查准率(precision)和查全率(recall)
一、理解查准率(precision)& 查全率(recall)
我们在平时常用到的模型评估指标是精度(accuracy)和错误率(error rate),错误率是:分类错误的样本数站样本总数的比例,即E=n/m(如果在m个样本中有n个样本分类错误),那么1-a/m就是精度。除此之外,还会有查准率和查全率,下面举例解释。
按照周志华《机器学习》中的例子,以西瓜问题为例。
错误率:有多少比例的西瓜被判断错误;
查准率(precision):算法挑出来的西瓜中有多少比例是好西瓜;
查全率(recall):所有的好西瓜中有多少比例被算法跳了出来。
继续按照上述前提,对于二分类问题,我们根据真实类别与算法预测类别会有下面四个名词:
在写下面四个名词前,需要给一些关于T(true)、F(false)、P(positive)、N(negative)的解释:P表示算法预测这个样本为1(好西瓜)、N表示算法预测这个样本为0(坏西瓜);T表示算法预测的和真实情况一样,即算法预测正确,F表示算法预测的和真实情况不一样,即算法预测不对。
- TP:正确地标记为正,即算法预测它为好西瓜,这个西瓜真实情况也是好西瓜(双重肯定是肯定);
- FP:错误地标记为正,即算法预测它是好西瓜,但这个西瓜真实情况是坏西瓜;
- FN:错误地标记为负,即算法预测为坏西瓜,(F算法预测的不对)但这个西瓜真实情况是好西瓜(双重否定也是肯定);
- TN:正确地标记为负,即算法标记为坏西瓜,(T算法预测的正确)这个西瓜真实情况是坏西瓜。
所以有:

二、查准率(precision)& 查全率(recall)的关系
- 查准率和查全率是一对矛盾的指标,一般说,当查准率高的时候,查全率一般很低;查全率高时,查准率一般很低。比如:若我们希望选出的西瓜中好瓜尽可能多,即查准率高,则只挑选最优把握的西瓜,算法挑选出来的西瓜(TP+FP)会减少,相对挑选出的西瓜确实是好瓜(TP)也相应减少,但是分母(TP+FP)减少的更快,所以查准率变大;在查全率公式中,分母(所有好瓜的总数)是不会变的,分子(TP)在减小,所以查全率变小。
- 在实际的模型评估中,单用Precision或者Recall来评价模型是不完整的,评价模型时必须用Precision/Recall两个值。这里介绍三种使用方法:平衡点(Break-Even Point,BEP)、F1度量、F1度量的一般化形式。
- BEP是产准率和查全率曲线中查准率=查全率时的取值,如下:

P-R曲线与平衡点
从图中明显看出算法效果:A>B>C
- F1度量的准则是:F1值越大算法性能越好。

- 在一些实际使用中,可能会对查准率或者查全率有偏重,比如:逃犯信息检索系统中,更希望尽量少的漏掉逃犯,此时的查全率比较重要。会有下面F1的一般形式。
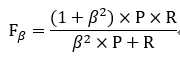
当beta>1时查全率重要,beta<1时查准率重要
参考文献
[1] 周志华 《机器学习》
查准率(precision)和查全率(recall)的更多相关文章
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- P(查准率),R(查全率),F1 值
起源: 我们平时用的精度 accuracy,也就是整体的正确率 acc=predict_right_num/predict_num 这个虽然常用,但不能满足所有任务的需求.比如,因为香蕉太多了,也不能 ...
- 详谈P(查准率),R(查全率),F1值
怎么来的? 我们平时用的精度accuracy,也就是整体的正确率 acc = predict_right_num / predict_num 这个虽然常用,但不能满足所有任务的需求.比如,因为香蕉太多 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
- 目标检测评价标准(mAP, 精准度(Precision), 召回率(Recall), 准确率(Accuracy),交除并(IoU))
1. TP , FP , TN , FN定义 TP(True Positive)是正样本预测为正样本的数量,即与Ground truth区域的IoU>=threshold的预测框 FP(Fals ...
- 准确率(Precision),召回率(Recall)以及综合评价指标(F1-Measure)
准确率和召回率是数据挖掘中预测,互联网中得搜索引擎等经常涉及的两个概念和指标. 准确率:又称“精度”,“正确率” 召回率:又称“查全率” 以检索为例,可以把搜索情况用下图表示: 相关 不相关 检索 ...
- [吴恩达机器学习笔记]11机器学习系统设计3-4/查全率/查准率/F1分数
11. 机器学习系统的设计 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 11.3 偏斜类的误差度量 Error Metr ...
- Elasticsearch教程-从入门到精通(转载)
转载,原文地址:http://mageedu.blog.51cto.com/4265610/1714522?utm_source=tuicool&utm_medium=referral 各位运 ...
- 线性回归,逻辑回归,神经网络,SVM的总结
目录 线性回归,逻辑回归,神经网络,SVM的总结 线性回归,逻辑回归,神经网络,SVM的总结 详细的学习笔记. markdown的公式编辑手册. 回归的含义: 回归就是指根据之前的数据预测一个准确的输 ...
- Elasticsearch教程-从入门到精通(转)
原文:http://mageedu.blog.51cto.com/4265610/1714522?utm_source=tuicool&utm_medium=referral 各位运维同行朋友 ...
随机推荐
- Can I prevent the Firefox developer tools network panel from clearing on page reload?
Can I prevent the Firefox developer tools network panel from clearing on page reload? I couldn't fin ...
- python 设计模式之访问者模式
写在前面 设计模式是经过总结.优化的,对我们经常会碰到的一些编程问题的可重用解决方案.一个设计模式并不像一个类或一个库那样能够直接作用于我们的代码.反之,设计模式更为高级,它是一种必须在特定情形下实现 ...
- python读取csv文件、excel文件并封装成dict类型的list,直接看代码
# coding=UTF-8import csvimport xlrd class ReaderFile(): """ 读取csv文件 filePath:文件路径 &qu ...
- sudo内容
[root@bogon ~]# cat /etc/sudoers## Sudoers allows particular users to run various commands as## the ...
- 为什么要用k8s
经过几次面试,发现有的公司没有用过k8s,有的公司正在用,但是都问了共同的问题:k8s的好处在哪里.所以总结了一下几点 1.故障迁移:当某一个node节点关机或挂掉后,node节点上的服务会自动转移到 ...
- 使用mysqldump备份表数据
使用mysqldump备份远程表数据到本地 下面的命令是使用mysqldump命令备份远程数据库的一张表的信息,并将信息保存到本地的一个文件的一个示例: mysqldump -h 192.168.1. ...
- Ubuntu-18.04更改安装源为国内源
环境查看 修改源文件 /etc/apt/sources.list 备份配置文件后把文件内容替换如下 deb http://mirrors.aliyun.com/ubuntu/ bionic main ...
- iOS-AVPlayer
MPMoviePlayerController足够强大,几乎不用写几行代码就能完成一个播放器,但是正是由于它的高度封装使得要自定义这个播放 器变得很复杂,甚至是不可能完成.例如有些时候需要自定义播放器 ...
- 《Fluid Engine Development》 学习笔记3-光滑粒子流体动力学
用粒子表示流体最热门的方法就是就是光滑粒子流体动力学(Smoothed Particle Hydrodynamics (SPH).) 这种方法模糊了流体的边界,用有限数量的粒子代表流体,该方法的基本思 ...
- Python----数据预处理代码实例
为方便收藏学习,转载自:https://www.jb51.net/article/158168.htm 本文实例为大家分享了Python数据预处理的具体代码,供大家参考,具体内容如下 1.导入标准库 ...