大数据学习(04)——MapReduce原理
前两篇文章介绍了HDFS的原理和高可用,下面再来介绍Hadoop的另外一个模块MapReduce。它的思想是很多技术的鼻祖,值得一学。
MapReduce是什么
MapReduce是一个分布式计算系统,它可以类比为SQL里的select ...group by...
它被分为两个阶段。第一个阶段叫Map,它每次处理一条原始数据的映射、转换,并将中间结果合并、排序,生成Reduce阶段的输入数据。第二个阶段叫Reduce,它拉取Map处理好的数据做排序,一次处理一组数据,生成最终结果。
从上面的定义可以看出,MapReduce是用来做集合的分组汇总操作,它只关心想要的少部分字段,对于原始记录的大多数字段都会忽略掉。
迭代器模式
为啥要在这里提迭代器模式?这是一位老师总结出来的心得。他认为MapReduce的处理过程跟迭代器模式非常像。
我们来看看迭代器模式的定义。学过设计模式的都知道,设计模式包含定义、参与者、场景等等。这里我们来看看定义和场景。
定义:迭代器模式(Iterator),提供一种方法顺序访问一个聚合对象中的各种元素,而又不暴露该对象的内部表示。
场景:
- 访问一个聚合对象的内容而无需暴露它的内部表示
- 支持对聚合对象的多种遍历
- 为遍历不同的聚合结构提供一个统一的接口
目前还看不出来迭代器与MapReduce的相似之处,先写这里以后来看。
Map原理
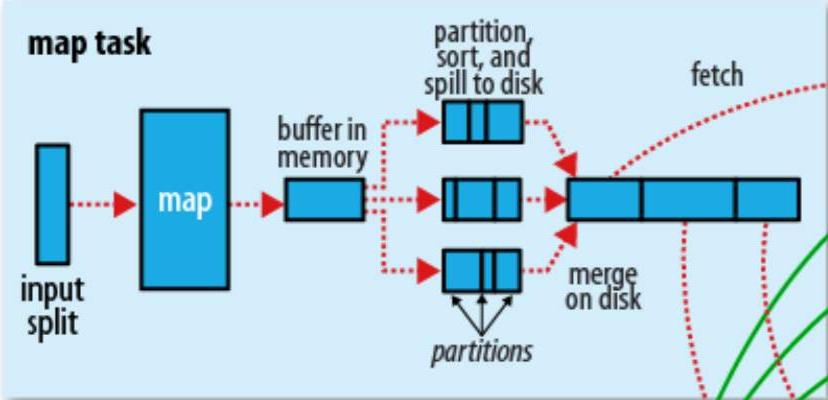
在HDFS中,文件是以Block为单位来存放的。但是在Map任务中,输入的单位是split,它跟Block可以是1:1、1:N、N:1的关系。也就是说
- 一个Block块可以被一个Map任务处理
- 一个Block块可以被多个Map任务处理,每个Map只处理其中一部分
- 多个Block块可以合并被一个Map任务处理
Map的处理是在内存里的,而一个Block块的大小可以是128M,也可以是1G,这取决于你在配置文件中的定义。在默认1:1的情况下,如果Block块太大,超出了Map进程所占用的内存,那就没办法一次放到内存中。另外,Map是针对每一条记录来做映射、转换的,它一次只需要读取一条记录,不关心后面还有多少记录。这就可以借鉴迭代器的处理方式,每次从文件读一条记录,处理完之后再判断后面还有没有记录,有的话继续处理,没有就结束。
每条记录经过Map处理的结果是一个K,V,P的三元组,K,V是键和值这好理解,K值相同的记录是一组。P是K的散列值(对Reduce任务数量做散列),决定了它会被哪一个Reduce任务拉取。
当Map任务处理了一部分数据之后,它需要把内存里的处理结果落盘,以便释放空间来处理后续的文件。在落盘之前,它会做这么一件事,就是在内存中,对处理结果排序。首先根据P来排序,不同P值的数据会被不同的Reduce拉取。同一个P值的数据再根据K来排序。排完序的数据就可以落盘了。经过多次这样的操作,它会生成很多个小文件,这些小文件之间内部有序外部无序。在原始文件处理完毕,小文件全部生成之后,使用归并算法将小文件合并成一个中间结果文件,这个文件总体来讲先以P排序,相同P值再以K排序。至此,Map阶段的任务就完成了。
Reduce原理
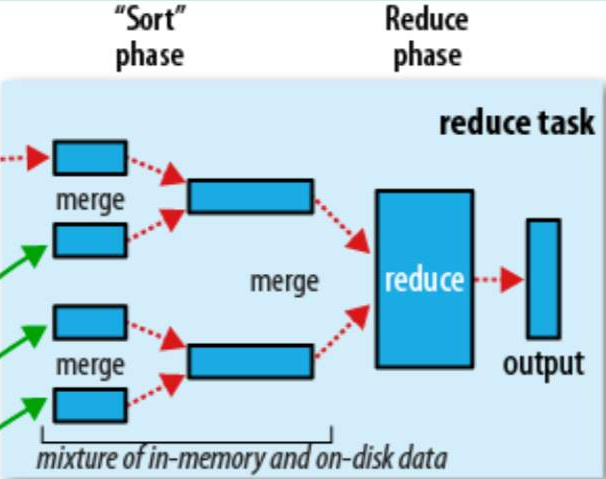
Reduce阶段它的大处理单元是分区,即Map阶段处理后的P值。它的小处理单元是组,即K值相同的一组数据。
首先,它从所有的Map任务节点拉取自己分区的数据,然后将这些文件归并排序生成Reduce任务的输入数据。经过Reduce计算后,生成最终结果数据。
Map和Reduce的关系
Map与Reduce两个阶段的任务是线性阻塞的。
Map的结果集中,Key值相同的数据属于同一个分组,一个组是不能被分割到不同的Reduce任务去处理的。
Map任务的个数取决于HDFS文件的Block数(Block:Split=1:1情况下),Reduce任务个数可以人工确定。
Map任务与Reduce任务的比例可以是N:1、N:N、1:1、1:N等多种情况。当任务数为1时,会牺牲系统的并发度。当任务数为N时,会增加整个系统的资源开销。
一个实际的任务很难由一次MapReduce过程完成,它会将多个MapReduce任务组成一个pipeline,上一次Reduce的输出成为下一次Map任务的输入,经过多次处理才能获取最终结果。
大数据学习(04)——MapReduce原理的更多相关文章
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
随机推荐
- [Linux]经典面试题 - 系统管理 - 备份策略
[Linux]经典面试题 - 系统管理 - 备份策略 目录 [Linux]经典面试题 - 系统管理 - 备份策略 一.备份目录 1.1 系统目录 1.2 服务目录 二.备份策略 2.1 完整备份 2. ...
- Java-Java8特性(更新中)
Java8新特性 之前零零散散写了很多java8的内容,今天做一个整理,也算是整理用到的内容,当然细化的话还有很多,只是说暂时用不到,为了面试的话已经够了 日期计算 Lambda表达式 函数式接口(比 ...
- 『心善渊』Selenium3.0基础 — 6、Selenium中使用XPath定位元素
目录 1.Selenium中使用XPath查找元素 (1)XPath通过id,name,class属性定位 (2)XPath通过标签中的其他属性定位 (3)XPath层级定位 (4)XPath索引定位 ...
- div和img垂直居中的方法
div垂直居中可以使用height和line-height,多个div的话就不适用了. 可以使用下面的方式垂直居中 <div class="parent"> <d ...
- 解决两个相邻的span,或者input和button中间有间隙,在css中还看不到
<span id="time"></span><span id="second"></span> <inp ...
- 简易版JDBC连接池
JDBC连接池mini版的实现 首先是工具类 DbUtil 主要参数就是Driver.User.PWD等啦,主要用于建立连接 URL需要注意的是SSL和serverTimezone参数,和mysql驱 ...
- Go nuts
含义: to behave in a crazy, enthusiastic, or violent way. 发起狂来 详细讲解 go 在这里也不是"去"的意思,而是和 get. ...
- java 语言知识
1.javase 标准版主要用于桌面应用.控制台:javaee 企业版主要用于web应用:javame微缩版主要用于嵌入式. 2.jre是java程序的运行环境,包含jvm(java虚拟机).jdk是 ...
- QT. 学习之路 二
Qt 的信号槽机制并不仅仅是使用系统提供的那部分,还会允许我们自己设计自己的信号和槽. 举报纸和订阅者的例子:有一个报纸类 Newspaper,有一个订阅者类 Subscriber.Subscribe ...
- 痞子衡嵌入式:串行NOR Flash的页编程模式对于量产时间的影响
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是串行NOR Flash的页编程模式对于量产时间的影响. 任何嵌入式产品最终都绕不开量产效率话题,尤其是对于主控是非内置 Flash 型 ...