深入理解hadoop之机架感知
深入理解hadoop之机架感知
机架感知
hadoop的replication为3,机架感知的策略为:
第一个block副本放在和client所在的datanode里(如果client不在集群范围内,则这第一个node是随机选取的)。第二个副本放置在与第一个节点不同的机架中的datanode中(随机选择)。第三个副本放置在与第二个副本所在节点同一机架的另一个节点上。如果还有更多的副本就随机放在集群的datanode里,这样如果第一个block副本的数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务 。但是,hadoop对机架的感知并非是真正智能感知的,而是需要人为的告知hadoop哪台机器属于哪个rack,这样在hadoop的namenode启动初始化时,会将这些机器与rack的对应信息保存在内存中,作为写块操作时分配datanode列表时选择datanode的依据。
要将hadoop机架感知的功能启用,配置非常简单,在namenode所在机器的hadoop-site.xml配置文件中配置一个选项:
<property>
<name>topology.script.file.name</name>
<value>/path/to/RackAware.py</value>
</property>
这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架,保存到内存的一个map中。
网络拓扑
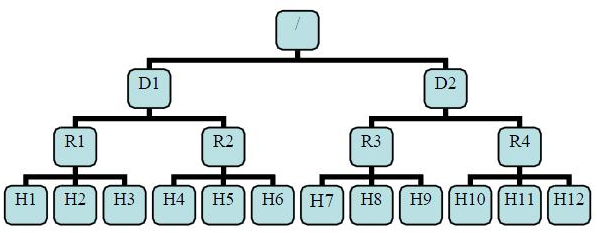
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
深入理解hadoop之机架感知的更多相关文章
- hadoop配置机架感知
接着上一篇来说.上篇说了hadoop网络拓扑的构成及其相应的网络位置转换方式,本篇主要讲通过两种方式来配置机架感知.一种是通过配置一个脚本来进行映射:另一种是通过实现DNSToSwitchMappin ...
- 【原创】Hadoop机架感知对性能调优的理解
Hadoop作为大数据处理的典型平台,在海量数据处理过程中,其主要限制因素是节点之间的数据传输速率.因为集群的带宽有限,而有限的带宽资源却承担着大量的刚性带宽需求,例如Shuffle阶段的数据传输不可 ...
- 【转载】Hadoop机架感知
转载自http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机 ...
- hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- hadoop之 hadoop 机架感知
1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份.这样如果本地数据损坏,节点可以从同一机 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- 【Hadoop】Hadoop 机架感知配置、原理
Hadoop机架感知 1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份, 同机架内其它某一节点上一份,不同机架的某一节点上一份. 这样如果本地 ...
- Hadoop--Hadoop的机架感知
Hadoop的机架感知 Hadoop有一个“机架感知”特性.管理员可以手工定义每个slave数据节点的机架号.为什么要做这么麻烦的事情?有两个原因:防止数据丢失和提高网络性能. 为了防止数据丢 ...
- hdfs 机架感知
一.背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高 ...
随机推荐
- PostgreSQL10配置远程连接
PostgreSQL10配置远程连接 psql --version centos7.3中 1.开启相应的防火墙端口,允许端口5432 2.访问权限配置/etc/postgresql/10/main/下 ...
- WPF 快速制作可拖拽的对象和窗体
引用类库: 1.Microsoft.Expression.Interactions 2.System.Windows.Interactivity <Window x:Class="Wp ...
- Tomcat 8.5 配置 域名绑定
1.修改Tomcat的Server.xml两处地方即可: a) b)
- [Hibernate]知识点
本笔记只介绍注解的方法 一.准备工作: a.添加三个pojo类: Product: package pojo; import javax.persistence.*; import java.util ...
- linux 基础 VIM 编辑器
- linux常用、常见错误
1.md5加密使用 oppnssl md5 加密字符串的方法 [root@lab3 ~]# openssl //在终端中输入openssl后回车. OpenSSL> md5 //输入md5后回车 ...
- Dapper 多表(三表以上)查询小技巧
在使用Dappr做查询的时候遇到多表查询,之前多是两张表,现在出现三张表或者更多.两表的时候使用splitOn进行分割,splitOn的默认值是Id.在我建库的时候,主键ID并不都是这个名字.当出现三 ...
- mybatis-generator自动生成代码时,只生成insert方法
今天使用mybatis-generator自动生成代码时,发现只能生成insert方法, 以前所有的方法都是可以生成的,查看网上解决办法和检查数据库表结构后, 发现2种可以解决的办法: 1.修改myb ...
- Matlab中的eig函数和Opecv中eigen()函数的区别
奇异值分解的理论参见下面的链接 http://www.cnblogs.com/pinard/p/6251584.html https://blog.csdn.net/shenziheng1/artic ...
- Python爬虫学习==>第一章:Python3+Pip环境配置
前置操作 软件名:anaconda 版本:Anaconda3-5.0.1-Windows-x86_64清华镜像 下载链接:https://mirrors.tuna.tsinghua.edu.cn/ ...