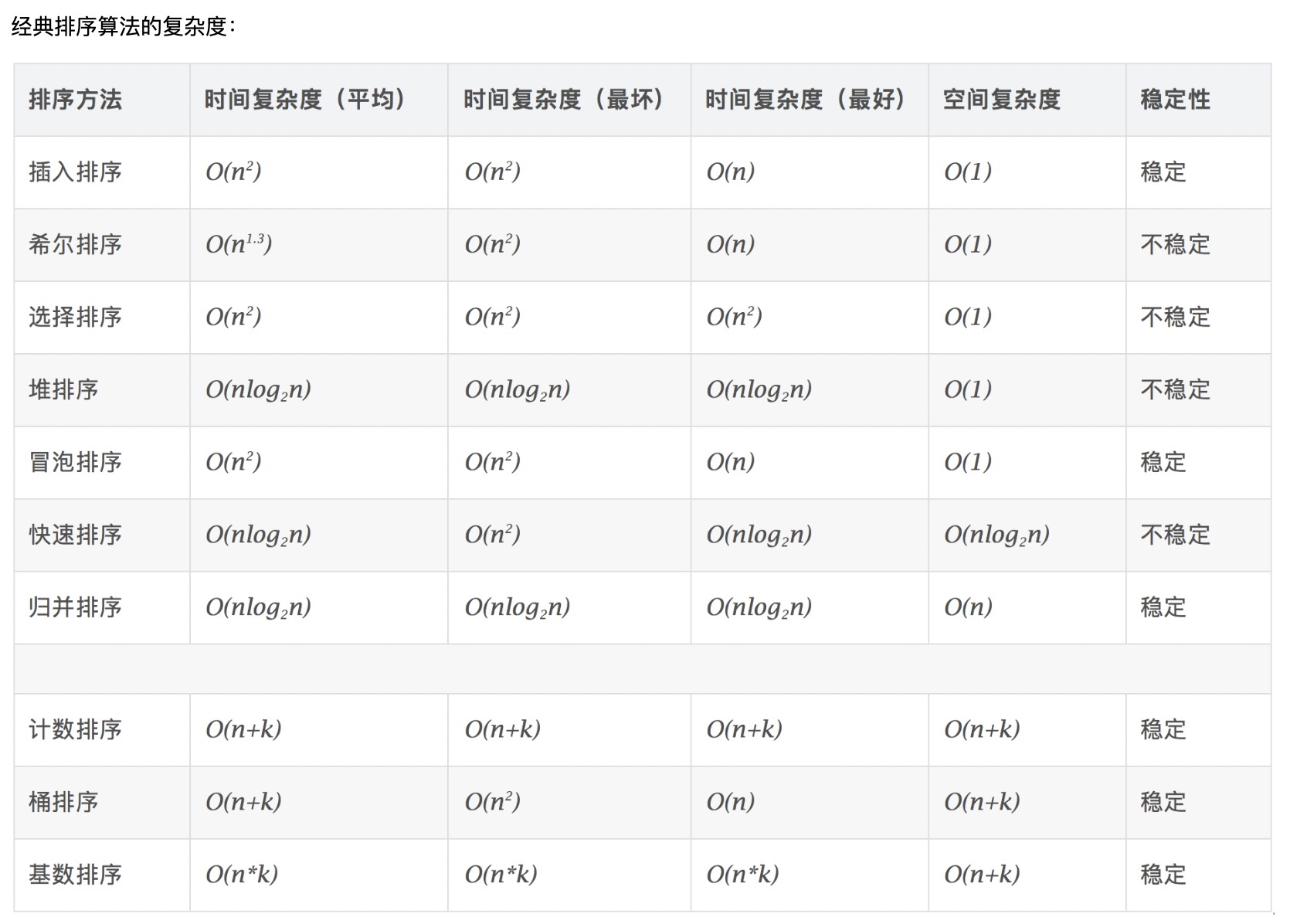
排序---python版
冒泡排序:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
#冒泡排序
def bubble_sort(list):
for i in range(len(list)-1):
for j in range(len(list)-i-1):
if list[j]>list[j+1]:
list[j], list[j + 1] = list[j + 1], list[j]
return list #冒泡排序改进版
def bubble_sort_better(list):
for i in range(len(list)-1):
isSort = True # 有序标记,每一轮的初始是true,用于判断元素间是否需要交换
for j in range(len(list)-i-1): # 这个循环负责控制比较的元素个数
if list[j]>list[j+1]:
list[j],list[j+1]=list[j+1],list[j]
isSort = False # 有交换行为设为 False
if isSort: # 无交换行为(isSorted = True),直接跳过本次循环
break
return list
选择排序(Selection Sort)
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
#选择排序:
def select_sort(list):
for i in range(len(list)-1):
min = i
for j in range(i+1,len(list)): # 第二层for表示最小元素和后面的元素逐个比较
if list[min]>list[j]:
min = j # 如果当前元素比最小元素小,则把当前元素角标记为最小元素角标
list[min],list[i] = list[i],list[min] return list
插入排序(Insertion Sort)
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
算法描述
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5。
#插入排序
def insert_sort(list):
for i in range(1,len(list)):
for j in range(i,0,-1): #range(10,0,-1)意思是从列表的下标为10的元素开始,倒序取到下标为0的元素(但是不包括下标为0元素)
if list[j]<list[j-1]:
list[j],list[j-1] = list[j-1] ,list[j]
else:
break
return list
快速排序(Quick Sort)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
算法描述
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
#快速排序
def quick_sort(list,start,end):
if start>=end: # 递归的退出条件
return
mid = list[start]
low = start
high = end
while low < high:
while low<high and list[high]>=mid: # 如果low与high未重合,high(右边)指向的元素大于等于基准元素,则high向左移动
high -= 1
list[low] = list[high]
while low<high and list[low]<=mid: # 如果low与high未重合,low指向的元素比基准元素小,则low向右移动
low += 1
list[high] = list[low]
list[low] = mid # 将基准元素放到该位置
quick_sort(list,start,low-1)
quick_sort(list,low+1,end)
return list
if __name__ == '__main__':
list = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44,8,19, 1,10,888,3,56,22,4,45,33,3,44,9,9,11]
# list1 = quick_sort(list,0,len(list)-1) #快速排序
# print(list1)
#list2 = bubble_sort(list) #冒泡排序
#print(list2)
# list3 = bubble_sort_better(list) #冒泡优化
# print(list3)
# list4 = select_sort(list) #选择排序
# print(list4)
list5 = insert_sort(list) #插入排序
print(list5)
排序---python版的更多相关文章
- 选择排序-Python与PHP实现版
选择排序Python实现 import random # 生成待排序数组 a=[random.randint(1,999) for x in range(0,36)] # 选择排序 def selec ...
- python之simplejson,Python版的简单、 快速、 可扩展 JSON 编码器/解码器
python之simplejson,Python版的简单. 快速. 可扩展 JSON 编码器/解码器 simplejson Python版的简单. 快速. 可扩展 JSON 编码器/解码器 编码基本的 ...
- python版的MCScan绘图
最近发现了python版的MCScan,是个大宝藏.由于走了不少弯路,终于画出美图,赶紧记录下来. github地址 https://github.com/tanghaibao/jcvi/wiki/M ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 数据结构:顺序表(python版)
顺序表python版的实现(部分功能未实现) #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __ini ...
- python版恶俗古风自动生成器.py
python版恶俗古风自动生成器.py """ python版恶俗古风自动生成器.py 模仿自: http://www.jianshu.com/p/f893291674c ...
- LAMP一键安装包(Python版)
去年有出一个python整的LAMP自动安装,不过比较傻,直接调用的yum 去安装了XXX...不过这次一样有用shell..我也想如何不调用shell 来弄一个LAMP自动安装部署啥啥的..不过尼玛 ...
- 编码的秘密(python版)
编码(python版) 最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你. 编码的概念 编码就是将信息从一种 ...
- Zabbix 微信报警Python版(带监控项波动图片)
#!/usr/bin/python # -*- coding: UTF- -*- #Function: 微信报警python版(带波动图) #Environment: python import ur ...
随机推荐
- python 中的变量内存以及关于is ==、 堆栈、
在工作学习中会碰到一些python中变量与内存层面的问题理解,虽然是在不断的解决,但是并没有做过这方面的总结. 变量:用来标识(identify)一块内存区域.为了方便表示内存,我们操作变量实质上是在 ...
- 链路追踪_SkyWalking的部署及使用
关于链路追踪,目前比较主流是Cat,Zipkin,SkyWalking等这些工具.这篇文章主要介绍关于SkyWalking工具的. 为什么用SkyWalking,因为它基本没有代码侵入,只这一点就足够 ...
- wxPython开发之密码管理程序
不想记密码?密码全设置成一样担心安全?用别人程序担心密码泄露?看完本博客,开发一个属于自己的密码管理程序吧 我们用到的是python的wxPython界面库包 先来看下成果界面:简洁主题明确 要想开 ...
- 如何彻底禁止 macOS Big Sur 自动更新,去除更新标记和通知
作者:gc(at)sysin.org,主页:www.sysin.org 请访问原文链接:https://sysin.org/article/Disable-macOS-Update/,查看最新版.原创 ...
- 【Azure 应用服务】由 Azure Functions runtime is unreachable 的错误消息推导出 ASYNC(异步)和 SYNC(同步)混用而引起ThreadPool耗尽问题
问题描述 在Azure Function Portal上显示: Azure Functions runtime is unreachable,引起的结果是Function App目前不工作,但是此前一 ...
- leetcode中Java关于Json处理的依赖
leetcode的java代码提供的main函数中,往往有关于json的依赖...我找了许久才找到他们用的是这个json实现 <dependency> <groupId>com ...
- Python+Selenium自动化-模拟键盘操作
Python+Selenium自动化-模拟键盘操作 0.导入键盘类Keys() selenium中的Keys()类提供了大部分的键盘操作方法:通过send_keys()方法来模拟键盘上的按键. # ...
- node.js学习(3)模块
1.创建文件 count.js 2 调用 3 改造 4 调用 5 再改造 6 在再改造
- 用Redis实现签到功能
一.场景 在很多时候我们会遇到用户签到的场景,每天用户进入应用时,需要获取用户当天的签到状态,如果没签到,用户可以进行签到,并且得到相关的奖励.我们可能需要每天的签到情况,必要的时候可能还需要统计一下 ...
- 十、使用Varnish加速Web
使用Varnish加速Web 构建Web服务器(web1) [root@web1 ~]# yum -y install httpd [root@web1 ~]# systemctl start ...