CUDA线程
建议先看看前言中关于存储器的介绍:点击打开链接
线程
首先介绍进程,进程是程序的一次执行,线程是进程内的一个相对独立的可执行的单元。若把进程称为任务的话,那么线程则是应用中的一个子任务的执行。举个简单的例子:一个人要做饭,食谱就是程序代码,做的过程就是执行程序,做好的饭就是程序运行的结果,而在这期间,需要炒菜,放盐,放油等等就是线程。
线程同步
调用__syncthreads 创建一个 barrier 栅栏
每个线程在调用点等待块内所有线程执行到这个地方,然后所有线程继续执行后续命令
Mds[i] = Md[j]; __syncthreads(); func(Mds[i],Mds[i+]);
要求线程的执行时间尽量接近,因为执行时间差别过大,等待时间过长,效率低下。
只在块内同步,全局同步开销大
线程同步会导致死锁,例如:
if(someFunc())
{
__syncthreads();
}
else {
__syncthreads();
}
线程调度
Warp——块内的一组线程,一般是32个线程为一组
线程调度的基本单位
运行于同一个 SM(流多处理器)
内部threadIdx值连续
warp内部线程不能沿不同分支执行
线程层次
Grid——一维或多维线程块(block)
一维或二维
Block——一组线程
一维,二维或三维
一个 Grid 里的每个 Block 的线程数是一样的
block内部的内个线程可以同步(synchronize)和访问共享存储器(shared memory)
线程组织模型
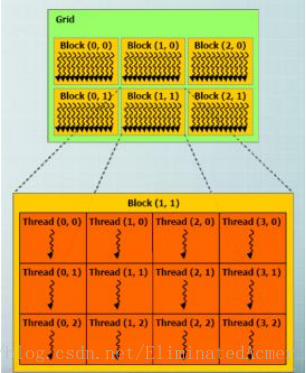
block下由线程束(warp) 组成,block 内部的线程共享“shared memory”
可以同步 “__syncthreads()”
一个Kernel具有大量线程,Kernel启动一个 “grid”,包含若干线程块,用户设定
下图是一个 grid 模型:
从图中可以看出这个 grid 中用户指定了 2 个线程块,每个线程块中有 2 个线程
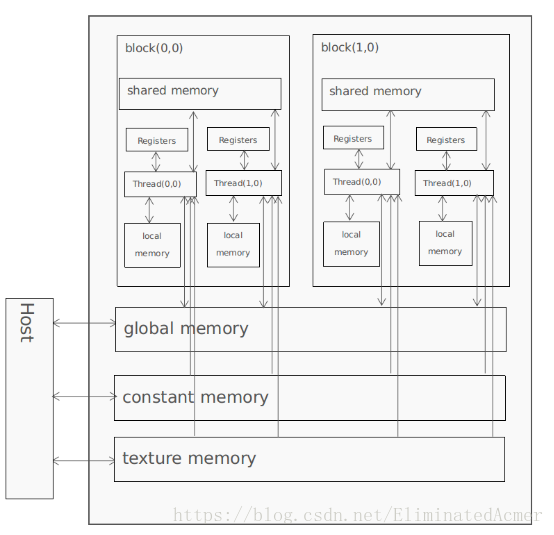
可以看到CUDA内存传输是这样:
Device端
针对每个线程,可以读写 local memory 和 register
针对每个线程块,可以读写 shared memory
针对每个 grid,可以读写 global memory,只读 constant memory 和 texture memory
Host端
可以读写 global memory,constant memory 和 texture memory
回顾线程层次
首先看一个计算 N × N 矩阵的例子:
假设N = 32
先指定 Grid 里面有 2 × 2 个线程块 Block,表示为
blockIdx ([0,1],[0,1])
每个块有 16 × 16 个线程 (跟 N 无关),表示为
threadIdx ([0,15],[0,15])
块大小这样表示
blockDim = 16
则某个线程的真实索引为
i = [0,1] * 16 + [0,15]
线程索引: threadIdx
一维Block Thread ID == Thread Index
二维 Block (Dx,Dy)
Thread ID of index(x,y) == x + yDy
三维 Block (Dx,Dy,Dz)
Thread ID of index(x,y,z) == x + yDx + zDxDy
计算 N × N 矩阵,指定线程块为 1 块,大小为矩阵大小
__global__ void MatAdd(float A[N][N],float B[N][N],float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
int numBlocks = ; //指定线程块为 1
dim3 threadsPerBlock(N,N); //指定大小为 N × N
MatAdd<<<numBlocks,threadsPerBlock>>>(A,B,C);
}
Thread Block 线程块
线程的集合
位于相同的处理器核(SM)
共享所在核的存储器
块索引:blockIdx
维度:blockDim
一维,二维,三维
计算 N × N 矩阵,指定线程块大小为 16 × 16,若干个线程块
__global__ void MatAdd(float A[N][N],float B[N][N],float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if(i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
dim3 threadsPerBlock(,);
dim3 numBlocks(N / threadsPerBlock.x , N / threadsPerBlock.y);
MatAdd<<<numBlocks,threadsPerBlock>>>(A,B,C);
}
线程块之间彼此独立执行
任意顺序:并行或串行
被任意数量的处理器以任意顺序调度:处理器的数量具有可扩展性
一个块内部的线程
共享容量有限的低延迟存储器
同步执行:合并访存,__syncThreads():Barrier ——块内线程一起等待所有线程都执行某处语句,轻量级
实例演示
先介绍几个函数:
cudaMalloc()
在设备端分配 global memory
cudaFree()
释放存储空间
cudaMemcpy()
内存传输
Host to host
Host to device
Device to host
Device to device
cudaMemcpy(Md,M,size,cudaMemcpyHostToDevice);
Md 目的地址
M 原地址
size 大小
CPU端代码:
void MatrixMulOnHost(float** M,float** N,float** P,int width)
{
for(int i = ; i < width ; ++i)
for(int j = ; j < width ; ++j)
{
float sum = ;
for(int k = ; k < width ; ++k)
{
float a = M[i][k];
float b = N[k][j];
sum += a * b;
}
P[i][j] = sum;
}
}
CUDA 算法框架
int main()
{
1.管理内存,为输入的原始数据,以及输出结果在GPU上分配内存
2.并行处理
3.结果拷贝回 CPU,释放内存
return 0;
}
1.
int size = Width * Width * sizeof(float);
cudaMalloc(Md,size);
cudaMemcpy(Md,M,size,cudaMemcpyHostToDevice);
cudaMalloc(Nd,N,size,cudaMemcpyHostToDevice);
cudaMalloc(Pd,size);
2.
__global__ void MatrixMulKernel(float* Md,float* Nd,float* Pd,int width)
{
int tx = threadIdx.x;
int ty = threadIdx.y;
float Pvalue = ;
for(int k = ; k < width ; ++k) {
float Mdelement = Md[ty * Md.width + k];
float Ndelement = Nd[k * Nd.width + tx];
Pvalue += Mdelement * Ndelement;
}
Pd[ty * width + tx] = Pvalue;
}
3.
cudaMemcpy(P,Pd,size,cudaMemcpyDeviceToHost);
cudaFree(Md);
cudaFree(Nd);
cudaFree(Pd);在main()中调用 Kernel
dim3 dimBlock(WIDTH,WIDTH);
dim3 dimGrid(1,1);
MatrixMulKernel <<<dimGrid,dimBlock>>>(Md,Nd,Pd);完整GPU程序如下:
/*
============================================================================
Name : Martix.cu
Author : wzn
Version :
Copyright : Your copyright notice
Description : CUDA compute reciprocals
============================================================================
*/ #include <iostream>
#include <numeric>
#include <stdlib.h> __global__ void MatrixMulKernel(float* Md,float* Nd,float* Pd,int Width)
{
int tx = threadIdx.x;
int ty = threadIdx.y;
float Pvalue = ;
for(int k = ; k < Width ; ++k) {
float Mdelement = Md[ty * Width + k];
float Ndelement = Nd[k * Width + tx];
Pvalue += Mdelement * Ndelement;
}
Pd[ty * Width + tx] = Pvalue;
} int main(void)
{
int Width = ; int size = Width * Width * sizeof(float); float M[Width][Width],N[Width][Width],P[Width][Width]; for(int i = ;i<;i++){
for(int j = ;j<;j++){
M[i][j] = j;
N[i][j] = j;
}
} float *Md,*Nd,*Pd; cudaMalloc((void **)&Md,size);
cudaMalloc((void **)&Nd,size);
cudaMemcpy(Md,M,size,cudaMemcpyHostToDevice);
cudaMemcpy(Nd,N,size,cudaMemcpyHostToDevice); cudaMalloc((void **)&Pd,size); dim3 dimBlock(Width,Width);
dim3 dimGrid(,); MatrixMulKernel <<<dimGrid,dimBlock>>>(Md,Nd,Pd,Width); cudaMemcpy(P,Pd,size,cudaMemcpyDeviceToHost);
cudaFree(Md);
cudaFree(Nd);
cudaFree(Pd);
for(int i = ;i<;i++){
for(int j = ;j<;j++){
std::cout<<P[i][j]<<" ";
}
std::cout<<"\n";
} return ;
} CPU端程序: #include <iostream> using namespace std; void MatrixMulOnHost(float** M,float** N,float** P,int width)
{
for(int i = ; i < width ; ++i)
for(int j = ; j < width ; ++j)
{
float sum = ;
for(int k = ; k < width ; ++k)
{
float a = M[i][k];
float b = N[k][j];
sum += a * b;
}
P[i][j] = sum;
}
} int main()
{
int Width = ; float **M,**N,**P; M = new float* [Width];
for(int i = ;i<Width;i++)
M[i] = new float [Width]; N = new float* [Width];
for(int i = ;i<Width;i++)
N[i] = new float [Width]; P = new float* [Width];
for(int i = ;i<Width;i++)
P[i] = new float [Width]; for(int i = ; i<; i++)
{
for(int j = ; j<; j++)
{
M[i][j] = j;
N[i][j] = j;
}
}
MatrixMulOnHost(M,N,P,Width); for(int i = ; i<; i++)
{
for(int j = ; j<; j++)
{
cout<<P[i][j]<<" ";
}
cout<<endl;
} return ;
}
运行结果比较
CUDA线程的更多相关文章
- CUDA学习笔记(二)——CUDA线程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5b.html 一个grid中的所有线程执行相同的内核函数,通过坐标进行区分.这些线程有两级的坐标,bl ...
- GPU(CUDA)学习日记(十一)------ 深入理解CUDA线程层次以及关于设置线程数的思考
GPU线程以网格(grid)的方式组织,而每个网格中又包含若干个线程块,在G80/GT200系列中,每一个线程块最多可包含512个线程,Fermi架构中每个线程块支持高达1536个线程.同一线程块中的 ...
- 最优的cuda线程配置
1 每个SM上面失少要有192个激活线程,寄存器写后读的数据依赖才能被掩盖 2 将 寄存器 的bank冲突降到最低,应尽量使每个block含有的线程数是64的倍数 3 block的数量应设置得 ...
- CUDA线程协作之共享存储器“__shared__”&&“__syncthreads()”
在GPU并行编程中,一般情况下,各个处理器都需要了解其他处理器的执行状态,在各个并行副本之间进行通信和协作,这涉及到不同线程间的通信机制和并行执行线程的同步机制. 共享内存"__share_ ...
- 【并行计算-CUDA开发】CUDA线程、线程块、线程束、流多处理器、流处理器、网格概念的深入理解
GPU的硬件结构,也不是具体的硬件结构,就是与CUDA相关的几个概念:thread,block,grid,warp,sp,sm. sp: 最基本的处理单元,streaming processor 最 ...
- CUDA线程、线程块、线程束、流多处理器、流处理器、网格概念的深入理解
一.与CUDA相关的几个概念:thread,block,grid,warp,sp,sm. sp: 最基本的处理单元,streaming processor 最后具体的指令和任务都是在sp上处理的.G ...
- cuda线程/线程块索引小结
内建变量: threadIdx(.x/.y/.z代表几维索引):线程所在block中各个维度上的线程号 blockIdx(.x/.y/.z代表几维索引):块所在grid中各个维度上的块号 blockD ...
- CUDA ---- 线程配置
前言 线程的组织形式对程序的性能影响是至关重要的,本篇博文主要以下面一种情况来介绍线程组织形式: 2D grid 2D block 线程索引 矩阵在memory中是row-major线性存储的: 在k ...
- CUDA并行计算 | 线程模型与内存模型
文章目录 前言 CUDA线程模型(如何组织线程) CUDA内存模型(了解不同内存优缺点,合理使用) 前言 CUDA(Compute Unified Device Architecture)是显卡厂 ...
随机推荐
- Redis缓存如何保证一致性
为什么使用Redis做缓存 MySQL缺点 单机连接数目有限 对数据进行写速度慢 Redis优点 内存操作数据速度快 IO复用,速度快 单线程模型,避免线程切换带来的开销,速度快 一致性问题 读数据的 ...
- linux环境weblogic的安装及新建域
环境:inux 64位,jdk 64位, jdk 安装用户应使用weblogic.若使用其他用户安装,须将jdk安装目录整体授权给wblogic用户 安装包:wls1036_dev.zi ...
- 【转载】Sqlserver存储过程中使用Select和Set给变量赋值
Sqlserver存储过程是时常使用到的一个数据库对象,在存储过程中会使用到Declare来定义存储过程变量,定义的存储过程变量可以通过Set或者Select等关键字方法来进行赋值操作,使用Set对存 ...
- HTML的发展历史
HTML是Web统一语言,这些容纳在尖括号里的简单标签,构成了如今的Web,1991年,Tim Berners-Lee编写了一份叫做“HTML标签”的文档,里面包含了大约20个用来标记网页的HTML标 ...
- ABAP-会计凭证替代字段GB01设置
1.GB01表字段设置 SM30:VWTYGB01 找到需要替代的字段,设置bexclude勾选为空 2.运行程序 RGUGBR00 激活
- HibernateTemplate的queryForList(sql)用法
转自:https://blog.csdn.net/huanghaijin/article/details/7763580 List<User> list = jdbcTemplate.q ...
- @Transactional 同一个类中无事务方法a()内部调用有事务方法b()的问题
https://blog.csdn.net/u010235716/article/details/90171802 1. 事务的4种特性 序号 参数 含义1 原子性(Atomicity) ...
- springboot2集成swagger2出现guava包下的FluentIterable.append方法找不到
加入依赖 <!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> < ...
- springboot系列(九)springboot使用druid数据源
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0.DBCP.PROXOOL等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB ...
- P2882 [USACO07MAR]Face The Right Way [贪心+模拟]
题目描述 N头牛排成一列1<=N<=5000.每头牛或者向前或者向后.为了让所有牛都 面向前方,农夫每次可以将K头连续的牛转向1<=K<=N,求操作的最少 次数M和对应的最小K ...