Hive--关联表(join)
在hive中,关联有4种方式:
- 内关联:join on
- 左外关联:left join on
- 右外关联:right join on
- 全外关联:full join on
另外还有一种可实现hive笛卡儿积的效果(hive不支持笛卡儿积): 在on后面接为true的表达式,如on 1=1(需先设置非严格模式:set hive.mapred.mode=nonstrict);
详细操作和结果如下:
如我有两个表:join1和join2,如下
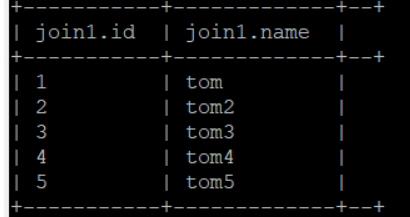
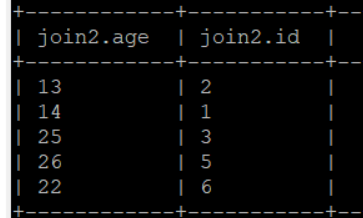
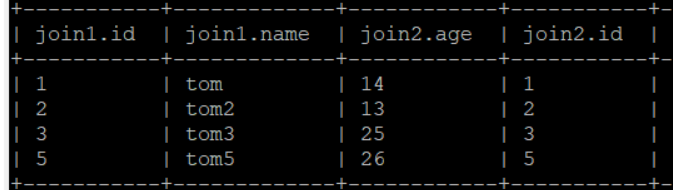
内关联:select * from jion1 join join2 on jion1.id = jion2.id;
- 作用:将表1和表2的字段id相同的内容 关联到一个表里。
- 效果如下:
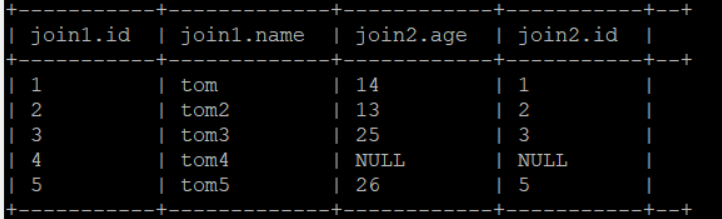
左外连接:select * from jion1 left join join2 on jion1.id = jion2.id;
- 作用:以join左边的表为标准进行连接(即保留左边表的字段值,右边表不符合on条件的用null表示)。
- 效果如下:
右外连接:select * from jion1 right join join2 on jion1.id = jion2.id;
- 作用:以join右边的表为标准进行连接(即保留右边表的字段值,左边表不符合on条件的用null表示)。
- 效果如下:
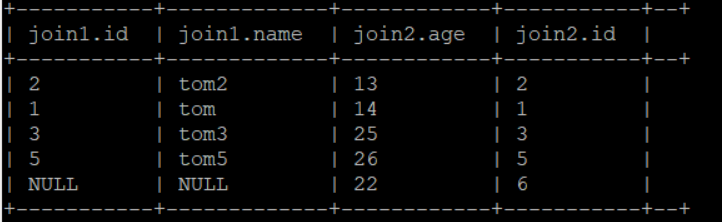
全外连接:select * from jion1 full join join2 on jion1.id = jion2.id;
- 作用:两个表连接,表留所有字段的值,不符合on条件的用null表示。
- 效果如下:

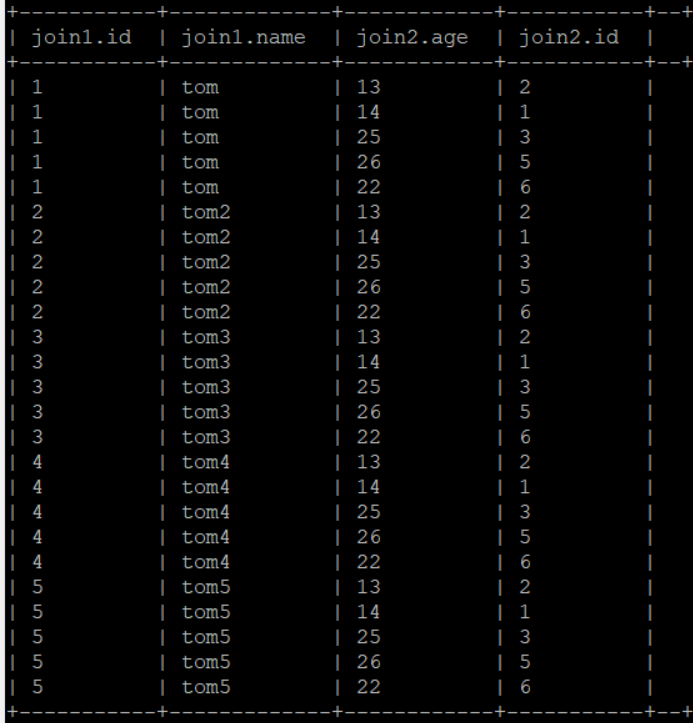
hive的”笛卡儿积“:select * from join1 join join2 on 1=1;
Hive--关联表(join)的更多相关文章
- hive中大表join
排序存储数据至BUCKETS,这样可以顺序进行join
- Hive中小表与大表关联(join)的性能分析【转】
Hive中小表与大表关联(join)的性能分析 [转自:http://blog.sina.com.cn/s/blog_6ff05a2c01016j7n.html] 经常看到一些Hive优化的建议中说当 ...
- hive中与hbase外部表join时内存溢出(hive处理mapjoin的优化器机制)
与hbase外部表(wizad_mdm_main)进行join出现问题: CREATE TABLE wizad_mdm_dev_lmj_edition_result as select * from ...
- hadoop系列 第二坑: hive hbase关联表问题
关键词: hive创建表卡住了 创建hive和hbase关联表卡住了 其实针对这一问题在info级别的日志下是看出哪里有问题的(为什么只能在debug下才能看见呢,不太理解开发者的想法). 以调试模式 ...
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- springboot中使用JOIN实现关联表查询
* 首先要确保你的表和想要关联的表有外键连接 repository中添加接口JpaSpecificationExecutor<?>,就可以使用springboot jpa 提供的API了. ...
- Hive优化-大表join大表优化
Hive优化-大表join大表优化 5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个 ...
- hive join 优化 --小表join大表
1.小.大表 join 在小表和大表进行join时,将小表放在前边,效率会高.hive会将小表进行缓存. 2.mapjoin 使用mapjoin将小表放入内存,在map端和大表逐一匹配.从而省去red ...
- mysql 中LIKE 与FIND_IN_SET 与关联表left join 速度效率比较
有一张表Table有IDStr字段,如下只显示二个字段还有很多其他字段 方式一 字段逗号分割,直接用UserIDStr字段,里面存多个ID用逗号分割 UUID UserIDStr 1111 1,2,3 ...
随机推荐
- Tomcat启动阻塞变慢
Tomcat 熵池阻塞变慢详解 Tomcat 启动很慢,且日志上无任何错误,在日志中查看到如下信息: Log4j:[2015-10-29 15:47:11] INFO ReadProperty:172 ...
- Hyper-V迁移---委派
在Hyper-V管理器中-实时迁移,选择“使用kerberos",如图1所示 在AD中,找到Hyper-V宿主,分别设置委派,如图2所示 图1 图2
- git error:【fatal: unable to access 'https://github.com/userId/prjName.git/': err or setting certificate verify locations:】
$ git pull origin master fatal: unable to access 'https://github.com/userId/prjName.git/': err or se ...
- yii2.0里自己写的源码上传图片
在做项目过程中,用了源码表单上传, <form action="?r=pre/create" method="post" enctype="mu ...
- February 14 2017 Week 7 Tuesday
Love lives in cottages as well as in courts. 爱情无贵贱,贫富皆有之. Many people, especially boys, complain tha ...
- 入门摄影——尼康DX
学习链接 单反应当怎样入门? - Williams的回答 - 知乎 [摄影教程]尼康数码单反相机使用视频教程_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili 图像品质与图像大小 图像品质:暂选JP ...
- Python深入学习之《Fluent Python》 Part 1
Python深入学习之<Fluent Python> Part 1 从上个周末开始看这本<流畅的蟒蛇>,技术是慢慢积累的,Python也是慢慢才能写得优雅(pythonic)的 ...
- Python解析配置文件模块:ConfigPhaser
算是前几周落下的博客补一篇.介绍一下python中如何解析配置文件.配置文件常用的几种格式:xml,json,还有ini.其中ini算是最简单的一种格式,因为小,解析的速度也要比xml和json快(并 ...
- 在UML系统开发中有三个主要的模型
http://www.cnblogs.com/Yogurshine/archive/2013/01/14/2859248.html 在UML系统开发中有三个主要的模型: 功能模型: 从用户的角度展示系 ...
- JSFUtils
import java.util.Iterator; import java.util.Locale; import java.util.Map; import java.util.MissingRe ...