Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)
一、创建虚拟机
1、从网上下载一个Centos6.X的镜像(http://vault.centos.org/)
2、安装一台虚拟机配置如下:cpu1个、内存1G、磁盘分配20G(看个人配置和需求,本人配置有点低所以参数有点低)
3、虚拟机安装建议去挑战minidesktop,分区自己创建有/boot(300)、swap(300)、/(分配全部空间)。
二、集群环境配置
1.准备Linux环境
设置一个IP地址,先将虚拟机的网络模式选为NAT模式,对应vmnet1和vmnet8,保证能ping通VMNet8和网络 例:www.baidu.com
修改主机名
#vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME= hadoop01
修改IP
两种方式:
第一种:通过Linux图形界面进行修改
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.35.100 子网掩码:255.255.255.0 (网关:192.168.1.1) -> apply
第二种:修改配置文件方式
#vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static"
ONBOOT="yes"
TYPE="Ethernet"
IPADDR="192.168.35.100"
NETMASK="255.255.255.0"
修改主机名和IP的映射关系
#vim /etc/hosts
192.168.35.100 hadoop01
192.168.35.101 hadoop02
关闭linux的防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动 开启防火墙 on
chkconfig iptables off
关闭window的防火墙
进入到windows的控制面板-> 找到window防火墙 -> 点击关闭windwos防火墙,全部关闭
开启或关闭linux服务器的图形界面:
vi /etc/inittab
重启Linux : reboot
2.安装JDK
上传JDK (上传工具 wincp ,securecrt ,vmtools)
解压jdk
tar -zxvf jdk-7u80-linux-x64.tar.gz -C /usr/local (一般在linux里放公共的系统使用的文件)
将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/usr/local/jdk1..0_80
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
Java -sersion验证一下
三、Hadoop环境搭建(在这里我将HDFS和YARN的配置信息放在了一起)
1、安装hadoop2.8.5
创建一个目录mkdir /bigdata,先上传hadoop的安装包到服务器上去/bigdata,解压hadoop工具到/bigdata文件中,tar -zxvf hadoop-2.6.4.tar.gz -C /bigdata
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
2、配置hadoop核心文件
<!--第一个:hadoop-env.sh->
vim hadoop-env.sh
#第27行
export JAVA_HOME=/usr/local/jdk1.7.0_80
<!--第二个:core-site.xml->
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<!--必须配置了hosts,要不然就是ip-?
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop-2.6.4/data</value>
</property>
<!--第三个:hdfs-site.xml->
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value> 3
</property>
<!--第四个:mapred-site.xml 系统没有直接提供,需要修改模板文件 mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml ->
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 第五个:yarn-site.xml->
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/usr/local/jdk1..0_80
export HADOOP_HOME=/bigdata/hadoop-2.6.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
刷新配置文件
source /etc/profile
格式化namenode(是对namenode进行初始化) 格式化文件系统
hdfs namenode -format(历史命令 hadoop namenode -format)
启动hadoop
先启动HDFS
sbin/start-dfs.sh
再启动YARN
sbin/start-yarn.sh
验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
通过网页验证
http://192.168.35.100:50070 (HDFS管理界面)
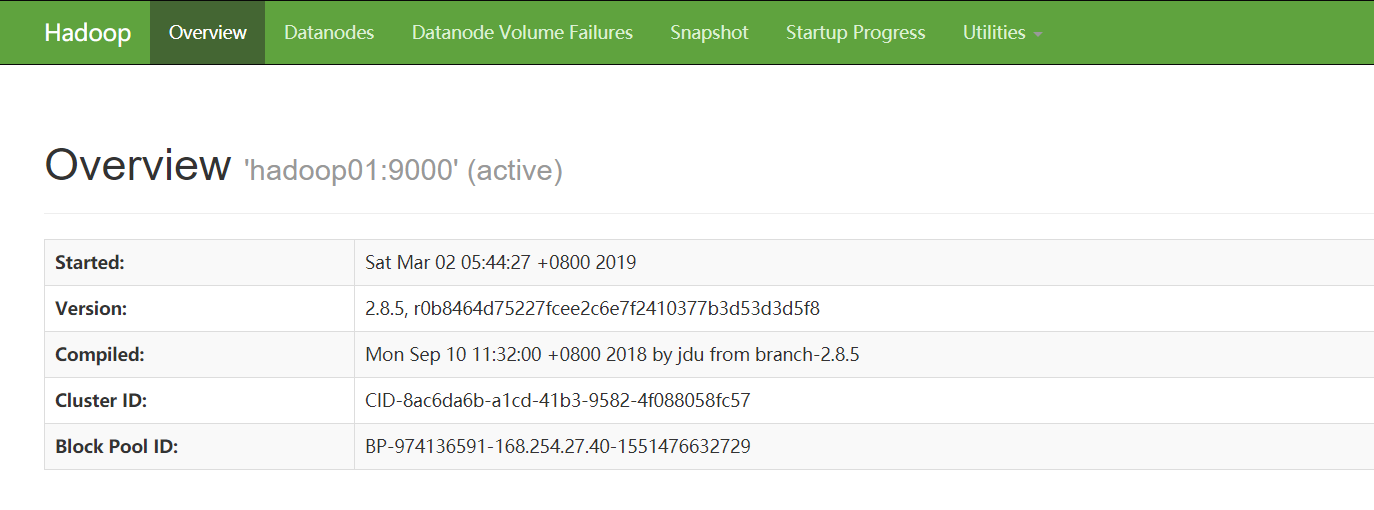
http://192.168.35.100:8088 (MR管理界面)

3、配置ssh免登陆
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id localhost
到此HDFS和MapReduce搭建完成,有任何出错或疑问可以私信留言也可以关注微信公众号;关于Hadoop的后续还会陆续给大家一一讲解,谢谢阅读。

Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)的更多相关文章
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0
公司平台的分布式文件系统基于Hadoop HDFS技术构建,为开发人员学习及后续项目中Hadoop HDFS相关操作提供技术参考特编写此文档.本文档描述了Linux单机环境下Hadoop HDFS伪分 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- Hadoop伪分布式集群
一.HDFS伪分布式环境搭建 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时, ...
随机推荐
- maven jstl、jsp、servlet依赖
jstl.jsp.servlet依赖 <dependency> <groupId>javax.servlet</groupId> <artifactId> ...
- 3org.springframework.beans.factory.BeanDefinitionStoreException异常
1.下面是我遇到的异常信息: 2017-03-25 18:01:11,322 [localhost-startStop-1][org.springframework.web.context.Conte ...
- zTree实现权限列表简单实例
zTree的简单实例 zTree 是一个依靠jQuery 实现的多功能 "树插件".优异的性能.灵活的配置.多种功能的组合是 zTree 最大优点. zTree官网 zTreeAP ...
- 产品经理都知道MVP,但是它可能不再是产品研发最好的模型了
产品经理都知道MVP,但是它可能不再是产品研发最好的模型了 孟小白Aspire • 2017-09-01 • 汽车交通 要简单.讨喜.完整,不要最小可行性产品.这对创业公司的第一个产品来说很重要. M ...
- windows zend_guard+apache no ssl+php no Thread Safe fastcgi模式 环境配置
最近公司要做代码加密,就采用ZEND GUARD 方式加密代码 并进行显示 此文为总结,以备自己以后查看和给需要的同学们参考 采用的php为5.3版本 由于现在加密的更改, 能支持zend guar ...
- Oracle EBS 多节点停应用
adstpall.sh -mode=allnodes app/apps
- mongodb存储引擎
存储引擎(Storage Engine)是MongoDB的核心组件,负责管理数据如何存储在硬盘(Disk)和内存(Memory)上.从MongoDB 3.2 版本开始,MongoDB 支持多数据存储引 ...
- [控件] GlowView
GlowView 效果 说明 这是本人第二次写辉光view了,这是改进版本 源码 https://github.com/YouXianMing/UI-Component-Collection // / ...
- openweathermap-免费的天气预报接口
openweathermap-免费的天气预报接口 其官方网址为:http://www.openweathermap.org/api 静态截图: 具备以下的一些特点: 1. Current weathe ...
- 阿里云MaxCompute被Forrester评为全球云端数据仓库领导者
参考消息网3月19日报道 日前,全球权威调研机构佛瑞斯特研究公司(Forrester)发布<2018年一季度云端数据仓库>报告.报告对大数据服务商的主要功能.区域表现.细分市场和典型客户等 ...