如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7
思路:
1、先选取你要爬取的电影
2、用vip解析工具解析,获取地址
3、写好脚本,下载片断
4、将片断利用电脑合成
需要的python模块:
##第一个模块不要安装,第二个模块需要安装
1、from multiprocessing import Pool
2、import requests
##模块安装方法
用windows命令行终端
pip install requests
一、先选取你要爬的电影,本例随便找了个VIP电影,复制地址
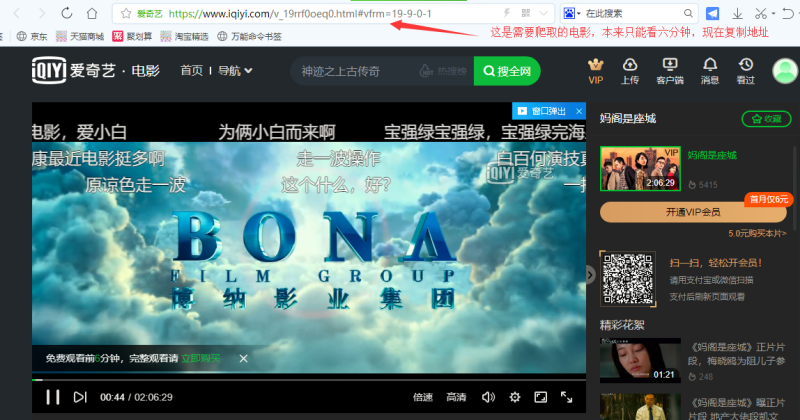
二、用vip解析工具解析,获取地址
(一)进行上网搜索,点击VIP解析
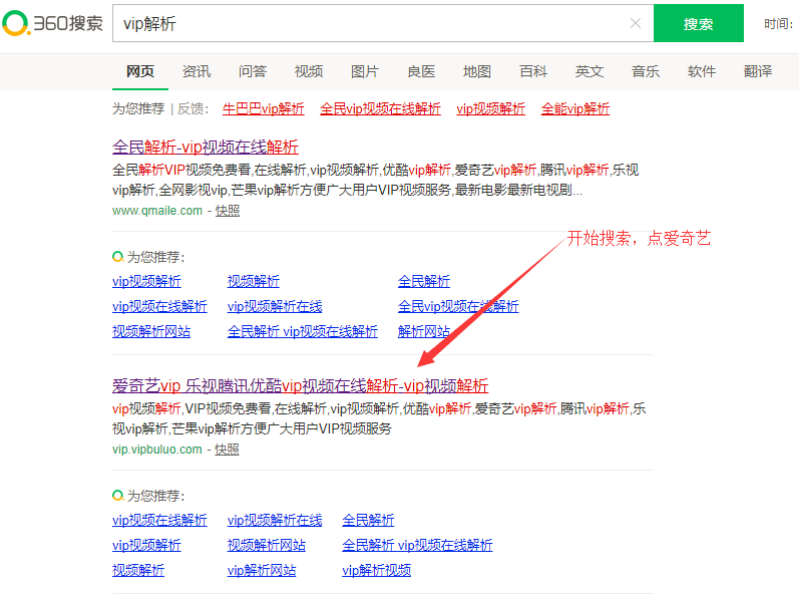
(二)、粘贴电影地址,点击播放

(三)、按下F12或者右击点检查,进入开发者工具界面,点击网络,复制地址
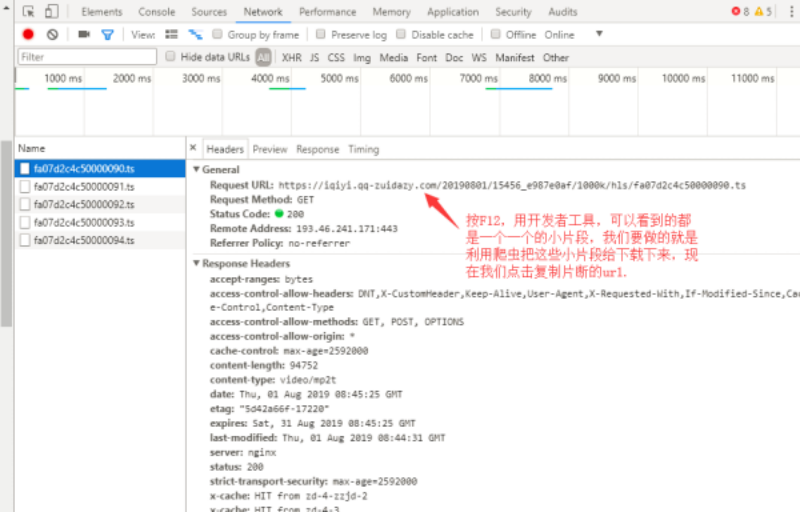
三、写好脚本,利用爬虫下载片断
##描述:该脚本目前适合下载爱奇艺,腾迅视频VIP视频
##作者:小刘
##电话:有事请写评论
##注意:只适全python爬虫的学习者,不适合专门去看电影的爱好者
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/20180114/ArVcZXQd/1000kb/hls/phJ51837151%03d.ts"%i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content) ##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,)) pool.close()
pool.join()
四、将片断利用电脑合成
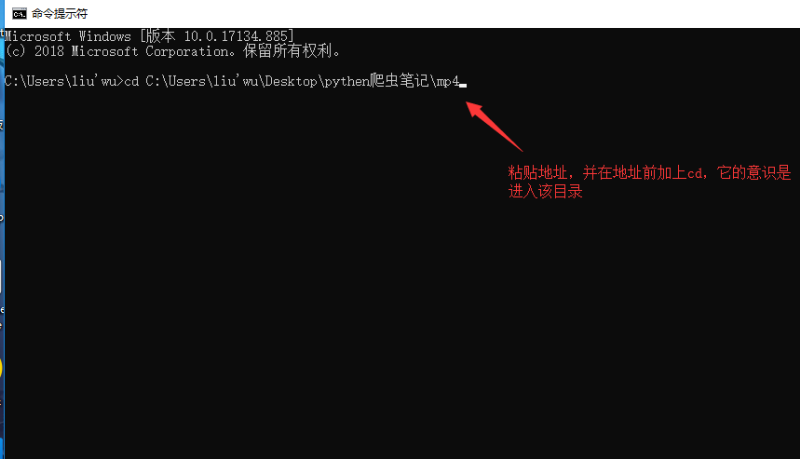
(一)、复制电影存放的路径

(二)、用进入windows命令行模式,粘贴地址
(三)、复制该目录下所有以*.ts结尾的文件,复制成一个文件

(四)、进行合并
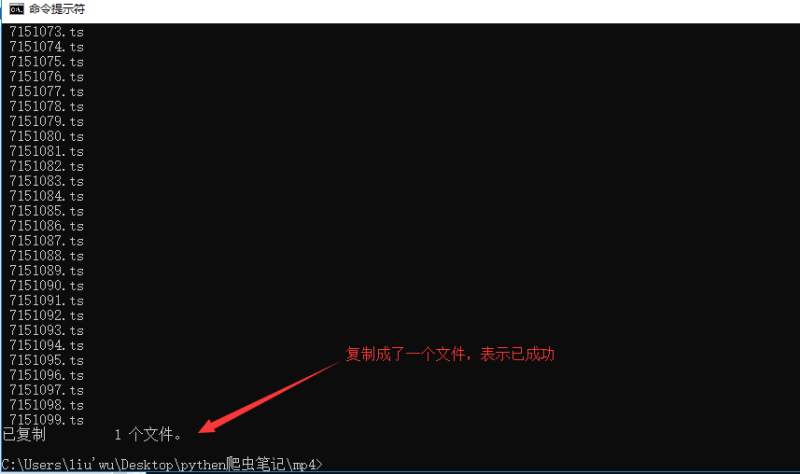
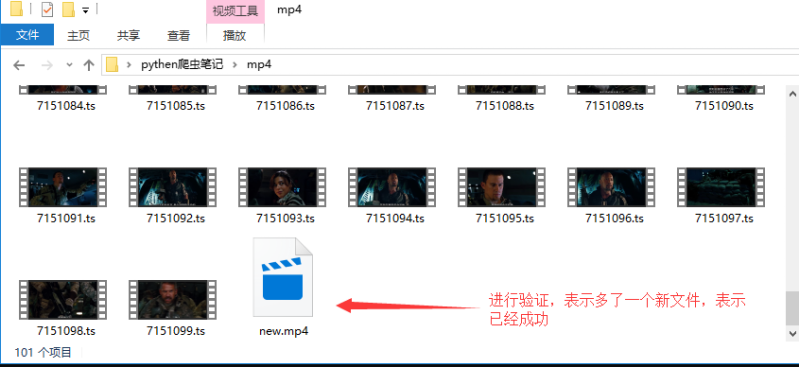
(五)、进行验证
(
五、有疑问请留言
如何利用python爬虫爬取爱奇艺VIP电影?的更多相关文章
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- 使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息 转载请注明出处. 爬取目标:每个电影的评分.名称.时长.主演.和类型 爬取思路: 源文件:(有注释) from selenium import webd ...
- Python 爬虫实例(5)—— 爬取爱奇艺视频电视剧的链接(2017-06-30 10:37)
1. 我们找到 爱奇艺电视剧的链接地址 http://list.iqiyi.com/www/2/-------------11-1-1-iqiyi--.html 我们点击翻页发现爱奇艺的链接是这样的 ...
- Python爬取爱奇艺资源
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素“ ...
- Python爬虫爬取BT之家找电影资源
一.写在前面 最近看新闻说圣城家园(SCG)倒了,之前BT天堂倒了,暴风影音也不行了,可以说看个电影越来越费力,国内大厂如企鹅和爱奇艺最近也出现一些幺蛾子,虽然目前版权意识虽然越来越强,但是很多资源在 ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- 利用Python爬虫爬取指定天猫店铺全店商品信息
本编博客是关于爬取天猫店铺中指定店铺的所有商品基础信息的爬虫,爬虫运行只需要输入相应店铺的域名名称即可,信息将以csv表格的形式保存,可以单店爬取也可以增加一个循环进行同时爬取. 源码展示 首先还是完 ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 爬取爱奇艺电视剧url
----因为需要顺序,所有就用串行了---- import requests from requests.exceptions import RequestException import re im ...
随机推荐
- msbuild不是内部或外部命令
首先这个问题纠结了很久,在网上找了查阅了很多博客,大多在介绍介绍批处理为何物,但是就是没有明确的解决方案. 如果想具体了解msbuild是何物,自己查找资料把. 好吧,下面介绍下正确的解决方案. 很简 ...
- Java图片裁剪
public static void main(String[] args) throws IOException { String path = "C:/Users/yang/Deskto ...
- 预处理、const、static与sizeof-static有什么作用(至少说出2个)
1:在C语言中,关键字static有3个明显的作用: (1)在函数体,一个被声明为静态的变量在这一函数被调用的过程中维持其值不变. (2)在模块内(但在函数体外),一个被声明为静态的变量可以被模块内所 ...
- 【sed】基本用法
1. 文本处理 sed编辑器根据sed命令处理数据流中的数据:在流编辑器将所有命令与一行数据匹配完后,它会读取下一行数据并重复以下过程: (1) 一次从输入中读取一行数据 (2) 根据所提供的编辑器命 ...
- IntelliJ IDEA 2017.3 搭建一个多模块的springboot项目(一)
新人接触springboot,IDE使用的是IntelliJ IDEA 2017.3 ,自己摸索了很久,现在自己整理一下,里面有些操作我自己也不懂是为什么这样,只是模仿公司现有的项目,自己搭建了一个简 ...
- 第11组 Alpha冲刺(3/6)
第11组 Alpha冲刺(3/6) 队名 不知道叫什么团队 组长博客 https://www.cnblogs.com/xxylac/p/11872098.html 作业博客 https://edu ...
- Echarts4+EchartsGL 3D迁徙图(附源码)
最近遇到些Echarts迁徙图问题,在实现二维地图的迁徙图后开始开发3D迁徙图,在网上一查,发现3D版本迁徙图资料较少,自己研究并借鉴一些资料后写了一个小demo,希望能帮大家少走些弯路,共同学习. ...
- 黑马vue---19、v-for中key的使用注意事项
黑马vue---19.v-for中key的使用注意事项 一.总结 一句话总结: 必须 在使用 v-for 的同时,指定 唯一的 字符串/数字 类型 :key 值 <p v-for="i ...
- pm2 配合log4js处理日志
1.pm2启动时通常会发现log4js记录不到日志信息: 2.决解方案,安装pm2的pm2-intercom进程间通信模块 3.在log4js的配置文件logger.js里添加如下命令: pm2: t ...
- python -v 和-V
python -v 小写v:这是版本信息,包括库版本 python -V 大写v:只看python的版本