nodejs实现拉钩网爬虫
概述
详细
一、准备工作
1、安装最新版本的nodejs,其中npm会被自动安装
2、安装该项目需要的包
npm install cheerio jsdom mysql request -S
其中package.json中的内容为:
"dependencies": {
"cheerio": "^1.0.0-rc.1",
"jsdom": "^11.0.0",
"mysql": "^2.13.0",
"request": "^2.81.0"
}
二、程序实现
1、程序实现的目录结构如下:
2、实现思路如下:
index.js:程序主文件,各种数据清洗工作,url构造在这个文件中完成
Job.js : 用于构建Job对象,有助于写入数据库
db.js:连接数据库并写入数据
url_construct.js:可以自己配置抓取那些公司的职位信息。如阿里巴巴,百度,腾讯等。部分代码如下:
const companyNames = ["网易","阿里巴巴","百度","腾讯","去哪儿","浪潮"];
const encodedCompanyNames = [];
//转化为urlencoded
for(let i=0;i<companyNames.length;i++){
encodedCompanyNames.push(encodeURIComponent(companyNames[i]));
}
module.exports = encodedCompanyNames;
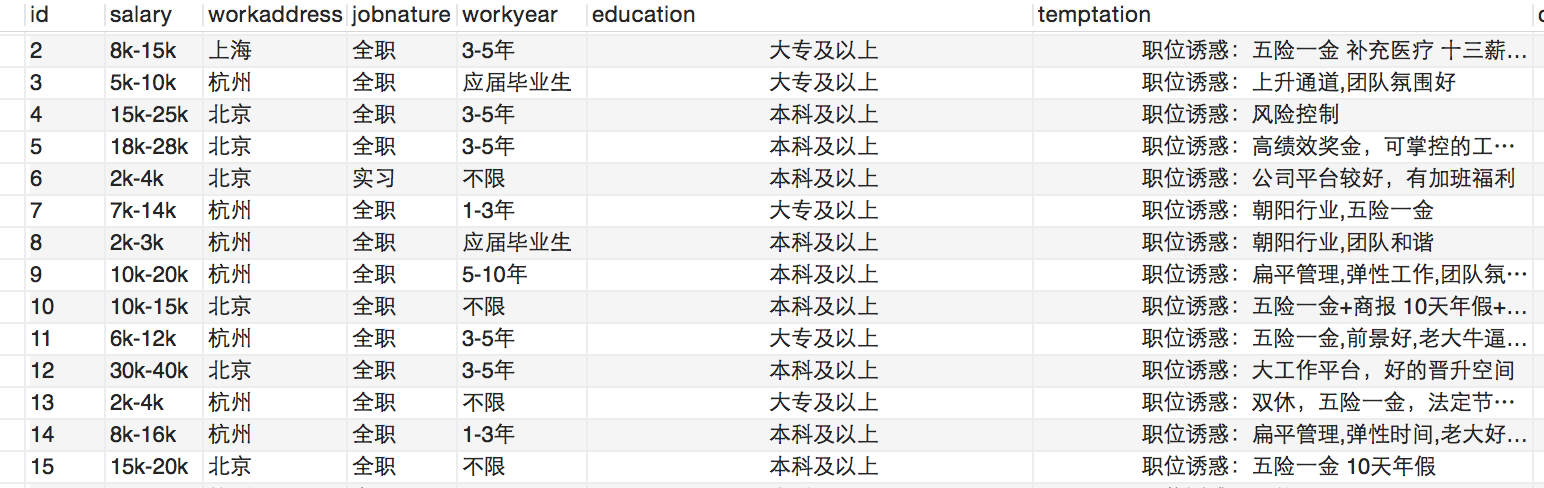
3、数据库设计截图

上面是本例子的数据库截图,其中id是主键,同时是自增的。
4、连接数据库注意点
下面的user和password的值是你安装数据库时候设置的,请自己修改
const pool = mysql.createPool({
connectionLimit:10,
database:TEST_DATABASE,
user:"root",
password:"root"
});
三、运行效果
首先cd到src目录下,然后简单的运行下面的命令就可以了:
node index.js
下面是数据库抓取的部分信息截图:
四、其他补充
如果你需要增加更多功能,可以在demo大师的"没有找到例子?"功能提出,我会增加例子,谢谢
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
nodejs实现拉钩网爬虫的更多相关文章
- day 112天,爬虫(拉钩网,斗音,GitHub)第二天
提前准备工作.安装准备工作(day3用) 1. 安装scrapy https://www.cnblogs.com/wupeiqi/articles/6229292.html a. 下载twiste ...
- Python3网络爬虫之requests动态爬虫:拉钩网
操作环境: Windows10.Python3.6.Pycharm.谷歌浏览器目标网址: https://www.lagou.com/jobs/list_Python/p-city_0?px=defa ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- 拉钩网爬取所有python职位信息
最近在找工作,所以爬取了拉钩网的全部python职位,以便给自己提供一个方向.拉钩网的数据还是比较容易爬取的,得到json数据直接解析就行,废话不多说, 直接贴代码: import json impo ...
- 使用request爬取拉钩网信息
通过cookies信息爬取 分析header和cookies 通过subtext粘贴处理header和cookies信息 处理后,方便粘贴到代码中 爬取拉钩信息代码 import requests c ...
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...
- 爬取拉钩网上所有的python职位
# 2.爬取拉钩网上的所有python职位. from urllib import request,parse import json,random def user_agent(page): #浏览 ...
- Python 爬取拉钩网工作岗位
如果拉钩网html页面做了调整,需要重新调整代码 代码如下 #/usr/bin/env python3 #coding:utf-8 import sys import json import requ ...
- ruby 爬虫爬取拉钩网职位信息,产生词云报告
思路:1.获取拉勾网搜索到职位的页数 2.调用接口获取职位id 3.根据职位id访问页面,匹配出关键字 url访问采用unirest,由于拉钩反爬虫,短时间内频繁访问会被限制访问,所以没有采用多线程, ...
随机推荐
- Windows上编译libtiff
将libtiff 4.0.3解压到[工作目录]/tiff/tiff-4.0.3 对于Release,编辑tiff/tiff-4.0.3里面的nmake.opt如下选项,去掉注释: JPEG_SUPPO ...
- 算法:图(Graph)的遍历、最小生成树和拓扑排序
背景 不同的数据结构有不同的用途,像:数组.链表.队列.栈多数是用来做为基本的工具使用,二叉树多用来作为已排序元素列表的存储,B 树用在存储中,本文介绍的 Graph 多数是为了解决现实问题(说到底, ...
- Selenium2+python自动化41-绕过验证码(add_cookie)
前言 验证码这种问题是比较头疼的,对于验证码的处理,不要去想破解方法,这个验证码本来就是为了防止别人自动化登录的.如果你能破解,说明你们公司的验证码吗安全级别不高,那就需要提高级别了. 对于验证码,要 ...
- 解决hue/hiveserver2对于hive date类型显示为NULL的问题
用户报在Hue中执行一条sql:select admission_date, discharge_date,birth_date from hm_004_20170309141149.inpatien ...
- (a*b)%c 小的技巧
(a*b)%c这个问题看上去好简单啊. 当然我们不是来说这么简单的问题了.你想一想,我们会不会遇到这种情况,a是__int64 ,b也是__int64 当两个数足够大的时候我们直接相乘的就会出现__i ...
- JavaBean的应用
1. 获取JavaBean属性信息 例1.1 在JSP页面中显示JavaBean属性信息. (1)创建名称为Produce的类,该类是封装商品对象的JavaBean,在Produce类中创建商品属性, ...
- Git教程之工作区和暂存区
工作区(Working Directory) 就是你在电脑里能看到的目录,比如我的learngit文件夹就是一个工作区:
- @JVM垃圾回收调优方法
JVM调优工具 Jconsole,jProfile,VisualVM Jconsole:jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用.对垃圾回收算法有很详细的跟踪. JProfiler: ...
- 第六章 HashSet源码解析
6.1.对于HashSet需要掌握以下几点 HashSet的创建:HashSet() 往HashSet中添加单个对象:即add(E)方法 删除HashSet中的对象:即remove(Object ke ...
- Android生成带图片的二维码
一.问题描述 在开发中需要将信息转换为二维码存储并要求带有公司的logo,我们知道Google的Zxing开源项目就很好的帮助我们实现条形码.二维码的生成和解析,但带有logo的官网并没有提供demo ...