Endian
Endian
寻址
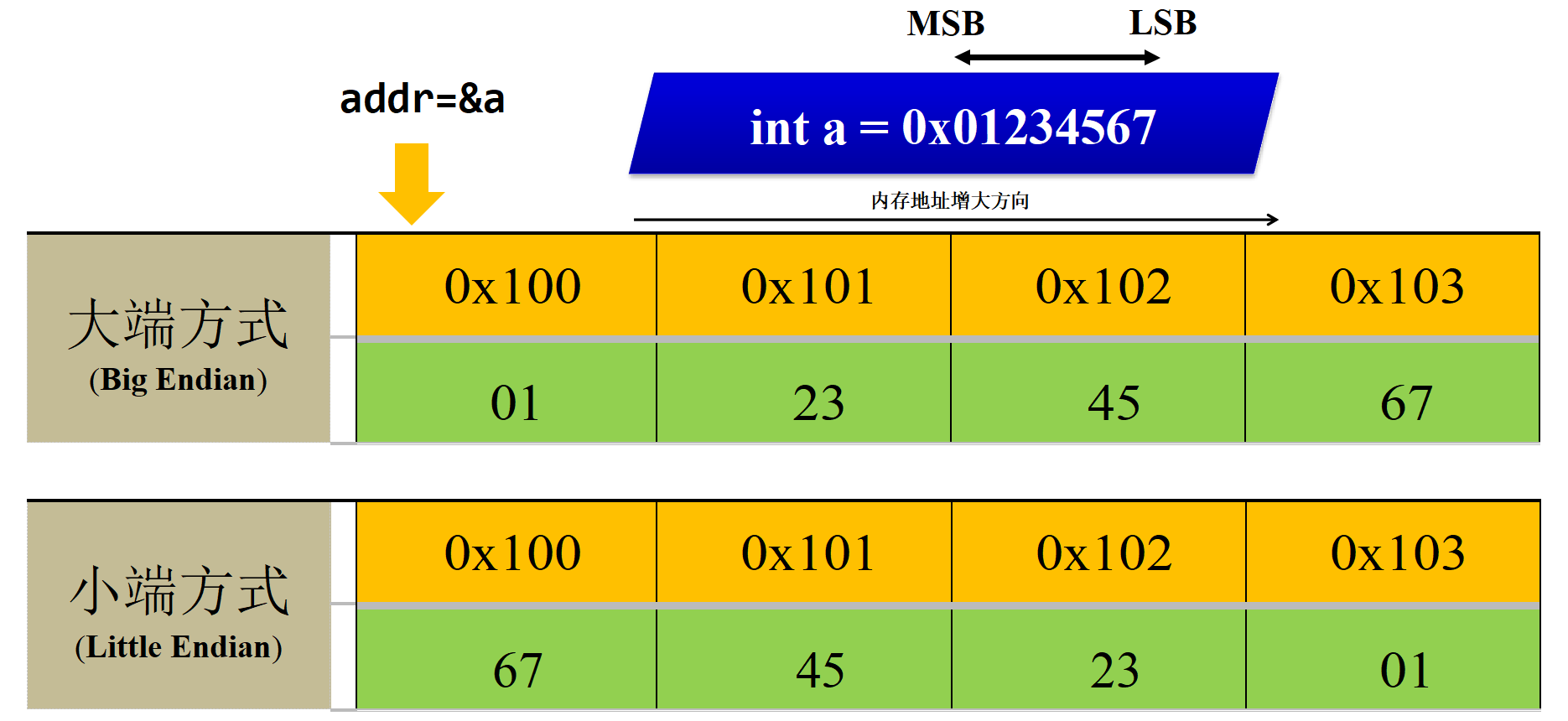
多字节对象被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。
例如,假设一个类型为 int 的变量 a 的地址为 0x100,也就是说,地址表达式 &a 的值为 0x100。那么,(假设数据类型 int 为32位表示) a 的 4 个字节将被存储在内存的 0x100、0x101、0x102 和 0x103 位置。
字节顺序
最低有效字节存储在起始地址,这称为小端(Little Endian)字节序;最高有效字节存储在起始地址,这称为大端(Big Endian)字节序。
术语“小端”和“大端”表示多字节值的哪一端(小端或大端)存储在该值的起始地址。
大多数 Intel 兼容机都只用小端模式。另一方面,IBM 和 Oracle 的大多数机器则是按大端模式操作。
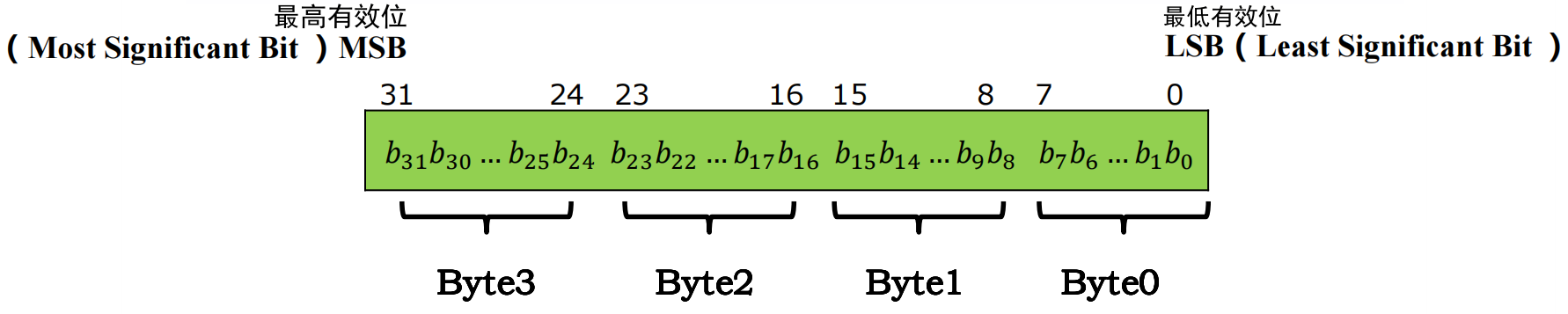
在下图中,我们标明内存地址增长的方向为从左到右。我们还标明最高有效位(Most Significant Bit,MSB)是这个32位值最左边一位,最低有效位(Least Significant Bit,LSB)是这个32位值最右边一位。 最高有效字节(Most Significant Byte)是 Byte3=0x01,最低有效字节(Least Significant Byte)是 Byte0=0x67 。
Endian Conversion Functions
我们把某个给定系统所用的字节序称为主机字节序(host byte order),网络协议为网络字节序(network byte order)(大端字节序)。
网络字节序是大端字节序。
Linux
下面4个函数是主机字节序和网络字节序之间相互转换的函数。在这些函数的名字中,h代表host,n代表network,s代表short,l代表long。short和long这两个称谓是出自4.2BSD的Digital VAX实现的历史产物。如今我们应该把s视为一个16位的值(例如TCP或UDP端口号),把l视为一个32位的值(例如IPv4地址)。事实上即使在64位的Digital Alpha中,尽管长整数占用64位,htonl和ntohl函数操作的仍然是32位的值。
当使用这些函数时,我们并不关心主机字节序和网络字节序的真实值(或为大端,或为小端)。我们所要做的只是调用适当的函数在主机和网络字节序之间转换某个给定值。在那些与网际协议所用字节序(大端)相同的系统中,这四个函数通常被定义为空宏。
// converts host byte order and network byte order
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
These functions convert the byte encoding of integer values from the byte order that the current CPU(the "host") uses, to and from little-endian and big-endian byte order.
// These functions convert the byte encoding of integer values from the byte order that the current CPU (the "host") uses,
// to and from little-endian and big-endian byte order.
#include <endian.h>
uint16_t htobe16(uint16_t host_16bits);
uint16_t htole16(uint16_t host_16bits);
uint16_t be16toh(uint16_t big_endian_16bits);
uint16_t le16toh(uint16_t little_endian_16bits);
uint32_t htobe32(uint32_t host_32bits);
uint32_t htole32(uint32_t host_32bits);
uint32_t be32toh(uint32_t big_endian_32bits);
uint32_t le32toh(uint32_t little_endian_32bits);
uint64_t htobe64(uint64_t host_64bits);
uint64_t htole64(uint64_t host_64bits);
uint64_t be64toh(uint64_t big_endian_64bits);
uint64_t le64toh(uint64_t little_endian_64bits);
Boost
Boost.Endian: The Boost Endian Library - 1.77.0
References
byteorder(3) - Linux manual page (man7.org)
Endian的更多相关文章
- unicode,ansi,utf-8,unicode big endian编码的区别
知乎--http://www.zhihu.com/question/23374078 http://wenku.baidu.com/view/cb9fe505cc17552707220865.html ...
- [转]unicode,ansi,utf-8,unicode big endian的故事
unicode,ansi,utf-8,unicode big endian的故事很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关状态是好的 ...
- c#,关于Big Endian 和 Little Endian,以及转换类
Big Endian:最高字节在地址最低位,最低字节在地址最高位,依次排列. Little Endian:最低字节在最低位,最高字节在最高位,反序排列. 当在本地主机上,无需注意机器用的是Big En ...
- 大端(big endian)和小端(little endian)
http://www.cnblogs.com/Romi/archive/2012/01/10/2318551.html 当前的存储器,多以byte为访问的最小单元,当一个逻辑上的地址必须分割为物理上的 ...
- sizeof usage & big / little endian
http://blog.csdn.net/w57w57w57/article/details/6626840 http://people.cs.umass.edu/~verts/cs32/endian ...
- <QtEndian> - Endian Conversion Functions
The <QtEndian> header provides functions to convert between little and big endian representati ...
- Check Big/Little Endian
Little endian:Low memory address stores low byte value.(eg. short int 0x2211 0xbfd05c0e->0x11 ...
- 字符编码笔记:ASCII,Unicode和UTF-8,附带 Little endian和Big endian的解释
作者: 阮一峰 日期: 2007年10月28日 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步 ...
- 字符编码笔记:ASCII、Unicode、UTF-8、UTF-16、UCS、BOM、Endian
转载:http://witmax.cn/character-encoding-notes.html 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问 ...
- write a macro to judge big endian or little endian
Big endian means the most significant byte stores first in memory. int a=0x01020304, if the cpu is b ...
随机推荐
- elsa core—3.elsa 服务
在本快速入门中,我们将介绍一个用于设置Elsa Server的最小ASP.NET Core应用程序.我们还将安装一些更常用的activities(活动),如Timer.Cron和sendmail,以能 ...
- Microsoft Remote Desktop 通过 .rdp 文件登录
最近在淘宝上买了「市场洞察」子账号,说是子账号,其实是需要登录到他们的 Windows 服务器上才能用的.并且子账号也是 5-6 个人共用的,且不说远程服务器很老又有延迟,经常是我想添加一个监控店铺或 ...
- 安装和配置CloudWatchAgent
文章原文 使用 CloudWatch 代理收集指标和日志 下载 CloudWatch 代理软件包 sudo yum install amazon-cloudwatch-agent 点击查看其他平台软件 ...
- 20210712 noip12
考场 第一次和 hzoi 联考,成功给 sdfz 丢人 尝试戴耳罩,发现太紧了... 决定改变策略,先用1h看题,想完3题再写. T1 一下想到枚举最大值,单调栈求出每个点能作为最大值的区间,然后以这 ...
- 20210715 noip16
考场 乍一看 T1 像是二分答案,手玩样例发现可以 \(O(k^2)\) 枚举点对,贪心地更新答案,完了?有点不信,先跳了 T2 的形式有点像逆序对,但没啥想法 T3 的式子完全不知道如何处理,一看就 ...
- Python - 通过PyYaml库操作YAML文件
PyYaml简单介绍 Python的PyYAML模块是Python的YAML解析器和生成器 它有个版本分水岭,就是5.1 读取YAML5.1之前的读取方法 def read_yaml(self, pa ...
- openswan协商流程之(三):main_inR1_outI2
主模式第三包:main_inR1_outI2 1. 序言 main_inR1_outI2()函数是ISAKMP协商过程中第三包的核心处理函数的入口.这里我们主要说明main_inR1_outI2的函数 ...
- CDI 组件拦截器的使用和学习
拦截器的作用原理: 声明拦截器,加@Interceptor注解 方法有二: 1)为拦截器添加Qualifier: 2)不添加Qualifier.为拦截器添加具体的拦截方法,该方法加@AroundInv ...
- webpack4. 使用autoprefixer 无效
解决办法: 在package.json文件中加上这个 "browserslist": [ "defaults", "not ie < 11&qu ...
- Java基础系列(15)- 用户交互Scanner
Scanner对象 之前我们学的基本语法中我们并没有实现程序和人的交互,但是Java给我们提供了这样一个工具类,我们可以获取用户的输入.java.util.Scanner是Java5的新特征.我们可以 ...