字符编码之间的转换 utf-8 , gbk等,(解决中文字符串乱码)
目录
1.背景.
2.编码的理解
3.编码之间的相互转化
4. str类型说明
5. 可以使用的编码类型
6.参考文章
1.背景
Python中与其他程序进行交互时,如果存在字符串交互,特别是字符串中含有中文时,需要注意字符的格式,需要保持两边一致。
笔者在开发中遇到一个python 调用Labview编译的dll函数,需要输入一个字符串路径。当路径中含有中文时,由于两边编码不一致,会导致报错。
2.编码的理解
1. python 中写代码时,一般通过在一开始使用 # -*- coding: utf-8 -*- 或者其他告诉编译器当前代码默认的编码是什么,这里就是utf-8格式,现在比较通用。
当string_a = ‘Bing,你好’
Type(string_a) = str
可见当赋值一个字符串时,python 默认是str类型。
通过encode(‘utf-8’),decode(‘utf-8’)可以进行格式的编码或者解码。编码后的变量类型是bytes类型,完整的说应该是 按照utf-8格式编码的bytes类型。
我的中文环境的Labview中默认编码格式是gbk格式,所以我用python将字符串送入labview编译的dll中时,需要 先将 字符串编码成gbk格式,比如 string_a.encode(‘gbk’),当收到labview编译的dll函数中传出来的字符串时,需要先将收到的 string_b_out.decode(‘gbk’) 这样就能显示中文,而不是乱码了。
在python(笔者当前为3.7版本)中,为编码的字符串类型为str,无论编码成 ‘utf-8’还是‘gbk’,类型都会从str类型变为bytes类型。
下面我们结合代码理解:
s='Bing-中国-!'
print('type(s)',type(s))
打印如下内容----------------
type(s) <class 'str'>
打印内容结束----------------
a=s.encode('utf-8')
b=s.encode('gb2312')
c=s.encode('gb18030')
d=s.encode('gbk')
print("a=s.encode('utf-8'), a=",a)
print("b=s.encode('gb2312'),b=",b)
print("c=s.encode('gb18030'),c=",c)
print("d=s.encode('gbk'),d=",d)
打印如下内容----------------
a=s.encode('utf-8'), a= b'Bing-\xe4\xb8\xad\xe5\x9b\xbd-\xef\xbc\x81'
b=s.encode('gb2312'),b= b'Bing-\xd6\xd0\xb9\xfa-\xa3\xa1'
c=s.encode('gb18030'),c= b'Bing-\xd6\xd0\xb9\xfa-\xa3\xa1'
d=s.encode('gbk'),d= b'Bing-\xd6\xd0\xb9\xfa-\xa3\xa1'
打印内容结束----------------
print('type(a)',type(a))
print('type(b)',type(b))
print('type(c)',type(c))
print('type(d)',type(d))
打印如下内容----------------
type(a) <class 'bytes'>
type(b) <class 'bytes'>
type(c) <class 'bytes'>
type(d) <class 'bytes'>
打印内容结束----------------
a=a.decode('utf-8')
b=b.decode('gb2312')
c=c.decode('gb18030')
d=d.decode('gbk')
print("a=a.decode('utf-8'), a=",a)
print("b=b.decode('gb2312'),b=",b)
print("c=c.decode('gb18030'),c=",c)
print("d=d.decode('gbk'),d=",d)
打印如下内容----------------
a=a.decode('utf-8'), a= Bing-中国-!
b=b.decode('gb2312'),b= Bing-中国-!
c=c.decode('gb18030'),c= Bing-中国-!
d=d.decode('gbk'),d= Bing-中国-!
打印内容结束----------------
可见原来的内容又回来了,此时a,b,c,d的类型为str。
3.编码之间的相互转化
另一种情况,当我编码了utf-8后,是否可以从utf-8直接编码或者解码成 gbk格式
答案是不可以,必须先解码成 str类型,再重新编码为gbk编码的bytes类型。
所以其实编码解码之间还是有方向性的。
当变量类型为 str类型时,智能编码,使用encode(‘编码格式’)方法;当bytes类型时,按道理只用解码decode(‘编码格式’) 才不会出错。
上图:
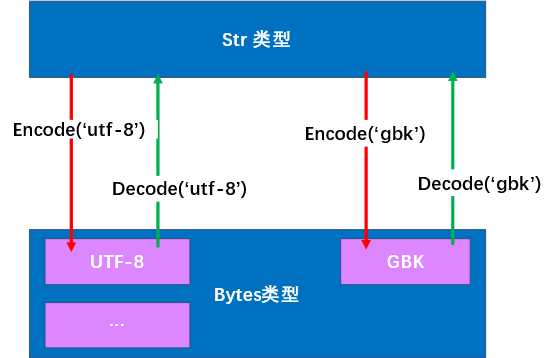
GBK需要转化为utf-8的流程为:
1. 首先通过decode(‘gbk’)转化为 str 类型
2. 再通过encode(‘utf-8’)转化为编码为utf-8的bytes类型。
#%% 当编码了utf-8后需要转化为gbk,应该先解码,再重新编码成gbk,即不同编码格式之间不能直接转化。
s='Bing-中国-!'
print('type(s)',type(s)) a=s.encode('utf-8')
print('type(a)',type(a)) #--------------------------------------
b=a.encode('gb2312') # 会报错如下内容
# 会报错如下内容
# type(s) <class 'str'>
# type(a) <class 'bytes'>
# Traceback (most recent call last):
# File "D:\Python\decodeandencode.py", line 60, in <module>
# b=a.encode('gb2312')
# AttributeError: 'bytes' object has no attribute 'encode' #-----------------------------------
b=a.decode('gb2312') # 也会报错,当编码无法使用正确识别时。
# 会报错如下内容
# type(s) <class 'str'>
# type(a) <class 'bytes'>
# Traceback (most recent call last):
# File "D:\Python\decodeandencode.py", line 71, in <module>
# b=a.decode('gb2312')
# UnicodeDecodeError: 'gb2312' codec can't decode byte 0xad in position 7: illegal multibyte sequence
4. str类型说明
在网上看到有人说str类型在python中其实是按照unicode来保存的。但是会显性成str我们看到的字符。
5. 可以使用的编码类型
除了utf-8和gbk以外,还可以编码成很多类型。在python的帮助文档中摘取一小部分:
|
Codec |
Aliases |
Languages |
|
euc_kr |
euckr, korean, ksc5601, ks_c- |
Korean |
|
gb2312 |
chinese, csiso58gb231280, euc |
Simplified Chinese |
|
gbk |
936, cp936, ms936 |
Unified Chinese |
|
gb18030 |
gb18030-2000 |
Unified Chinese |
|
hz |
hzgb, hz-gb, hz-gb-2312 |
Simplified Chinese |
|
iso2022_jp |
csiso2022jp, iso2022jp, iso-2022- |
Japanese |
|
iso2022_jp_1 |
iso2022jp-1, iso-2022-jp-1 |
Japanese |
|
iso2022_jp_2 |
iso2022jp-2, iso-2022-jp-2 |
Japanese, Korean, Simplified Chi |
6.参考文章
https://www.jb51.net/article/179894.htm
字符编码之间的转换 utf-8 , gbk等,(解决中文字符串乱码)的更多相关文章
- 字符编码之间的相互转换 UTF8与GBK(转载)
转载自http://www.cnblogs.com/azraelly/archive/2012/06/21/2558360.html UTF8与GBK字符编码之间的相互转换 C++ UTF8编码转换 ...
- 【miscellaneous】【C/C++语言】UTF8与GBK字符编码之间的相互转换
UTF8与GBK字符编码之间的相互转换 C++ UTF8编码转换 CChineseCode 一 预备知识 1,字符:字符是抽象的最小文本单位.它没有固定的形状(可能是一个字形),而且没有值." ...
- (2)字符编码关系和转换(bytes类型)
ASCII 占一个字节,只支持英文 GB2312 占2个字节,只支持6700+汉字 GBK 是GB2312的升级版,支持21000+汉字 Shift-JIS 日本字符编码 ks_c-5601-1987 ...
- 【JAVA编码】 JAVA字符编码系列二:Unicode,ISO-8859,GBK,UTF-8编码及相互转换
http://blog.csdn.net/qinysong/article/details/1179489 这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记 ...
- Python常见字符编码间的转换
主要内容: 1.Unicode 和 UTF-8的爱恨纠葛 2.字符在硬盘上的存储 3.编码的转换 4.验证编码是否转换正确 5.Python bytes类型 前 ...
- 《Python CookBook2》 第一章 文本 - 每次处理一个字符 && 字符和字符值之间的转换
文本 - 总结: 什么是文本Python 中的string 类型是不可变类型.文本,一个字符的矩阵,每一个单独的文本快可以被缩进和组织起来. 基本的文本操作①解析数据并将数据放入程序内部的结构中:②将 ...
- Python - 字符和字符值之间的转换
字符和字符值之间的转换 Python中, 字符和字符值, 直接的转换, 包含ASCII码和字母之间的转换,Unicode码和数字之间的转换; 也可以使用map, 进行批量转换, 输出为集合, 使用jo ...
- Delphi字符串、PChar与字符数组之间的转换
来自:http://my.oschina.net/kavensu/blog/193719 ------------------------------------------------------- ...
- Linux 字符编码 查看与转换
Linux 查看文件编码格式 Vim 查看文件编码 set fileencoding // 即可显示文件编码格式 若想解决Vim查看文件乱码问题, 可以在 .vimrc 文件添加 set encodi ...
随机推荐
- Docker系列(15)- Commit镜像
docker commit 提交容器成为一个新的副本,有点像套娃 # 命令和git原理类似 docker commit -m="提交的描述信息" -a="作者" ...
- 一生挚友redo log、binlog《死磕MySQL系列 二》
系列文章 原来一条select语句在MySQL是这样执行的<死磕MySQL系列 一> 一生挚友redo log.binlog<死磕MySQL系列 二> 前言 咔咔闲谈 上期根据 ...
- sonar-scanner的使用
在服务器搭建sonarqube后,本地的windows个人电脑如何使用sonar-scanner? 在服务器搭建sonarqube后,每个人都可以在本地使用sonar-scanner扫描代码. son ...
- js 模板方法模式
* 分离出共同点 function Beverage() {} Beverage.prototype.boilWater = function() { console.log("把水煮沸&q ...
- vue1.0,2.0区别 生命周期
1.生命周期 删除 beforeCompile compiled ready,新增beforeMounted mounted beforeUpdate updated 2.for循环里取消了$ind ...
- 利用griddata进行二维插值
有时候会碰到这种情况: 实际问题可以抽象为 \(z = f(x, y)\) 的形式,而你只知道有限的点 \((x_i,y_i,z_i)\),你又需要局部的全数据,这时你就需要插值,一维的插值方法网上很 ...
- HTML 网页开发、CSS 基础语法—— 一. HTML概述(了解网页)
1. 网页的本质 ① HTML就是用来制作网页文件的. ② 浏览器查看的网页都是.html或.htm文件. ③ HTML叫做超文本标记语言(Hypertext Markup Language),用于搭 ...
- CF346E-Doodle Jump【类欧】
正题 题目链接:https://www.luogu.com.cn/problem/CF346E 题目大意 给出\(a,n,p,h\),在每个\(ax\%p(x\in[0,n])\)的位置有一个关键点, ...
- P7581-「RdOI R2」路径权值【长链剖分,dp】
正题 题目链接:https://www.luogu.com.cn/problem/P7581 题目大意 给出\(n\)个点的有边权有根树,\(m\)次询问一个节点\(x\)的所有\(k\)级儿子两两之 ...
- 做毕设的tricks
CNKI上无法下载博硕士学位论文的PDF版本,只有CAJ版本,挺恶心的.直接下载安装Chrome extension就可以解决了. 链接:https://share.weiyun.com/5HGFF2 ...