《机器学习实战(基于scikit-learn和TensorFlow)》第七章内容学习心得
本章主要讲述了“集成学习”和“随机森林”两个方面。
重点关注:bagging/pasting、boosting、stacking三个方法。
首先,提出一个思想,如果想提升预测的准确率,一个很好的方法就是用集成的方法。让多种预测器尽可能相互独立,使用不同的算法进行训练。最后以预测器中的预测结果的多数作为最终结果或者将平均概率最高的结果作为最后的结果。
还有没有其他的方法呢,有的。
- Bagging/Pasting方法:每个预测器使用的算法相同,但是在不同的训练集随机子集上进行训练,采样时将样本放回就是bagging方法,采样时样本不放回就是pasting方法。下图就是一个pasting/bagging训练集采样和训练。
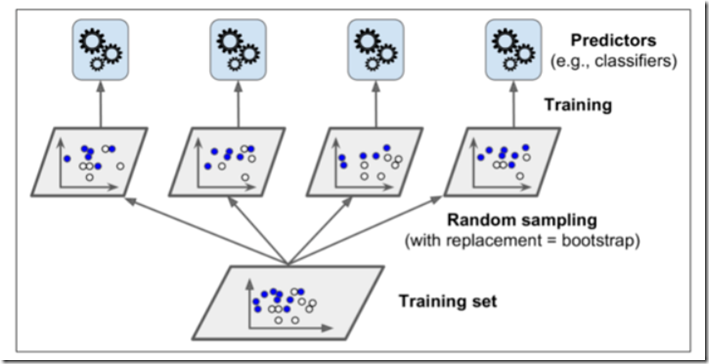
当训练完成后,我们的集成函数一般就采用统计的方法即可。显然,我们可以得出这样的结论,就是每个预测器单独的偏差都高于在原始训练集上的偏差,但是通过聚合集成,我们将会降低偏差与方差,得出更精准的答案。决策树一般采用上述方法进行训练。当然,随机森林也可以采用上述方法。
sklearn中有相关bagging与pasting的工具包,这里不再做赘述,请自行查阅相关文档。提示:使用BaggingClassifier类进行调用。
- Boosting方法:是指几个弱学习器合成一个强学习器的任意的集成方式。目前最流行的方法就是AdaBoost(自适应提升法)和梯度提升法。
Adaboost方法,思想就是更多地关注前序拟合不足地训练实例。从而使得新地预测器不断地越来越专注于难缠的问题。可以发现,该方法是一种存在时序关系的方法,我们必须要得到前者地训练的情况,然后对数据中对前者状态的分类器拟合不好的数据再次进行训练,然后循环往复。故此,可以得出,这个方法不能并行计算,在拓展方面,不如bagging、boosting。
相关推导,请看Scorpio.Lu博主的文章:https://www.cnblogs.com/ScorpioLu/p/8295990.html
梯度提升法:该方法是逐步在集成中添加预测器,每个都对其前序做出改正,让新的预测器对前一个的预测器的残差进行拟合。具体的推导,请见刘建平Pinard博主的文章:https://www.cnblogs.com/pinard/p/6140514.html
- Stacking方法:训练一个模型执行聚合集成所有预测器的预测,然后以预测器的预测作为输入再进行最后的预测。训练混合器的常用方式就是使用留存集。首先,将训练集分为两个子集,第一个子集训练第一层的预测器。然后,用第一层的预测器在第二个子集上进行预测。然后将在第二个子集上预测的值作为输入特征,创建一个新的训练集,保留目标值。在新的训练集上训练混合器,让其学习根据第一层的预测来预测目标值。通过该方法,可以训练多种不同的混合器。
《机器学习实战(基于scikit-learn和TensorFlow)》第七章内容学习心得的更多相关文章
- 《机器学习实战(基于scikit-learn和TensorFlow)》第六章内容学习心得
本章讲决策树 决策树,一种多功能且强大的机器学习算法.它实现了分类和回归任务,甚至多输出任务. 决策树的组合就是随机森林. 本章的代码部分不做说明,具体请到我的GitHub上自行获取. 决策树的每个节 ...
- 《机器学习实战(基于scikit-learn和TensorFlow)》第五章内容学习心得
本章在讲支持向量机(Support Vector Machine). 支持向量机,一个功能强大的机器学习模型,能够执行线性或非线性数据的分类.回归甚至异常值检测的任务.它适用于中小型数据集的分类. 线 ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Vue实战狗尾草博客后台管理系统第七章
Vue实战狗尾草博客后台管理平台第七章 本章内容为借助模块化来阐述Vuex的进阶使用. 在复杂项目的架构中,对于数据的处理是一个非常头疼的问题.处理不当,不仅对维护增加相当的工作负担,也给开发增加巨大 ...
- 机器学习实战:基于Scikit-Learn和TensorFlow 读书笔记 第6章 决策树
数据挖掘作业,要实现决策树,现记录学习过程 win10系统,Python 3.7.0 构建一个决策树,在鸢尾花数据集上训练一个DecisionTreeClassifier: from sklearn. ...
- 机器学习实战:基于Scikit-Learn和TensorFlow 第5章 支持向量机 学习笔记(硬间隔)
数据挖掘作业,需要实现支持向量机进行分类,记录学习记录 环境:win10,Python 3.7.0 SVM的基本思想:在类别之间拟合可能的最宽的间距,也叫作最大间隔分类 书上提供的源代码绘制了两个图, ...
- 集成算法(chapter 7 - Hands on machine learning with scikit learn and tensorflow)
Voting classifier 多种分类器分别训练,然后分别对输入(新数据)预测/分类,各个分类器的结果视为投票,投出最终结果: 训练: 投票: 为什么三个臭皮匠顶一个诸葛亮.通过大数定律直观地解 ...
随机推荐
- nginx限流&健康检查
Nginx原生限流模块: ngx_http_limit_conn_module模块 根据前端请求域名或ip生成一个key,对于每个key对应的网络连接数进行限制. 配置如下: http模块 ser ...
- jvm虚拟机笔记<六> 运行期优化
这节我们总结一下JVM运行期的优化问题. https://www.cnblogs.com/zhouyuqin/p/5224573.html JVM运行期优化 即时编译器(JIT) 编译对象与触发条件 ...
- 添加Mybatis
- 51 Nod 1449 砝码称重
1449 砝码称重 题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 收藏 关注 现在有好多种砝码,他们的重量是 w0,w1, ...
- 我爱网络流之最大流Dinic
直接上大佬博客: Dinic算法详解及实现来自小菲进修中 Dinic算法(研究总结,网络流)来自SYCstudio 模板步骤: 第一步,先bfs把图划分成分成分层图网络 第二步,dfs多次找增广路 当 ...
- [笔记]C++拷贝构造和移动构造
一.拷贝构造 如果一个构造函数的第一个参数是自身类类型的引用,且任何额外参数都没有默认值,则此构造函数是拷贝构造函数.(<C++Primer,第五版>) class Foo { publi ...
- UITableView动态改变Cell高度
demo下载地址:https://github.com/smileyborg/TableViewCellWithAutoLayout 版权声明:本文为博主原创文章,未经博主允许不得转载.
- eclipse异常:Exception in thread ""http-bio-8080"-exec-5" java.lang.OutOfMemoryError: PermGen space
用eclipse运行项目,最烦的就是非代码错误.现在这个异常信息,表示的是tomcat启动内存溢出.试过的最简单的办法就是eclipse->project->clean->clean ...
- 图解golang内存分配机制 (转)
一般程序的内存分配 在讲Golang的内存分配之前,让我们先来看看一般程序的内存分布情况: 以上是程序内存的逻辑分类情况. 我们再来看看一般程序的内存的真实(真实逻辑)图: Go的内存分配核心思想 G ...
- leetcode题目234.回文链表(快慢指针+辅助空间-简单)
题目描述: 请判断一个链表是否为回文链表. 示例 1: 输入: 1->2 输出: false 示例 2: 输入: 1->2->2->1 输出: true 进阶: 你能否用 O( ...