myrocks 之数据字典
data dictionary
rocksdb作为mysql的一个新的存储引擎,在存储引擎层,会维护自已的元数据信息。在innodb存储引擎中,我们通过information_schema下的INNODB_SYS_DATAFILES,INNODB_SYS_TABLES,INNODB_SYS_INDEXES等表,
可以窥视innodb的元数据信息。同样,rocksdb通过information_schema下的ROCKSDB_INDEX_FILE_MAP,ROCKSDB_DDL,ROCKSDB_GLOBAL_INFO等表可以查看原数据信息。
show create table ROCKSDB_INDEX_FILE_MAP\G
************************* 1. row ***********************
Table: ROCKSDB_INDEX_FILE_MAP
Create Table: CREATE TEMPORARY TABLE `ROCKSDB_INDEX_FILE_MAP` (
`COLUMN_FAMILY` int(4) NOT NULL DEFAULT '',
`INDEX_NUMBER` int(4) NOT NULL DEFAULT '',
`SST_NAME` varchar(193) NOT NULL DEFAULT '',
`NUM_ROWS` bigint(8) NOT NULL DEFAULT '',
`DATA_SIZE` bigint(8) NOT NULL DEFAULT '',
`ENTRY_DELETES` bigint(8) NOT NULL DEFAULT '',
`ENTRY_SINGLEDELETES` bigint(8) NOT NULL DEFAULT '',
`ENTRY_MERGES` bigint(8) NOT NULL DEFAULT '',
`ENTRY_OTHERS` bigint(8) NOT NULL DEFAULT ''
) ENGINE=MEMORY DEFAULT CHARSET=utf8 show create table ROCKSDB_DDL\G
*********************** 1. row ***********************
Table: ROCKSDB_DDL
Create Table: CREATE TEMPORARY TABLE `ROCKSDB_DDL` (
`TABLE_SCHEMA` varchar(193) NOT NULL DEFAULT '',
`TABLE_NAME` varchar(193) NOT NULL DEFAULT '',
`PARTITION_NAME` varchar(193) DEFAULT NULL,
`INDEX_NAME` varchar(193) NOT NULL DEFAULT '',
`COLUMN_FAMILY` int(4) NOT NULL DEFAULT '',
`INDEX_NUMBER` int(4) NOT NULL DEFAULT '',
`INDEX_TYPE` smallint(2) NOT NULL DEFAULT '',
`KV_FORMAT_VERSION` smallint(2) NOT NULL DEFAULT '',
`CF` varchar(193) NOT NULL DEFAULT ''
) ENGINE=MEMORY DEFAULT CHARSET=utf8 show create table ROCKSDB_GLOBAL_INFO\G
*********************** 1. row *************************
Table: ROCKSDB_GLOBAL_INFO
Create Table: CREATE TEMPORARY TABLE `ROCKSDB_GLOBAL_INFO` (
`TYPE` varchar(513) NOT NULL DEFAULT '',
`NAME` varchar(513) NOT NULL DEFAULT '',
`VALUE` varchar(513) NOT NULL DEFAULT ''
) ENGINE=MEMORY DEFAULT CHARSET=utf8
元数据详情
下面我们来具体看看rocksdb维护了哪些元数据信息,从源码中看定义了以下类型,这些数据都以KV的形式存储在名叫__system__的系统column family中。
// Data dictionary types
enum DATA_DICT_TYPE {
DDL_ENTRY_INDEX_START_NUMBER= ,
INDEX_INFO= ,
CF_DEFINITION= ,
BINLOG_INFO_INDEX_NUMBER= ,
DDL_DROP_INDEX_ONGOING= ,
INDEX_STATISTICS= ,
MAX_INDEX_ID= ,
DDL_CREATE_INDEX_ONGOING= ,
END_DICT_INDEX_ID=
};
DDL_ENTRY_INDEX_START_NUMBER
表和索引之间的映射关系
key: Rdb_key_def::DDL_ENTRY_INDEX_START_NUMBER(0x1) + dbname.tablename
value: version + {global_index_id}*n_indexes_of_the_tableINDEX_INFO
索引id和索引属性的关系
key: Rdb_key_def::INDEX_INFO(0x2) + global_index_id
value: version, index_type, key_value_format_versionindex_type:主键/二级索引/隐式主键
key_value_format_version: 记录存储格式的版本CF_DEFINITION
column family属性
key: Rdb_key_def::CF_DEFINITION(0x3) + cf_id
value: version, {is_reverse_cf, is_auto_cf}is_reverse_cf: 是否是reverse column family
is_auto_cf: column family名字是否是$per_index_cf,名字自动由table.indexname组成BINLOG_INFO_INDEX_NUMBER
binlog位点及gtid信息,binlog_commit更新此信息
key: Rdb_key_def::BINLOG_INFO_INDEX_NUMBER (0x4)
value: version, {binlog_name,binlog_pos,binlog_gtid}DDL_DROP_INDEX_ONGOING
等待删除的索引信息
key: Rdb_key_def::DDL_DROP_INDEX_ONGOING(0x5) + global_index_id
value: versionINDEX_STATISTICS
索引统计信息
key: Rdb_key_def::INDEX_STATISTICS(0x6) + global_index_id
value: version, {materialized PropertiesCollector::IndexStats}MAX_INDEX_ID
当前的index id,每次创建索引index id都从这个获取和更新
key: Rdb_key_def::CURRENT_MAX_INDEX_ID(0x7)
value: version, current max index idDDL_CREATE_INDEX_ONGOING
等待创建的索引信息
key: Rdb_key_def::DDL_CREATE_INDEX_ONGOING(0x8) + global_index_id
value: version
rocksdb DDL 实现
这里以建表和删表来举例
create table
CREATE TABLE t1 (a INT, b CHAR(), pk INT AUTO_INCREMENT ,PRIMARY KEY(pk), key idx1(b) comment 'cf_1') ENGINE=rocksdb;
通过以下步骤建表
- 创建column family (get_or_create_cf) primary key 存才default column family中,idx1存在cf_1中,需增加一条cf_1的,CF_DEFINITION的记录 {CF_DEFINITION(4)+cf_id(4)} ---> {CF_DEFINITION_VERSION(2)+cf_flags(4)}
- 创建索引 两条索引 {INDEX_INFO(4)+cf_id(0)+index_id(260)---> { INDEX_INFO_VERSION_VERIFY_KV_FORMAT(1)+index_type(1)+kv_version(11) {INDEX_INFO(4)+cf_id(2)+index_id(261)---> { INDEX_INFO_VERSION_VERIFY_KV_FORMAT(2)+index_type(2)+kv_version(11)
- 建立表和索引的映射 {DDL_ENTRY_INDEX_START_NUMBER(4)+dbname(test)+tablename(t1) } --> { DDL_ENTRY_INDEX_VERSION+cf_id(0)+index_id(260)+cf_id(2)+index_id(261}
以上信息通过同一batch一起存入rocksdb中。
另外,建索引时,会更新MAX_INDEX_ID信息,使用单独的batch写入,参考(Rdb_seq_generator::get_and_update_next_number)
select * from INFORMATION_SCHEMA.ROCKSDB_DDL where table_name='t1';
+--------------+------------+----------------+------------+---------------+--------------+------------+-------------------+---------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | INDEX_NAME | COLUMN_FAMILY | INDEX_NUMBER | INDEX_TYPE | KV_FORMAT_VERSION | CF |
+--------------+------------+----------------+------------+---------------+--------------+------------+-------------------+---------+
| test | t1 | NULL | PRIMARY | | | | | default |
| test | t1 | NULL | idx1 | | | | | cf_1 |
+--------------+------------+----------------+------------+---------------+--------------+------------+-------------------+---------+ select d.*,i.* from INFORMATION_SCHEMA.ROCKSDB_INDEX_FILE_MAP i,INFORMATION_SCHEMA.ROCKSDB_DDL d where i.INDEX_NUMBER=d.INDEX_NUMBER;
+--------------+------------+----------------+------------+---------------+--------------+------------+-------------------+---------+---------------+--------------+------------+----------+-----------+---------------+---------------------+--------------+--------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | INDEX_NAME | COLUMN_FAMILY | INDEX_NUMBER | INDEX_TYPE | KV_FORMAT_VERSION | CF | COLUMN_FAMILY | INDEX_NUMBER | SST_NAME | NUM_ROWS | DATA_SIZE | ENTRY_DELETES | ENTRY_SINGLEDELETES | ENTRY_MERGES | ENTRY_OTHERS |
+--------------+------------+----------------+------------+---------------+--------------+------------+-------------------+---------+---------------+--------------+------------+----------+-----------+---------------+---------------------+--------------+--------------+
| test | t1 | NULL | PRIMARY | | | | | default | | | .sst | | | | | | |
| test | t1 | NULL | idx1 | | | | | cf_1 | | | .sst | | | | | | |
+--------------+------------+----------------+------------+---------------+--------------+------------+-------------------+---------+---------------+--------------+------------+----------+-----------+---------------+---------------------+--------------+--------------+
rows in set (0.00 sec)
实际数据分布如下图:
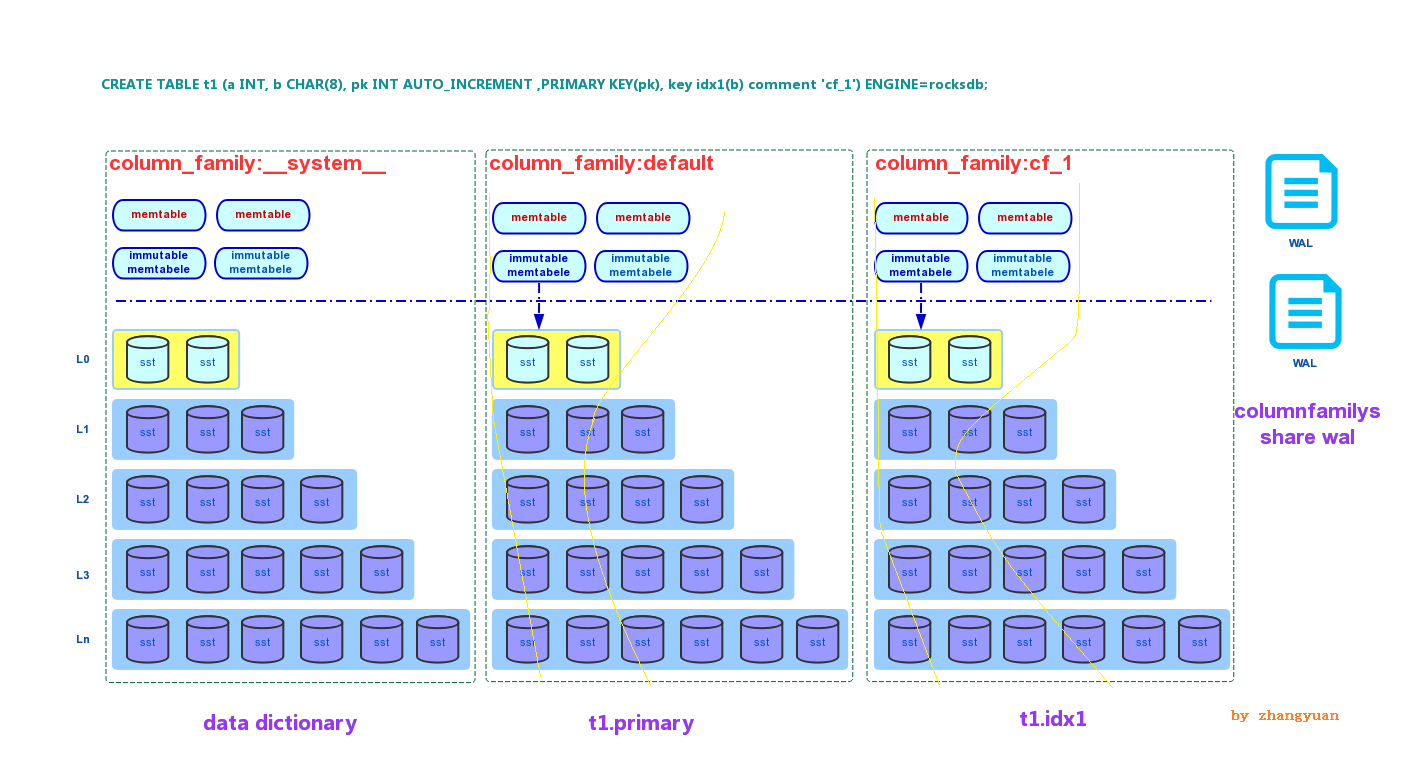
元数据分布在系统column family __system__中
primary key 分布在column family default中
idx1 分布在column family cf_1中
黄线之间代表数据分布的范围
- drop table
drop table t1;
batch->Put 将索引加入到待删的kv队列中
{DDL_DROP_INDEX_ONGOING(4)+cf_id(0)+index_id(260)} --> {DDL_DROP_INDEX_ONGOING_VERSION(2)}
{DDL_DROP_INDEX_ONGOING(4)+cf_id(2)+index_id(261)} --> {DDL_DROP_INDEX_ONGOING_VERSION(2)}
batch->Delete 删除表的映射关系
表和索引的映射关系
后台线程再从待删的kv队列取出待删的索引,通过 DeleteFilesInRange, CompactRange 删除索引数据。
后台线程确定索引数据删除完成后,batch删除相应的DDL_DROP_INDEX_ONGOING和INDEX_INFO的索引信息。
myrocks 之数据字典的更多相关文章
- MyRocks简介
RocksDB是facebook基于LevelDB实现的,目前为facebook内部大量业务提供服务.经过facebook大量工作,将RocksDB为MySQL的一个存储引擎移植到MySQL,称之为M ...
- MyRocks DDL原理
最近一个日常实例在做DDL过程中,直接把数据库给干趴下了,问题还是比较严重的,于是赶紧排查问题,撸了下crash堆栈和alert日志,发现是在去除唯一约束的场景下,MyRocks存在一个严重的bug, ...
- myrocks复制中断问题排查
背景 mysql可以支持多种不同的存储引擎,innodb由于其高效的读写性能,并且支持事务特性,使得它成为mysql存储引擎的代名词,使用非常广泛.随着SSD逐渐普及,硬件存储成本越来越高,面向写优化 ...
- Oracle数据字典
数据字典-简介 Oracle数据字典的名称由前缀和后缀组成,使用下划线"_"连接,其代表的含义如下: ● DBA_:包含数据库实例的所有对象信息. ● V$_:当前实例的动态视图, ...
- postgresql 导出数据字典文档
项目上需要整理目前数据库的数据字典文档.项目不规范,这种文档只要后期来补.这么多张表,每个字段都写到word文档里真心头大.就算前面写了个查询表结构的sql,但是最后整理到word里还是感觉有点麻烦. ...
- 基于表的数据字典构造MySQL建表语句
表的数据字典格式如下: 如果手动写MySQL建表语句,确认麻烦,还不能保证书写一定正确. 写了个Perl脚本,可快速构造MySQL脚本语句. 脚本如下: #!/usr/bin/perl use str ...
- 使用 PowerDesigner 和 PDMReader 逆向生成 MySQL 数据字典
下面提到的软件大家可以在下面的链接下载. 大家可以参考下面的操作录制视频来完成相关的操作. 使用 PowerDesigner 和 PDMReader 逆向生成 MySQL 数据字典.wmv_免费高速下 ...
- 【Java EE 学习 30】【闪回】【导入导出】【管理用户安全】【分布式数据库】【数据字典】【方案】
一.闪回 1.可能的误操作 (1)错误的删除了记录 (2)错误的删除了表 (3)查询历史记录 (4)撤销已经提交了的事务. 2.对应着以上四种类型的误操作,有四种闪回类型 (1)闪回表:将表回退到过去 ...
- 数据字典生成工具之旅(5):DocX组件读取与写入Word
由于上周工作比较繁忙,所以这篇文章等了这么久才写(预告一下,下一个章节正式进入NVelocity篇,到时会讲解怎么使用NVelocity做一款简易的代码生成器,敬请期待!),好了正式进入本篇内容. 这 ...
随机推荐
- SpringMVC+Freemarker+JSTL支持
前提: 网页编程中,我的思路是,通用的模块不仅仅只有后台代码,前端页面也可以独立为模块. 这个和asp.net中的UserController很像 比如有个人员基本信息的展示界面,需要在多个界面中嵌入 ...
- 模糊测试(Fuzz testing)
模糊测试(fuzz testing)是一种安全测试方法,他介于完全的手工测试和完全的自动化测试之间.为什么是介于那两者之间?首先完全的手工测试即是渗透测试,测试人员可以模拟黑客恶意进入系统.查找漏洞, ...
- export LD_LIBRARY_PATH=/opt/gtk/lib:$LD_LIBRARY_PATH
如题,临时修改程序运行时动态库的搜索路径,平时经常会用到,记录之!
- 持续集成工具Jenkins学习总结
概述 持续集成(Continuous Integration,简称CI)是一种软件开发实践,团队开发人员每次都通过自动化的构建(编译.发布.自动化测试)来验证,从而尽早的发现集成错误.持续集成最大的优 ...
- Flask备注三(Context)
Flask备注三(Context) Flask支持不同的应用场景下,对应不同的local context(本地上下文环境),用来提供当前环境下的资源.lcoal context和全局变量以及局部变量最 ...
- SQL联合更新(只要有关联字段就能执行更新!)
update t1 set KCLX=t2.KCLX,KSFS=t2.KSFS from JX_PlannedCourse t1 inner join JX_Course t2 on t1.KCDM= ...
- ready与onload区别一
<!DOCTYPE html><html> <head> <title>ready与onload区别一</title> <meta c ...
- Google高级搜索语法
Google高级搜索语法 Google搜索果真是一个强悍的不得了的搜索引擎,今天转了一些 google的高级搜索语法 希望能帮助到大家. 一.allinanchor: anchor是一处说明性的文 ...
- CSS position绝对定位absolute relative
常常使用position用于层的绝对定位,比如我们让一个层位于一个层内具体什么位置,为即可使用position:absolute和position:relative实现. 一.position语法与结 ...
- css+js定位到屏幕中间
ex:让一个div始终显示在屏幕中间 一. css:#idName{position: absolute;z-index: 999;width: ?px;margin-top: ?px;}//此处的初 ...