深入理解hadoop之机架感知
深入理解hadoop之机架感知
机架感知
hadoop的replication为3,机架感知的策略为:
第一个block副本放在和client所在的datanode里(如果client不在集群范围内,则这第一个node是随机选取的)。第二个副本放置在与第一个节点不同的机架中的datanode中(随机选择)。第三个副本放置在与第二个副本所在节点同一机架的另一个节点上。如果还有更多的副本就随机放在集群的datanode里,这样如果第一个block副本的数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务 。但是,hadoop对机架的感知并非是真正智能感知的,而是需要人为的告知hadoop哪台机器属于哪个rack,这样在hadoop的namenode启动初始化时,会将这些机器与rack的对应信息保存在内存中,作为写块操作时分配datanode列表时选择datanode的依据。
要将hadoop机架感知的功能启用,配置非常简单,在namenode所在机器的hadoop-site.xml配置文件中配置一个选项:
<property>
<name>topology.script.file.name</name>
<value>/path/to/RackAware.py</value>
</property>
这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架,保存到内存的一个map中。
网络拓扑
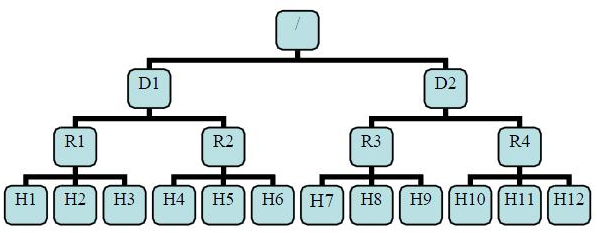
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
深入理解hadoop之机架感知的更多相关文章
- hadoop配置机架感知
接着上一篇来说.上篇说了hadoop网络拓扑的构成及其相应的网络位置转换方式,本篇主要讲通过两种方式来配置机架感知.一种是通过配置一个脚本来进行映射:另一种是通过实现DNSToSwitchMappin ...
- 【原创】Hadoop机架感知对性能调优的理解
Hadoop作为大数据处理的典型平台,在海量数据处理过程中,其主要限制因素是节点之间的数据传输速率.因为集群的带宽有限,而有限的带宽资源却承担着大量的刚性带宽需求,例如Shuffle阶段的数据传输不可 ...
- 【转载】Hadoop机架感知
转载自http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机 ...
- hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- hadoop之 hadoop 机架感知
1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份.这样如果本地数据损坏,节点可以从同一机 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- 【Hadoop】Hadoop 机架感知配置、原理
Hadoop机架感知 1.背景 Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份, 同机架内其它某一节点上一份,不同机架的某一节点上一份. 这样如果本地 ...
- Hadoop--Hadoop的机架感知
Hadoop的机架感知 Hadoop有一个“机架感知”特性.管理员可以手工定义每个slave数据节点的机架号.为什么要做这么麻烦的事情?有两个原因:防止数据丢失和提高网络性能. 为了防止数据丢 ...
- hdfs 机架感知
一.背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高 ...
随机推荐
- LeetCode 230. 二叉搜索树中第K小的元素(Kth Smallest Element in a BST)
题目描述 给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素. 说明:你可以假设 k 总是有效的,1 ≤ k ≤ 二叉搜索树元素个数. 示例 1: 输入: roo ...
- FScapture录屏后导致麦克风无声问题
- Nginx服务应用
虚拟主机 基于域名的虚拟主机 所谓基于域名的虚拟主机,意思就是通过不同的域名区分不同的虚拟主机,基于域名的虚拟主机是企业应用最广的虚拟主机类型,几乎所有对外提供服务的网站都是使用基于域名的虚拟主机 基 ...
- GitHub-Microsoft:DotNet
ylbtech-GitHub-Microsoft:DotNet 1.返回顶部 · · wcf This repo contains the client-oriented WCF libraries ...
- 使用Statement执行DML和DQL语句
import com.loaderman.util.JdbcUtil; import java.sql.Connection; import java.sql.DriverManager; impor ...
- ORA-00904: "B"."METHOD": 标识符无效,00904. 00000 - "%s: invalid identifier"
1 SELECT COUNT(1) FROM (SELECT a.id AS "id", a.district AS "district", a.company ...
- SQL Server 等待统计信息基线收集
背景 我们随时监控每个服务器不同时间段的wait statistics ,可以根据监控信息大概判断什么时候开始出现异常,相当于一个wait statistics基线收集,还可以具体分析占比高的等待类型 ...
- Python浅拷贝与深拷贝(可变对象与不可变对象)
第一次遇到深拷贝和浅拷贝的问题是用python在一个for循环中对一个list赋值,使用的语句是 a = b 这个b会不断带入循环,每次计算得到,最后发现list乱七八糟的,后来才发现,python中 ...
- ubuntu go 开发环境搭建
访问:https://golang.org/dl/ 下载 go1.12.4.linux-amd64.tar.gz wget https://dl.google.com/go/go1.12.4.linu ...
- Java ——类型转换 向args传递参数
本节重点思维导图 自动类型转换 整型.实型(常量).字符型数据可以混合运算 运算中,不同类型的数据先转化为同一类型,然后进行运算 转换从低级到高级 低 ----------------------- ...