分别用Eclipse和IDEA搭建Scala+Spark开发环境
开发机器上安装jdk1.7.0_60和scala2.10.4,配置好相关环境变量。网上资料很多,安装过程忽略。此外,Eclipse使用Luna4.4.1,IDEA使用14.0.2版本。
1. Eclipse开发环境搭建
1.1. 安装scala插件
安装eclipse-scala-plugin插件,下载地址http://scala-ide.org/download/prev-stable.html

解压缩以后把plugins和features复制到eclipse目录,重启eclipse以后即可。
Window -> Open Perspective -> Other…,打开Scala,说明安装成功。
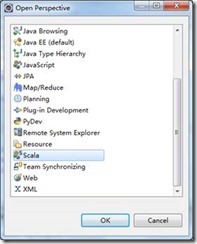
1.2. 创建maven工程
打开File -> New -> Other…,选择Maven Project:
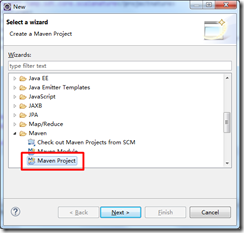
点击Next,输入项目存放路径:
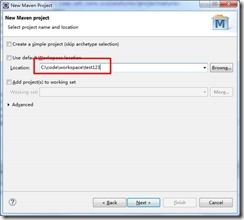
点击Next,选择org.scala-tools.archetypes:
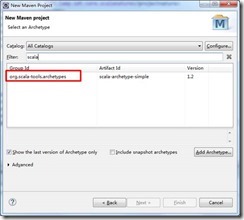
点击Next,输入artifact相关信息:

点击Finish即可。默认创建好的工程目录结构如下:
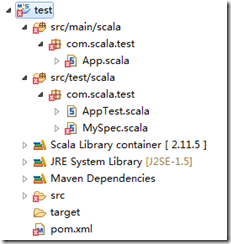
修改pom.xml文件:
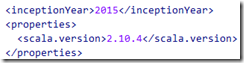
至此,一个默认的scala工程新建完成。
2. Spark开发环境搭建
2.1. 安装scala插件
开发机器使用的IDEA版本为IntelliJ IEDA 14.0.2。为了使IDEA支持scala开发,需要安装scala插件,如图:
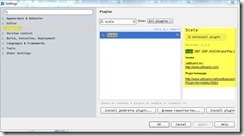
插件安装完成后,IntelliJ IDEA会要求重启。
2.2. 创建maven工程
点击Create New Project,在Project SDK选择jdk安装目录(建议开发环境中的jdk版本与Spark集群上的jdk版本保持一致)。点击左侧的Maven,勾选Create from archetype,选择org.scala-tools.archetypes:scala-archetype-simple:
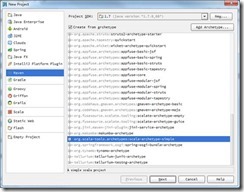
点击Next后,可根据需求自行填写GroupId,ArtifactId和Version(请保证之前已经安装maven)。点击Finish后,maven会自动生成pom.xml和下载依赖包。同1.2章节中eclipse下创建maven工程一样,需要修改pom.xml中scala版本。
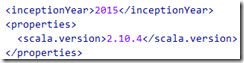
至此,IDEA下的一个默认scala工程创建完毕。
3. WordCount示例程序
3.1. 修改pom文件
在pom文件中添加spark和hadoop相关依赖包:
<!-- Spark --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.1.0</version> </dependency> <!-- Spark Steaming--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.1.0</version> </dependency> <!-- HDFS --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency>
在<build></build>中使用maven-assembly-plugin插件,目的是package时把依赖jar也打包。
<plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.5.5</version> <configuration> <appendAssemblyId>false</appendAssemblyId> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>com.ccb.WordCount</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>assembly</goal> </goals> </execution> </executions> </plugin>
3.2. WordCount示例
WordCount用来统计输入文件中所有单词出现的次数,代码参考:
package com.ccb
import org.apache.spark.{ SparkConf, SparkContext }
import org.apache.spark.SparkContext._
/**
* 统计输入目录中所有单词出现的总次数
*/
object WordCount {
def main(args: Array[String]) {
val dirIn = "hdfs://192.168.62.129:9000/user/vm/count_in"
val dirOut = "hdfs://192.168.62.129:9000/user/vm/count_out"
val conf = new SparkConf()
val sc = new SparkContext(conf)
val line = sc.textFile(dirIn)
val cnt = line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) // 文件按空格拆分,统计单词次数
val sortedCnt = cnt.map(x => (x._2, x._1)).sortByKey(ascending = false).map(x => (x._2, x._1)) // 按出现次数由高到低排序
sortedCnt.collect().foreach(println) // 控制台输出
sortedCnt.saveAsTextFile(dirOut) // 写入文本文件
sc.stop()
}
}
3.3. 提交spark执行
使用maven pacakge打包得到sparktest-1.0-SNAPSHOT.jar,并提交到spark集群运行。
执行命令参考:
|
./spark-submit --name WordCountDemo --class com.ccb.WordCount sparktest-1.0-SNAPSHOT.jar |
即可得到统计结果。
分别用Eclipse和IDEA搭建Scala+Spark开发环境的更多相关文章
- 【转】Eclipse和PyDev搭建完美Python开发环境(Ubuntu篇)
原文网址:http://www.cnblogs.com/Realh/archive/2010/10/10/1847251.html 前两天在Windows下成功地搭好了一个Python开发环境,这次转 ...
- Eclipse和PyDev搭建完美Python开发环境(Windows篇)(转)
摘要:本文讲解了用Eclipse和PyDev搭建Python的开发环境. 十一长假在家闲着没事儿,准备花点时间学习一下Python. 今儿花了一个下午搭建Python的开发环境,不禁感叹————开 ...
- 【Spark笔记】Windows10 本地搭建单机版Spark开发环境
0x00 环境及软件 1.系统环境 OS:Windows10_x64 专业版 2.所需软件或工具 JDK1.8.0_131 spark-2.3.0-bin-hadoop2.7.tgz hadoop-2 ...
- 搭建eclipse+maven+scala-ide的scala web开发环境
http://www.tuicool.com/articles/NBzAzy 江湖传闻,scala开发的最佳利器乃 JetBrains 的神作 IntelliJ IDEA ,外加构建工具sbt 是也. ...
- Windows下Eclipse+Scala+Spark开发环境搭建
1.安装JDK及配置java环境变量 本文使用版本为jdk1.7.0_79,过程略 2.安装scala 本文使用版本为2.11.8,过程略 3.安装spark 本文使用版本为spark-2.0.1-b ...
- Eclipse和PyDev搭建完美Python开发环境(Windows篇)
目录安装Pythonpython for eclipse插件安装配置PyDev插件测试 安装Python从网站上下载最新的版本,从http://python.org/download/下载.安装过程与 ...
- Eclipse和PyDev搭建完美Python开发环境 Windows篇
1,安装Python Python是一个跨平台语言,Python从3.0的版本的语法很多不兼容2版本,官网找到最新的版本并下载:http://www.python.org, 因为之前的一个项目是2版本 ...
- eclipse+cygwin+cdt搭建c/c++开发环境
Cygwin 是一个用于 Windows 的类 UNIX shell 环境. 它由两个组件组成:一个 UNIX API 库,它模拟 UNIX 操作系统提供的许多特性:以及 Bash shell 的改写 ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
随机推荐
- cf449D. Jzzhu and Numbers(容斥原理 高维前缀和)
题意 题目链接 给出\(n\)个数,问任意选几个数,它们\(\&\)起来等于\(0\)的方案数 Sol 正解居然是容斥原理Orz,然而本蒟蒻完全想不到.. 考虑每一种方案 答案=任意一种方案 ...
- 【Android】16.0 UI开发(七)——列表控件RecyclerView的点击事件实现
1.0 在各布局的基础上,修改ProvinceAdapter.java的代码: package com.example.recyclerviewtest; import android.support ...
- 在WinServer上安装小红伞杀毒软件的经验总结
作者:朱金灿 来源:http://blog.csdn.net/clever101 在WinServer2008或WinServer2012不能直接安装小红伞杀毒软件的免费版,需要安装服务器版.我手头并 ...
- Java 之 static的使用方法(6)
Java 中的 static 使用之静态变量 大家都知道,我们可以基于一个类创建多个该类的对象,每个对象都拥有自己的成员,互相独立. 然而在某些时候,我们更希望该类所有的对象共享同一个成员.此时就是 ...
- 一、CSS实现横列布局的方法总结
一.使用float实现横列布局的方法 如下面所示:DIV1和DIV2都可以选择向左或者向右浮动50%来实现展示在同一行 div1 div2 实现下面图片中布局的css样式如下: 分析: 1.第一行第一 ...
- addEventListener(event, function, useCapture) 简记
监听事件方法:addEventListener(<event-name>, <callback>, <use-capture>) 移除监听事件方法:removeEv ...
- 安装busybox玩玩
到http://www.busybox.net/downloads/binaries/下载放到sdcard然后adb shellsumount -o remount,rw -t yaffs2 /dev ...
- nginx 两台机器 出现退款失败问题
今天早上来公司后,测试人员告诉我 退款失败了.上周五还好好的,怎么这周三就出问题了,赶快让测试发来订单号,查询数据库,查询日志,发现还是以前的问题: search hit TOP, continuin ...
- html 表单button
做一下标记: 请务必为form里面button设置type 因为: Internet Explorer 的默认类型是 "button",而其他浏览器中(包括 W3C 规范)的默认值 ...
- mongodb 3.4 TAR包启动多个实例
1:解压压缩文件 tar .tgz mkdir /home/maxiangqian/ mv mongodb /home/maxiangqian/ 2:加入环境变量 export PATH/bin:$P ...