ULMFiT 阅读笔记
ULMFiT 阅读笔记
概述
这篇文章从文本分类模型入手,主要提出了两点:一是预训练语言模型在大中小规模的数据集中都能提升分类效果,在小规模数据集中效果尤为显著。二是提出了多种预训练的调参方法,包括Discriminative Fine-tuning(分层微调。我自己取的名字,下同),Slanted triangular learning rates(斜三角学习率),Concat pooling(拼接池化),Gradual unfreezing(逐层解冻),双向语言模型等。
模型
本文以LSTM为基本单元设计了一个单向的语言模型,并将整个训练过程从预训练到最终训练分类器分为3个部分。
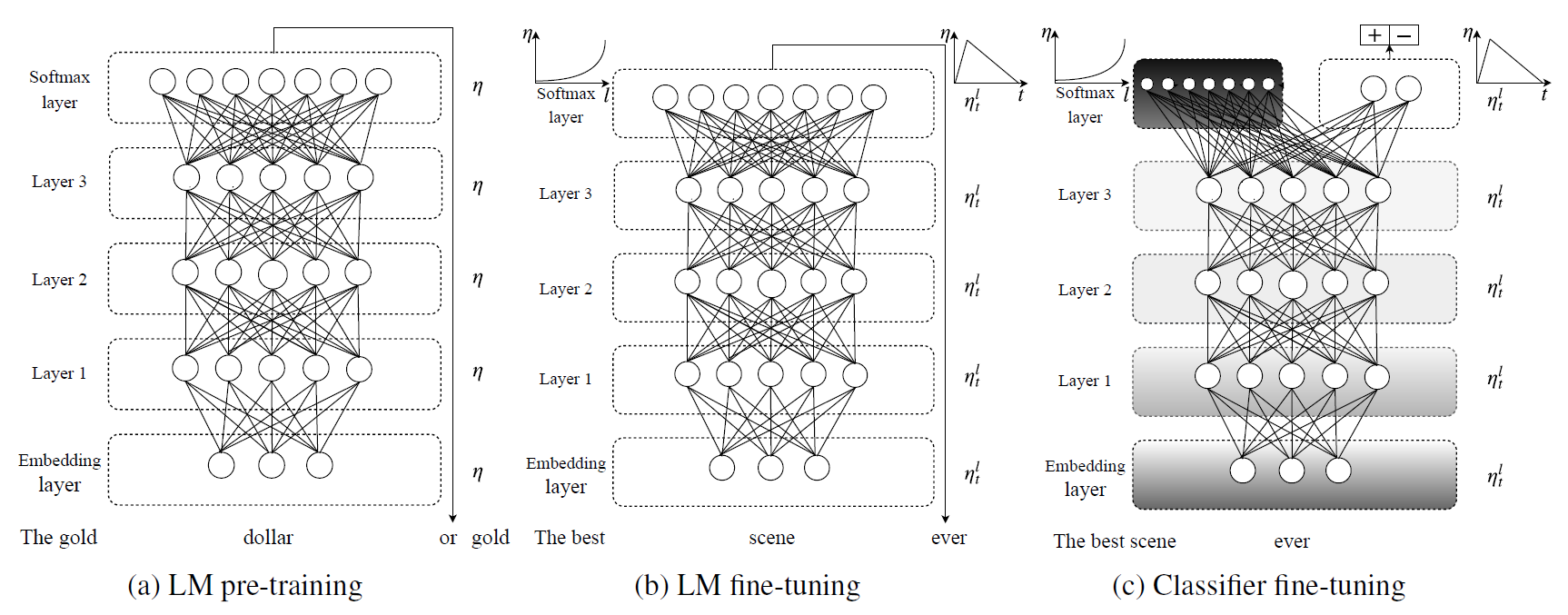
- 第一部分:语言模型预训练。使用Wikitext-103数据集训练语言模型。
- 第二部分:语言模型微调。使用分层微调和斜三角学习率,在目标任务的数据集上微调语言模型的参数,学习该任务的语言特征。
- 第三部分:固定语言模型的softmax层,将分类层加入到模型中,使用逐层解冻、分层微调、斜三角学习率等方法,在保留低层表示信息的情况下,对模型高层参数参数进行微调。
作者还尝试了双向语言模型,不过其本质是两个独立的单向模型,最后再进行拼接整合用于分类。
微调方法
分层微调
每一层使用不同的学习率。通过尝试,作者发现先确定顶层的学习率,其余层与层之间的学习率排列在一起构成一个等比数列,公比取1/2.6效果比较好。即n_l-1 = n_l/2.6。
斜三角学习率
先上图,0.01是设定好的学习率超参:
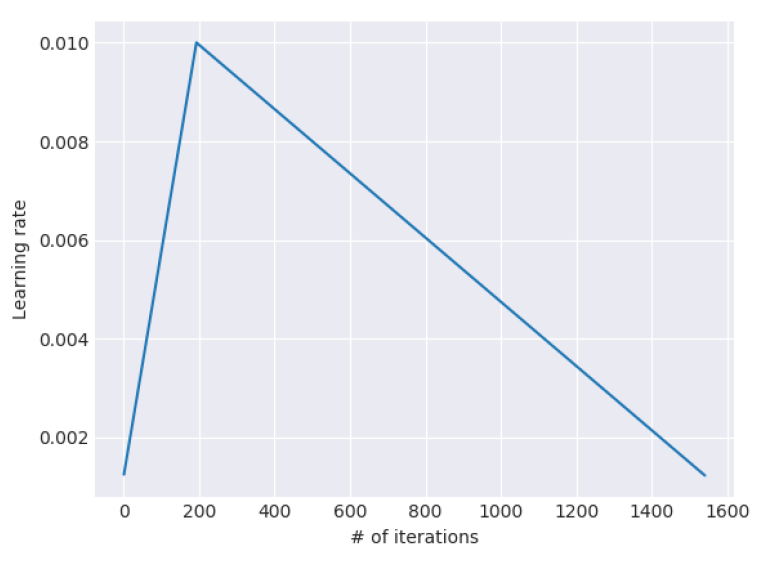
注意横坐标单位是迭代总次数。
上公式:

- T: 预设的总迭代轮数,等于epoch * 每个epoch中的batch数。我感觉可能要尝试一下初次训练在什么时候取得最优值,然后设置稍大一些,可能比较好。
- cut_frac: 学习率上升部分的iteration比例,一般10%。BERT官方代码中,warm up的这个比例也是10%。cut表示上升部分的迭代次数。
- 第二个公式p看起来复杂,我们代入3个点进去就知道了。t=0和t=cut代进去,得到p=0和p=1,表明学习率上升过程的线性变化,t=cut和p=0代进去,得到p=1和t=T,表明学习率下降过程的线性变化。
- ratio的目的是保证学习率不降为0。p->1时,n_t->n_max。这和n_t=p*n_max是等价的。p->0时,n_t->1/ratio,相当于将点(0,0)挪到了(0, 1/ratio),给学习率设置了一个下限,避免学习率变为0。当然,当迭代次数超过T以后,学习率还是可能变为0。
拼接池化
正常在使用单向LSTM进行分类任务时,都是将最后时刻的输出作为softmax的输入,然后进行分类。作者认为决定分类结果的关键词语可能出现在文本的任意位置,而输入文本有可能包含数百个词语,如果只考虑最后时刻的输出,信息可能丢失,因此作者设计了拼接池化。作者将每个时刻的输出放到一起,做了max-pooling和mean-pooling两种操作,得到两个向量,然后将这俩向量拼接到最后时刻的输出h_T后面,构成完整地特征向量,作为softmax层的输入用于分类
思考:为什么不使用attention机制呢?池化和attention相比有何优劣
逐层解冻
作者认为同时微调所有层可能为导致模型遗忘了预训练时学到的参数,从而跳出最优解(我们假定预训练时学到的参数已经是全局最小值),最终困于局部极小值而无法回到预训练中学到的全局最小值。
作者先解冻最后一层,固定低层参数不变,然后开始训练。每一轮次训练结束后,由高到低解冻一层参数,直到所有层的参数都被微调并且模型收敛。
该方法和2017年提出的chain-thaw很像,区别是chain-thaw每次只训练一层,作者每次多训练一层。
实验和分析
作者使用了6个数据集进行尝试:
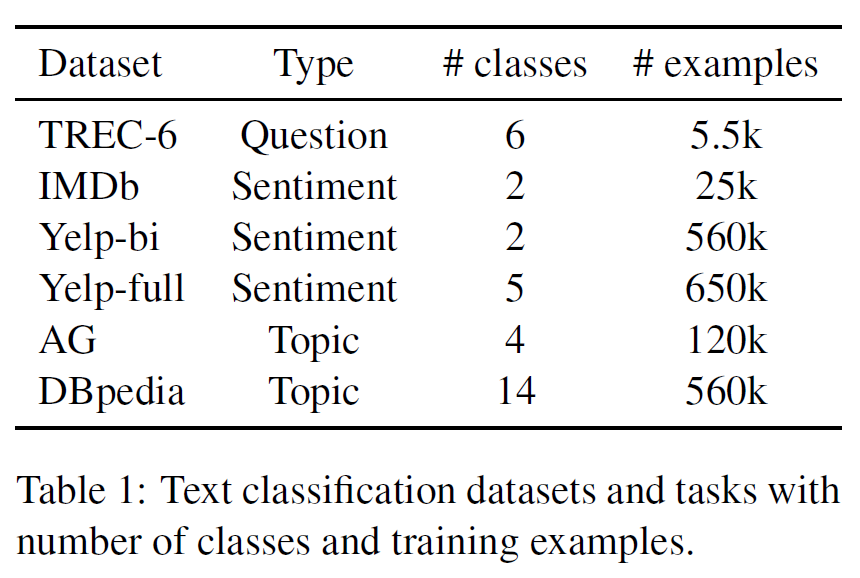
重点关注TREC-6、IMDb和AG,他们分别代表不同类型、不同数据量级的数据集。
实验1:验证ULMFiT模型有效性。在所有模型中达到了SOTA,越大的数据集效果越明显。
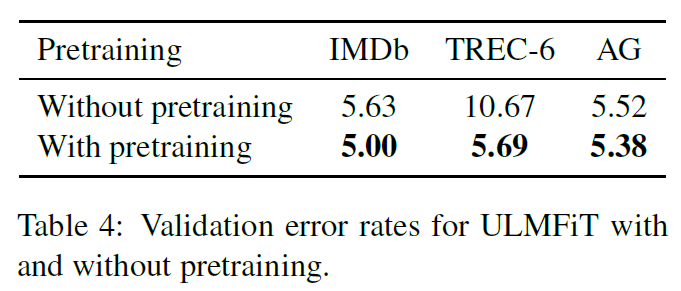
实验2:验证相同模型下,预训练带来的效果提升。越小的数据集效果越明显。
实验3:LM fine-tuning过程中分层微调和斜三角学习率的效果。STLR的效果十分明显。
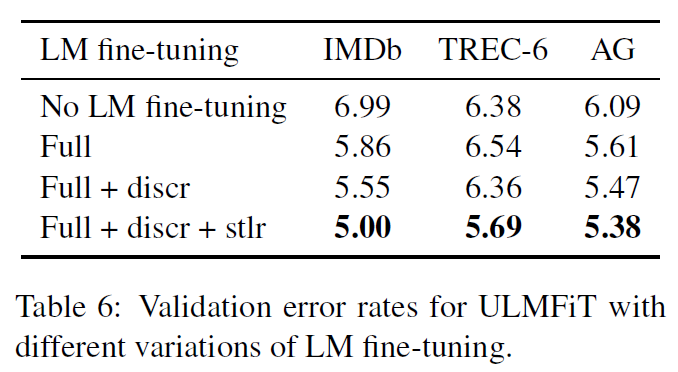
实验4:Classifier fine-tuning过程中分层微调、斜三角学习率和逐层解冻的效果。对比有chain-thaw和学习率余弦(cos)衰减。总的来说STLR表现确实好。

思考: STLR和warm-up的异同?
ULMFiT 阅读笔记的更多相关文章
- 阅读笔记 1 火球 UML大战需求分析
伴随着七天国庆的结束,紧张的学习生活也开始了,首先声明,阅读笔记随着我不断地阅读进度会慢慢更新,而不是一次性的写完,所以会重复的编辑.对于我选的这本 <火球 UML大战需求分析>,首先 ...
- [阅读笔记]Software optimization resources
http://www.agner.org/optimize/#manuals 阅读笔记Optimizing software in C++ 7. The efficiency of differe ...
- 《uml大战需求分析》阅读笔记05
<uml大战需求分析>阅读笔记05 这次我主要阅读了这本书的第九十章,通过看这章的知识了解了不少的知识开发某系统的重要前提是:这个系统有谁在用?这些人通过这个系统能做什么事? 一般搞清楚这 ...
- <<UML大战需求分析>>阅读笔记(2)
<<UML大战需求分析>>阅读笔记(2)> 此次读了uml大战需求分析的第三四章,我发现这本书讲的特别的好,由于这学期正在学习设计模式这本书,这本书就讲究对uml图的利用 ...
- uml大战需求分析阅读笔记01
<<UML大战需求分析>>阅读笔记(1) 刚读了uml大战需求分析的第一二章,读了这些内容之后,令我深有感触.以前学习uml这门课的时候,并没有好好学,那时我认为这门课并没有什 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
随机推荐
- Win10更换电脑,又不想重装系统的解决方法
问题描述: 在公司因为两年前用的i3的电脑很卡,然后想换i5的电脑,但是又不想重装系统,因为安装的东西太多了,重装很麻烦 Windows to go介绍: Windows To Go是Windows ...
- 微软公布针对最新IE漏洞的安全通报2963983
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/MSSecurity/article/details/24637607 微软于昨天公布了一篇最新 ...
- javascript中的for in循环和for in循环的使用陷阱
javascript中的for循环和for...in循环还是有些区别的,比如定义一个数组,然后用for..in循环输出 var array=[1,2,3,4,5,6]; for(var s in ar ...
- golang []byte和string相互转换
测试例子 package main import ( "fmt" ) func main() { str2 := "hello" ...
- [WC2011]最大XOR和路径
嘟嘟嘟 不愧是WC的题,思维真的很妙(虽然代码特别简单). 首先暴力找出所有路径肯定不行. 题中说可以经过重复的边,并且边权也会被计算多次.那么就是说,如果经过一条边再沿这条边回来,这条边的贡献就是0 ...
- k8s部署rocketmq 双主
由于apache 官网的 docker image 是单点,要实现集群方式部署. rocketmq 分为 nameserver 和 broker , 对于之间调用频繁的服务,会增加网络压力, 所以 考 ...
- Arduino 433 自定义发射
/* This is a minimal sketch without using the library at all but only works for the 10 pole dip swit ...
- metamascara学习导论
研究了一段时间的metamascara终于有了一点起色,因为前段时间有一个小伙伴问了我一个问题,就是能不能将metamask嵌入到自己设计的网站中,在自己要进行交易的时候也会弹出一个页面来让用户确认这 ...
- WordPress数据库及各表结构分析
默认WordPress一共有以下11个表.这里加上了默认的表前缀 wp_ . wp_commentmeta:存储评论的元数据wp_comments:存储评论wp_links:存储友情链接(Blogro ...
- jenkins编译jar包 报connection连接错误
原因是因为编译启动连接了注册中心 eureka.client.service-url.defaultZone=http://localhost:8093/eureka/ eureka.client.r ...