【MapReduce】三、MapReduce运行机制
通过前面对map端、reduce端以及整个shuffle端工作流程的介绍,我们已经了解了MapReduce的并行运算模型,基本可以使用MapReduce进行编程,那么MapRecude究竟是如何执行的,从map到shuffle,再到reduce的这一套完整的计算过程是如何调度的呢?这就是MapReduce的作业运行机制。
对于一个MapReduce作业,有两种方法来提交使其运行,一个是Job对象的waitForCompletion()方法,用于提交以前没有提交过的作业,并等待它的完成;还有一个是Job对象的submit()方法,这个方法调用封装了大量的处理细节。
在整个MapReduce作业的运行过程中,有5个独立的实体:
- 客户端。client负责提交MapReduce作业。
- YARN资源管理器。它负责协调集群上计算机资源的分配。
- YARN节点管理器。它负责启动和监视集群中机器上的计算容器(Container)。
- MapReduce的application master。它负责协调运行MapReduce作业的所有任务,它和MapReduce任务都在容器中运行,这些容器由资源管理器分配并且由节点管理器进行管理。
- 分布式文件系统(一般是HDFS)。它主要用于与其他实体之间共享作业文件。
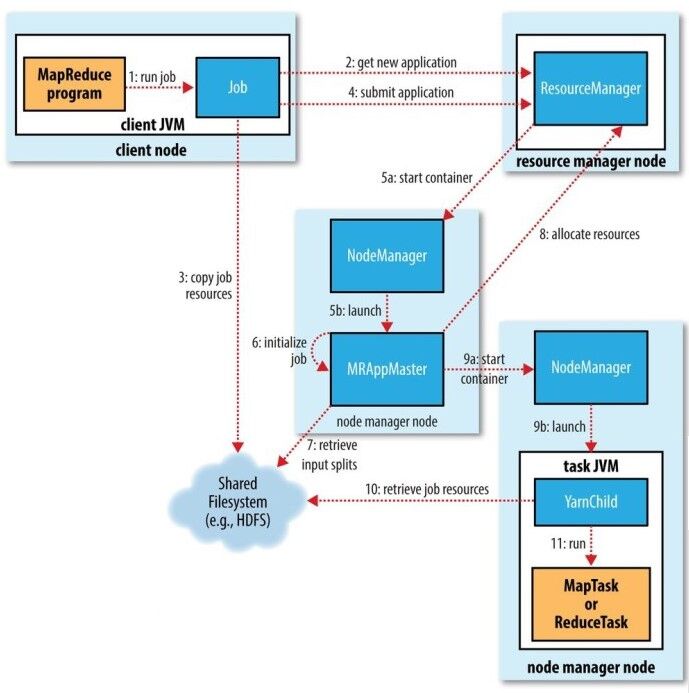
1、作业的提交
Job的submit()的方法会创建一个内部的JobSummitter实例,并且调用其submitJobInternal()方法提交作业(图中的步骤1),然后通过waitForCompletion()每秒轮询作业的进度,如果发现自上次报告后有改变,就把进度报告到控制台。最后作业完成后,如果成功就显示作业计数器,如果失败,则将错误信息输出到控制台。
具体来说,整个作业的提交过程如下所示:
- 向资源管理器请求一个新的应用ID,也就是MapReduce的作业ID(步骤2)。
- 检查作业的输出说明。例如,如果没有指定输出目录或者输出目录已经存在,作业就不提交,返回错误。
- 计算作业的输入分片。如果分片无法计算,比如输入路径不存在,作业就不提交,返回错误。
- 将运行作业所需要的资源(包括作业JAR文件、配置文件、计算到的输入分片)复制到一个以作业ID命名的共享文件系统中(步骤3)。
- 通过调用资源管理器的submitApplication()方法提交作业(步骤4)。
2、作业的初始化
当资源管理器收到调用submitApplication()方法的消息后,便将请求传递给YARN调度器,调度器分配一个容器,然后资源管理器在节点管理器的管理下载容器中启动application master进程(步骤5a和5b)。
关于application master,它是一个Java应用程序,主类是MRAppMaster。它通过创建多个簿记对象以保持对作业进度的跟踪(步骤6),并接受来自任务的进度和完成报告。然后,它接受来自HDFS的、在客户端计算好的输入分片(步骤7),并为每一个分片创建一个map任务,同时也创建对应的reduce任务(个数由setNumReduceTasks()方法指定)。任务ID在此时分配。
application master还有一个任务就是必须决定如何运行构成MapReduce作业的各个任务。这里有一个特殊的情况就是:如果作业很小(少于10个mapper并且只有一个reducer,而且输入大小小于一个HDFS块的大小,三个条件都满组就是小作业),就选择和自己在同一个JVM上运行。当application master判断在新的容器中分配和运行任务的开销大于并行运行开销时就会出现这种情况,这样的作业称为uberized,也叫Uber任务。
那如果作业很大怎么办呢?这就涉及到下一步,需要进行任务的分配。
初始化的最后一步是application master调用setupJob()方法设置OutputCommitter,其中FileOutputCommitter为默认值,表示将建立作业的最终输出目录及任务输出的临时工作空间。
3、任务的分配
正常情况下,MapReduce所面向的是大数据,应当是一个大作业,此时该作业就不适合作为Uber任务运行,那么application master就会为该作业中所有的map任务和reduce任务想资源管理器请求容器(步骤8)。
在请求容器时,Map任务请求的优先级高于Reduce任务,因为Map任务必须首先完成,知道有5%的map任务已经完成时,为reduce任务发起的容器请求才会发出。这个请求也会为每个任务指定需要的内存和CPU数,默认情况下每个任务都会分配到1024MB的内存和一个虚拟的内核。
这里还有一点需要注意的是:reduce任务可以分配到集群的任意位置上去,但是map任务有这数据本地化的局限,因此理想情况下mao任务可以被分配到在分片驻留的那个节点上去运行。有时候可能无法做到完全本地化,那么有可能成为机架本地化或者从别的机架获取数据。
4、任务的执行
一旦资源管理器的调度器为任务分配了一个特定节点上的容器,application master就可以通过与该节点上的节点管理器来通信,进而启动容器执行任务(步骤9a和9b)。
任务由主类为YarnChild的一个java应用程序执行,在运行之前,首先将任务需要的资源本地化(步骤10),包括作业的配置、JAR文件和所有来自分布式缓存的文件。然后开始运行(步骤11)。
除了执行相应的map和reduce计算逻辑外,每个任务还可以执行搭建和提交的动作,和任务本身在同一个JVM运行,这两个动作由作业的OutputCommiter确定,对于默认的文件作业,提交可以将任务输出由临时位置搬到最终位置。
5、进度和状态的更新
MapReduce作业是长时间运行的批量作业,运行时间为几个小时是很正常的,所以在作业执行期间,用户需要得到一些反馈信息。每个作业和它的任务都有一个状态,包括:作业或任务的状态(运行中、成功、失败)、map和reduce的进度、作业计数器的值、状态消息或描述。
所谓进度,就是任务完成的百分比。对于Map任务,就是已处理的的输入所占的比例;而对于reduce任务比较复杂,和reduce端的三个阶段相对应,如果任务已经处理了reducer输入数据的一般,那么进度是5/6,因为已经完成了copy和merge(每个占1/3),且又完成了reduce的1/2,所以总进度是5/6。
除了进度,任务还有很多计数器,可以用于对任务运行过程中的各个事件进行统计。
当map任务和reduce任务执行时,子进程和自己的父application master通过umbilical接口通信,每隔3秒,任务通过这个接口向自己的application master报告进度和状态,然后由application master形成一个汇聚视图。
而对于整个作业来说,客户端每秒轮询一次application master以获得最新状态,或者,客户端也可以通过Job的getStatus()方法获得一个JobStatus的实例,它包含了作业相关的状态信息。
6、作业的完成
当application master收到作业最后一个任务已完成的通知后,就知道作业已经完成,见赶作业状态设置为“成功”,然后,下一次Job轮询时,就知道了任务已经完成,就可以从waitForCompletion方法返回,相应的统计信息和计数值输出到控制台。
最后,application master和任务容器会清理该作业的工作状态,比如删除一些中间输出,OutputCommiter中的一个commitJob方法被调用,将作业信息存档,以便日后查询。
至此,一个完整的MapReduce作业就被成功的调度和执行成功了。
【MapReduce】三、MapReduce运行机制的更多相关文章
- MapReduce的核心运行机制
MapReduce的核心运行机制概述: 一个完整的 MapReduce 程序在分布式运行时有两类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.Yarnchild:负责 ...
- 大数据技术 - MapReduce 作业的运行机制
前几章我们介绍了 Hadoop 的 MapReduce 和 HDFS 两大组件,内容比较基础,看完后可以写简单的 MR 应用程序,也能够用命令行或 Java API 操作 HDFS.但要对 Hadoo ...
- Hadoop学习之路(十四)MapReduce的核心运行机制
概述 一个完整的 MapReduce 程序在分布式运行时有两类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.Yarnchild:负责 map 阶段的整个数据处理流程 3 ...
- 4、MapReduce思想、运行机制
MapReduce 离线计算框架 分而治之 input > map > shuffle > reduce > output 分布式并行的计算框架 将计算过程分为两个阶段,Map ...
- mapreduce (三) MapReduce实现倒排索引(二)
hadoop api http://hadoop.apache.org/docs/r1.0.4/api/org/apache/hadoop/mapreduce/Reducer.html 改变一下需求: ...
- 经典MapReduce作业和Yarn上MapReduce作业运行机制
一.经典MapReduce的作业运行机制 如下图是经典MapReduce作业的工作原理: 1.1 经典MapReduce作业的实体 经典MapReduce作业运行过程包含的实体: 客户端,提交MapR ...
- MapReduce(三)
MapReduce(三) MapReduce(三): 1.关于倒叙排序前10名 1)TreeMap根据key排序 2)TreeSet排序,传入一个对象,排序按照类中的compareTo方法排序 2.写 ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- MapReduce 运行机制
Hadoop中的MapReduce是一个使用简单的软件框架,基于它写出来的应用程序能够运行在由上千个机器组成的大型集群上,并且以一种可靠容错并行处理TB级别的数据集. 一个MapReduce作业(jo ...
随机推荐
- kafka的maxPollIntervalMs设置太小引发的惨案 (转)
本地启动kafka后,不断报一下信息: 表示本地consumer节点在不断的重新加入group,并且不断伴随着offset commit失败. 具体原因是因为ConsumerCoordinator没有 ...
- XMl特殊字符转换参考
参考链接:https://blog.csdn.net/goon_star/article/details/49636505 处理SVG Text元素不能正确显示特殊字符 特殊符号 命名实体 十进制编码 ...
- NTT 练习
一 . Rikka with Subset 题目: http://acm.hdu.edu.cn/showproblem.php?pid=5829 参考 https://blog.csdn.net/ ...
- cogs908. 校园网
908. 校园网 ★★ 输入文件:schlnet.in 输出文件:schlnet.out 简单对比时间限制:1 s 内存限制:128 MB USACO/schlnet(译 by Fel ...
- vscode编辑器
插件 Auto Close Tag 自动关闭标签 Auto Rename Tag 自动修改标签 Bracket Pair Colorizer 多层括号不同颜色显示 EditorConfig fo ...
- axios的post请求方式,怎么把参数直接加在URL后面,不用payload
export const delUser = (id) => { return axios.post("/user/remove", null, { params:{ id, ...
- vue + ts Vuex篇
Vuex对Typescript的支持,仍十分薄弱,官方库只是添加了一些.d.ts声明文件,并没有像vue 2.5这样内置支持. 第三方衍生库 vuex-typescript, vuex-ts-deco ...
- 识别C++编译器编译标准
cout << __cplusplus<<endl; C++03:__cplusplus = 199711L C++11:__cplusplus = 201103L
- Zookeeper执行原理的详细概述
文章作者:Holy Null,来源:http://holynull.leanote.com/post/Zookeeper,非常感谢作者提供如此优秀的原创文章,作者通过俩个月的努力将<Hadoop ...
- dom4j读写XML文档
dom4j 最常用最简单的用法(转) 要使用dom4j读写XML文档,需要先下载dom4j包,dom4j官方网站在 http://www.dom4j.org/目前最新dom4j包下载地址:http:/ ...