scrapy初探(一)-斗鱼TV直播信息抓取
由于有相关需求,最近两天开始学了一下scrapy
这次我们就以爬取斗鱼直播间为例,我们准备爬取斗鱼所有的在线直播信息,
包括1.主播昵称 2.直播领域 3.所在页面数 4.直播观看人数 5.直播间url
开始准备爬取的页面如图
url为:https://www.douyu.com/directory/all

但实际经过查看发现翻页是由ajax响应的,实际的ajax页面为:
https://www.douyu.com/directory/all?page=1&isAjax=1
其中page即为页面数
我们所需要的信息也在页面中,所以直接爬取该页面即可,
先编辑items.py
class ProjectItem(scrapy.Item):
title=scrapy.Field()
user=scrapy.Field()
num=scrapy.Field()
area=scrapy.Field()
zhibojian=scrapy.Field()
index=scrapy.Field()
接着编写spider.py,其中思路比较简单,回调函数即为parse本身,由于网站当页面超过实际页面时,显示的是第一页信息,而且页面是动态的,所以我们对第一页的zhibojian信息保存,保存在box中,并对index>30时进行判断,一旦直播间信息出现在box中,说明为第一页了。
index=1
box=[] def handlenum(char):
if u'万' in char[0]:
char[0] = str(float(char[0].replace(u'万', '')) * 10000)
return char class newspider(scrapy.Spider):
name='ajax'
allowed_domains = ["www.douyu.com", 'douyucdn.cn']
start_urls = ["https://www.douyu.com/directory/all?page=1&isAjax=1"] def parse(self, response):
global index,box
selector=Selector(response)
for sel in selector.xpath('/html/body/li'):
item=ProjectItem()
item['title']=sel.xpath('a/@title').extract()
item['user']=sel.xpath('a/div/p/span[1]/text()').extract()
num=sel.xpath('a/div/p/span[2]/text()').extract()
item['num'] =handlenum(num)
item['area']=sel.xpath('a/div/div/span/text()').extract()
zhibojian=sel.xpath('a/@href').extract()
if index is 1:
box.append(zhibojian[0])
elif index>20:
if zhibojian[0] in box:
return
item['zhibojian']=zhibojian
item['index']=index
yield item
index+=1
nexturl='https://www.douyu.com/directory/all?page=%s&isAjax=1'%str(index)
yield scrapy.Request(nexturl,callback=self.parse)
最后设置setting.py,这里我们使用csv格式来保存
FEED_URI=u'file:///C:/Users/tLOMO/Desktop/one.csv'
FEED_FORMAT='CSV'
最后运行即可得到one.csv
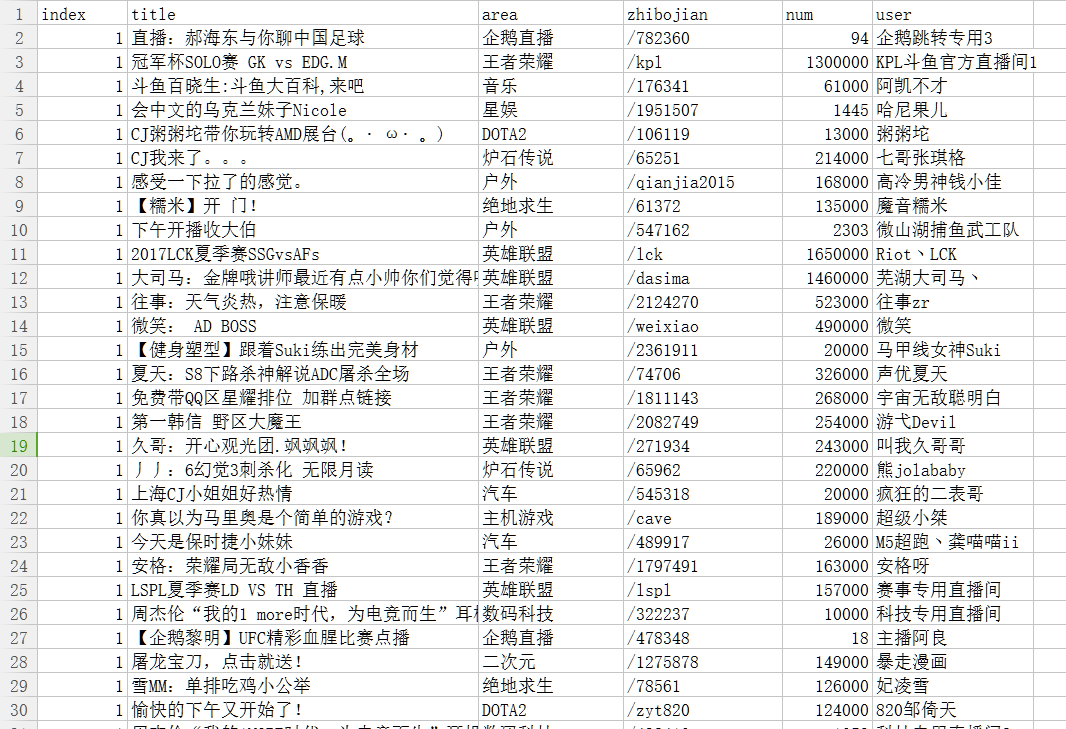
进过统计,我程序跑的时候,所有观看直播的人数为18290373,这个数字可信度我也搞不清啊,简单看了一下,所有的直播中直播农药和LOL的是最多的
scrapy初探(一)-斗鱼TV直播信息抓取的更多相关文章
- [转载]Fiddler为所欲为第四篇 直播源抓取与接口分析 [四]
今天的教程,主要是教大家如何进行“封包逆向”,关键词跳转,接口分析.(怎么样,是不是感觉和OD很像~~~)今天的教程我们以[麻花影视]为例,当然,其他APP的逻辑也是一样,通用的哦~ 首先需要做好准备 ...
- 网页信息抓取进阶 支持Js生成数据 Jsoup的不足之处
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/23866427 今天又遇到一个网页数据抓取的任务,给大家分享下. 说道网页信息抓取 ...
- Ajax异步信息抓取方式
淘女郎模特信息抓取教程 源码地址: cnsimo/mmtao 网址:https://0x9.me/xrh6z 判断一个页面是不是Ajax加载的方法: 查看网页源代码,查找网页中加载的数据信息,如果 ...
- Atitit.web的自动化操作与信息抓取 attilax总结
Atitit.web的自动化操作与信息抓取 attilax总结 1. Web操作自动化工具,可以简单的划分为2大派系: 1.录制回放 2.手工编写0 U' z; D! s2 d/ Q! ^1 2. 常 ...
- 网页信息抓取 Jsoup的不足之处 httpunit
今天又遇到一个网页数据抓取的任务,给大家分享下. 说道网页信息抓取,相信Jsoup基本是首选的工具,完全的类JQuery操作,让人感觉很舒服.但是,今天我们就要说一说Jsoup的不足. 1.首先我们新 ...
- 网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp)
转自原文 网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp) 最近在弄网页爬虫这方面的,上网看到关于htmlagilitypack搭配scrapysharp的文章,于是决 ...
- 接口测试——fiddler对soapui请求返回信息抓取
原文:接口测试——fiddler对soapui请求返回信息抓取 背景:接口测试的时候,需要对接口的请求和返回信息进行查阅或者修改请求信息,可利用fiddler抓包工具对soapui的请求数据进行抓取或 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- Windows Phone & Windows App应用程序崩溃crash信息抓取方法
最近有用户反馈,应用有崩溃的情况,可是本地调试却无法重现问题,理所当然的,我想到了微软的开发者仪表盘,可以查看一段时间内的carsh记录,不过仪表盘生成carsh记录不是实时的,而且生成的报告查看非常 ...
随机推荐
- (转) SpringMVC学习笔记-
一.SpringMVC基础入门,创建一个HelloWorld程序 1.首先,导入SpringMVC需要的jar包. 2.添加Web.xml配置文件中关于SpringMVC的配置 <!--conf ...
- phpstudy 安装 Apcahe SSL证书 实现https连接
摘自:https://jingyan.baidu.com/article/64d05a022e6b57de54f73b51.html Windows phpstudy安装ssl证书教程. 工具/原料 ...
- Python assert断言
assert断言:指定某个对象判断类型,不成立则报错. 使用环境 :接下来程序的执行,如果依赖前面的类型,不能报错的情况下使用. assert type(obj) is str print(&quo ...
- 安装GDB-ImageWatch ,在QT中查看图像
GDB_ImageWatch是在Linux下基于QT编写图像处理程序的调试程序. 由于并非像ImageWatch一样由官方提供,而是在github上以代码的方式进行提供,我们在使用的时候需要自己编译, ...
- linux --- 7. 路飞学城部署
一.前端 vue 部署 1.下载项目的vue 代码(路飞学城为例), wget https://files.cnblogs.com/files/pyyu/07-luffy_project_01.zip ...
- Codeforces Round #467 (Div. 2) B. Vile Grasshoppers
2018-03-03 http://codeforces.com/problemset/problem/937/B B. Vile Grasshoppers time limit per test 1 ...
- 委托&&异步
private void ShowMessage(string message) { this.BeginInvoke(new MethodInvoker(delegate { txtSysMessa ...
- Lintcode482-Binary Tree Level Sum-Easy
482. Binary Tree Level Sum Given a binary tree and an integer which is the depth of the target level ...
- nmon 性能监控网页结果显示——EasyNmon
首先,看看最终展示的结果显示样式: 报告界面: 1.安装包下载地址:https://github.com/mzky/easyNmon 2.下载后有2个压缩文件: 其中,nmon16g_x86中含有不同 ...
- C# 图片缩略图
/// <summary> /// 生成缩略图 /// </summary> /// <param name="sourceFile">原始图片 ...