100天搞定机器学习|Day4-6 逻辑回归
逻辑回归avik-jain介绍的不是特别详细,下面再唠叨一遍这个算法。
1.模型
在分类问题中,比如判断邮件是否为垃圾邮件,判断肿瘤是否为阳性,目标变量是离散的,只有两种取值,通常会编码为0和1。假设我们有一个特征X,画出散点图,结果如下所示。这时候如果我们用线性回归去拟合一条直线:hθ(X) = θ0+θ1X,若Y≥0.5则判断为1,否则为0。这样我们也可以构建出一个模型去进行分类,但是会存在很多的缺点,比如稳健性差、准确率低。而逻辑回归对于这样的问题会更加合适。
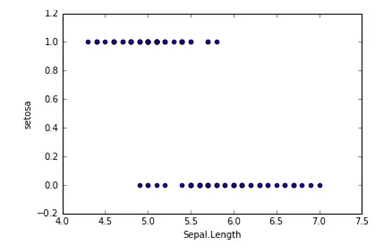
逻辑回归假设函数如下,它对θTX作了一个函数g变换,映射至0到1的范围之内,而函数g称为sigmoid function或者logistic function,函数图像如下图所示。当我们输入特征,得到的hθ(x)其实是这个样本属于1这个分类的概率值。也就是说,逻辑回归是用来得到样本属于某个分类的概率。
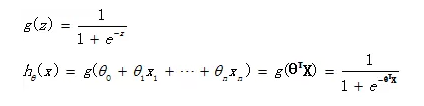

2.评价
回想起之前线性回归中所用到的损失函数:
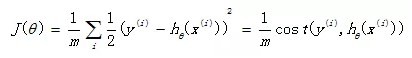
如果在逻辑回归中也运用这种损失函数,得到的函数J是一个非凸函数,存在多个局部最小值,很难进行求解,因此需要换一个cost函数。重新定义个cost函数如下:
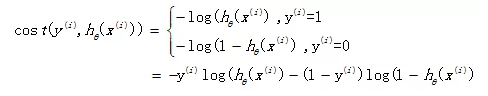
当实际样本属于1类别时,如果预测概率也为1,那么损失为0,预测正确。相反,如果预测为0,那么损失将是无穷大。这样构造的损失函数是合理的,并且它还是一个凸函数,十分方便求得参数θ,使得损失函数J达到最小。
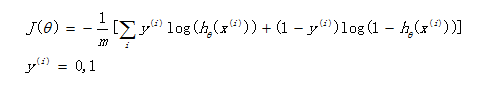
3.优化
我们已经定义好了损失函数J(θ),接下来的任务就是求出参数θ。我们的目标很明确,就是找到一组θ,使得我们的损失函数J(θ)最小。最常用的求解方法有两种:批量梯度下降法(batch gradient descent), 牛顿迭代方法((Newton's method)。两种方法都是通过迭代求得的数值解,但是牛顿迭代方法的收敛速度更加快。
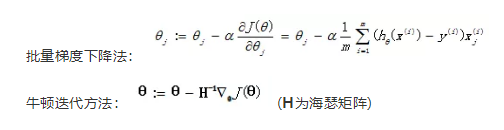
“
实验-分割线
”
第0步:数据预览
数据集链接:https://pan.baidu.com/s/1TkUe-7-Q_jX5IT2qrXzeuA
提取码:hrrm
该数据集包含了社交网络中用户的信息。这些信息涉及用户ID,性别,年龄以及预估薪资。一家汽车公司刚刚推出了他们新型的豪华SUV,我们尝试预测哪些用户会购买这种全新SUV。并且在最后一列用来表示用户是否购买。我们将建立一种模型来预测用户是否购买这种SUV,该模型基于两个变量,分别是年龄和预计薪资。因此我们的特征矩阵将是这两列。我们尝试寻找用户年龄与预估薪资之间的某种相关性,以及他是否购买SUV的决定。

步骤1 | 数据预处理
导入库
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd
导入数据集
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
Y = dataset.iloc[:,4].values
将数据集分成训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.25, random_state = 0)
特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
步骤2 | 逻辑回归模型
该项工作的库将会是一个线性模型库,之所以被称为线性是因为逻辑回归是一个线性分类器,这意味着我们在二维空间中,我们两类用户(购买和不购买)将被一条直线分割。然后导入逻辑回归类。下一步我们将创建该类的对象,它将作为我们训练集的分类器。
将逻辑回归应用于训练集
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
步骤3 | 预测
预测测试集结果
y_pred = classifier.predict(X_test)
步骤4 | 评估预测
我们预测了测试集。 现在我们将评估逻辑回归模型是否正确的学习和理解。因此这个混淆矩阵将包含我们模型的正确和错误的预测。
生成混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
可视化
from matplotlib.colors import ListedColormap
X_set,y_set=X_train,y_train
X1,X2=np. meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01),
np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())for i,j in enumerate(np. unique(y_set)):
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1], c = ListedColormap(('red', 'green'))(i), label=j)
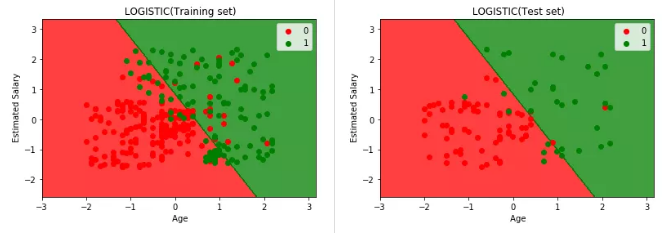
plt. title(' LOGISTIC(Training set)')
plt. xlabel(' Age')
plt. ylabel(' Estimated Salary')
plt. legend()
plt. show()
X_set,y_set=X_test,y_test
X1,X2=np. meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01),
np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())for i,j in enumerate(np. unique(y_set)):
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1], c = ListedColormap(('red', 'green'))(i), label=j)
plt. title(' LOGISTIC(Test set)')
plt. xlabel(' Age')
plt. ylabel(' Estimated Salary')
plt. legend()
plt. show()

100天搞定机器学习|Day4-6 逻辑回归的更多相关文章
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day17-18 神奇的逻辑回归
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day11 实现KNN
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day9-12 支持向量机
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- 100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day21 Beautiful Soup
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day22 机器为什么能学习?
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day33-34 随机森林
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day35 深度学习之神经网络的结构
100天搞定机器学习|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习 ...
随机推荐
- P5346 【XR-1】柯南家族(后缀数组+主席树)
题目 P5346 [XR-1]柯南家族 做法 聪明性是具有传递性的,且排列是固定的 那么先预处理出每个点的名次,用主席树维护\(k\)大值 一眼平衡树,遍历的同时插入\(O(log^2n)\),总时间 ...
- [TJOI2019]大中锋的游乐场——最短路+DP
题目链接: [TJOI2019]大中锋的游乐场 题目本质要求的还是最短路,但因为有第二维权值(汽水看成$+1$,汉堡看成$-1$)的限制,我们在最短路的基础上加上一维$f[i][j]$表示到达$i$节 ...
- 纯JS 10分钟 实现图片懒惰加载
知识点: 1:h5 新增选择器 document.querySelectorAll 2:JS 经典,防抖 3:距离判断:getBoundingClientRect 思路:通过浏览器滚动事件, 判断 ...
- js中的一些隐式转换和总结
js中的不同的数据类型之间的比较转换规则如下: 1. 对象和布尔值比较 对象和布尔值进行比较时,对象先转换为字符串,然后再转换为数字,布尔值直接转换为数字 [] == true; //false [] ...
- selinux 开启和关闭
对于新手来说,linux的selinux困扰了一大批学员,开启后,导致文件权限修改不了等问题,下面就是关闭设置setlinux的方法 查看SELinux状态: 1./usr/sbin/sestatus ...
- Vue的axios如何全局注册
最近用 Vue 写项目的时候,用到 axios ,因为 axios 不能用 Vue.use() ,所以在每个 .vue 文件中使用 axios 时就需要 import , .vue 文件少的话还好说, ...
- 目录:JAVA
收藏: Java:类与继承
- PHP 美化输出数组
var_export — 输出或返回一个变量的字符串表示 此函数返回关于传递给该函数的变量的结构信息,它和 var_dump() 类似,不同的是其返回的表示是合法的 PHP 代码. 您可以通过将函数的 ...
- Web登录验证之 Shiro
1.需要用到的shiro相关包 <!-- shiro begin --> <dependency> <groupId>org.apache.shiro</gr ...
- LeetCode_101. Symmetric Tree
101. Symmetric Tree Easy Given a binary tree, check whether it is a mirror of itself (ie, symmetric ...