- iOS8下bundle路径变更
iOS8下路径变为: /Users/username/Library/Developer/CoreSimulator/Devices/786824FF-6D4C-4D73-884A-696514481 ...
- iscroll4 捕捉元素开发手机焦点图滑动效果
html标准代码格式 <div id="wrapper"> <div id="scroller" > <ul id="t ...
- Norflash控制器的Verilog建模之二(仿真)
前言:经过几天修改,norflash控制器基本已经完成,通过仿真.完整的norflash包含2个模块:直接操作硬件的norflash_ctrl.v与控制ctrl模块的驱动norflash_driver ...
- MVC中使用内建的HTML辅助方法产生表单元素提交表单与button按钮事件的陷阱
网站模板页有个登陆的退出按钮,当点击时跳转到登陆页面. <button onclick="logout()" >退出</button> $("#l ...
- vs2015 企业版 专业版 密钥
亲测可用 专业版:HMGNV-WCYXV-X7G9W-YCX63-B98R2企业版:HM6NR-QXX7C-DFW2Y-8B82K-WTYJV