GlusterFS分布式存储集群-1. 部署
参考文档:
- Quick Start Guide:http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Quickstart/
- Install-Guide:https://docs.gluster.org/en/latest/Install-Guide/Install/
- CentOS gluster-Quickstart:https://wiki.centos.org/SpecialInterestGroup/Storage/gluster-Quickstart
- Type of Volumes:https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/#types-of-volumes
- Setting up GlusterFS Volumes:https://docs.gluster.org/en/latest/Administrator%20Guide/Setting%20Up%20Volumes/
- 脑裂:https://docs.gluster.org/en/latest/Administrator%20Guide/Split%20brain%20and%20ways%20to%20deal%20with%20it/
一.Glusterfs框架
Glusterfs(Gluster file system)是开源的,具有强大横向扩展能力的(scale-out),分布式的,可将来自多个服务器的存储资源通过tcp/ip或infiniBand RDMA 网络整合到一个统一的全局命名空间中的文件系统。
1. 框架
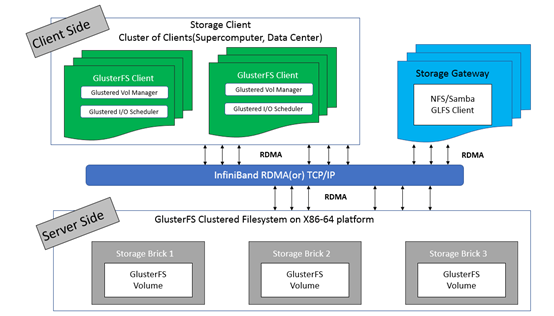
- GlusterFS主要由存储服务器(Brick Server)、客户端以及 NFS/Samba 存储网关组成;
- 架构中无元数据服务器组件,无对于提升整个系统的性单点故障和性能瓶颈问题,可提高系统扩展性、性能、可靠性和稳定性;
- GlusterFS支持 TCP/IP 和 InfiniBand RDMA 高速网络互联;
- 客户端可通过原生 GlusterFS 协议访问数据,其他没有运行 GlusterFS 客户端的终端可通过 NFS/CIFS 标准协议通过存储网关访问数据(存储网关提供弹性卷管理和访问代理功能);
- 存储服务器主要提供基本的数据存储功能,客户端弥补了没有元数据服务器的问题,承担了更多的功能,包括数据卷管理、I/O 调度、文件定位、数据缓存等功能,利用 FUSE(File system in User Space)模块将 GlusterFS 挂载到本地文件系统之上,实现 POSIX 兼容的方式来访问系统数据。
2. 常见术语
- Brick:GlusterFS中最基本的存储单元,表示为受信存储池(trusted storage pool)中输出的目录,供客户端挂载用,可以通过主机名与目录名来标识,如'SERVER:EXPORT';
- Volume:卷,逻辑上由N个brick组成;
- FUSE:Unix-like OS上的可动态加载的模块,允许用户不用修改内核即可创建自己的文件系统;
- Glusterd:Gluster management daemon,在trusted storage pool中所有的服务器上运行;
- Volfile:Glusterfs进程的配置文件,通常是位于/var/lib/glusterd/vols/目录下的{volname}文件;
- Self-heal:用于后台运行检测复本卷中文件与目录的不一致性并解决这些不一致;
- Split-brain:脑裂;
- GFID:GlusterFS卷中的每个文件或目录都有一个唯一的128位的数据相关联,用于模拟inode;
- Namespace:每个Gluster卷都导出单个ns作为POSIX的挂载点。
3. 数据访问流程

- 在客户端,用户通过 glusterfs的mount point读写数据;
- 用户的这个操作被递交给本地 Linux 系统的VFS 来处理;
- VFS 将数据递交给 FUSE 内核文件系统(在启动 glusterfs 客户端以前,需要向系统注册一个实际的文件系统 FUSE),该文件系统与 ext3 在同一个层次, ext3 是对实际的磁盘进行处理,而 fuse 文件系统则是将数据通过 /dev/fuse 这个设备文件递交给了glusterfs client 端,可以将 fuse 文件系统理解为一个代理;
- 数据被 fuse 递交给 Glusterfs client 后, client 对数据进行一些指定的处理(即按 client 配置文件来进行的一系列处理);
- 在 glusterfs client 的处理末端,通过网络将数据递交给 Glusterfs Server, 并且将数据写入到服务器所控制的存储设备上。
二.环境
1. 环境规划
|
Hostname |
IP |
Service |
Remark |
|
glusterfs-client |
172.30.200.50 |
glusterfs(3.12.9) glusterfs-fuse |
客户端 |
|
glusterfs01 |
172.30.200.51 |
glusterfs(3.12.9) glusterfs-server(3.12.9) glusterfs-fuse |
服务器端 |
|
glusterfs02 |
172.30.200.52 |
glusterfs(3.12.9) glusterfs-server(3.12.9) glusterfs-fuse |
服务器端 |
|
glusterfs03 |
172.30.200.53 |
glusterfs(3.12.9) glusterfs-server(3.12.9) glusterfs-fuse |
服务器端 |
|
glusterfs04 |
172.30.200.54 |
glusterfs(3.12.9) glusterfs-server(3.12.9) glusterfs-fuse |
服务器端 |
2. 设置hosts
# 所有节点保持一致的hosts即可,以gluster01节点为例;
# 绑定hosts不是必须的,后续组建受信存储池也可使用ip的形式
[root@glusterfs01 ~]# vim /etc/hosts
# glusterfs
172.30.200.50 glusterfs-client
172.30.200.51 glusterfs01
172.30.200.52 glusterfs02
172.30.200.53 glusterfs03
172.30.200.54 glusterfs04 [root@glusterfs01 ~]# cat /etc/hosts

3. 设置ntp
# 至少4个Brick Server节点需要保持时钟同步(重要),以glusterfs01节点为例
[root@glusterfs01 ~]# yum install chrony -y # 编辑/etc/chrony.conf文件,设置”172.20.0.252”为时钟源;
[root@glusterfs01 ~]# egrep -v "^$|^#" /etc/chrony.conf
server 172.20.0.252 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
logdir /var/log/chrony # 设置开机启动,并重启
[root@glusterfs01 ~]# systemctl enable chronyd.service
[root@glusterfs01 ~]# systemctl restart chronyd.service # 查看状态
[root@glusterfs01 ~]# systemctl status chronyd.service
[root@glusterfs01 ~]# chronyc sources -v
4. 设置glusterfs packages
# 全部节点安装glusterfs yum源
[root@glusterfs01 ~]# yum install -y centos-release-gluster # 查看
[root@glusterfs01 ~]# yum repolist
5. 设置iptables
# 提前统一设置iptables(至少4个Brick Server节点),以glusterfs01节点为例;
# 初始环境已使用iptables替代centos7.x自带的firewalld,同时关闭selinux;
[root@glusterfs01 ~]# vim /etc/sysconfig/iptables
# tcp24007:24008:glusterfsd daemon management服务监听端口;
# tcp49152:49160:3.4版本之后(之前的版本的起始端口是24009),启动1个brick,即启动1个监听端口,起始端口为49152,依次类推,如这里设置49152:49160,可开启9个brick;
# 另如果启动nfs server,需要开启38465:38467,111等端口
-A INPUT -p tcp -m state --state NEW -m tcp --dport 24007:24008 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 49152:49160 -j ACCEPT [root@glusterfs01 ~]# service iptables restart
三.设置glusterfs
1. mount brick
1)创建分区
# 各brick server的磁盘挂载前需要创建分区并格式化,以glusterfs01节点为例;
# 将整个/dev/sdb磁盘设置为1个分区,分区设置默认即可
[root@glusterfs01 ~]# fdisk /dev/sdb
Command (m for help): n
Select (default p):
Partition number (1-4, default 1):
First sector (2048-209715199, default 2048):
Last sector, +sectors or +size{K,M,G} (2048-209715199, default 209715199):
Command (m for help): w # 查看
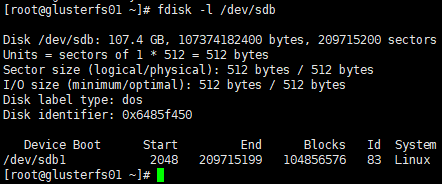
[root@glusterfs01 ~]# fdisk -l /dev/sdb
2)格式化分区
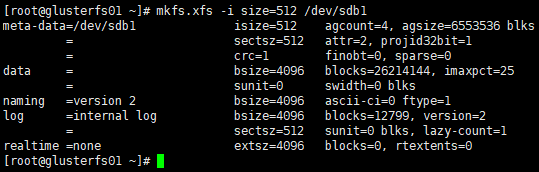
[root@glusterfs01 ~]# mkfs.xfs -i size=512 /dev/sdb1
3)挂载分区
# 创建挂载目录,目录名自定义;
# 这里为区分,可以将4个server节点的目录名按顺序命名(非必须)
[root@glusterfs01 ~]# mkdir -p /brick1
[root@glusterfs02 ~]# mkdir -p /brick2
[root@glusterfs03 ~]# mkdir -p /brick3
[root@glusterfs04 ~]# mkdir -p /brick4 # 修改/etc/fstab文件,以glusterfs01节点为例,注意其余3各节点挂载点目录名不同;
# 第一栏:设备装置名;
# 第二栏:挂载点;
# 第三栏:文件系统;
# 第四栏:文件系统参数,默认情况使用 defaults 即可,同时具有 rw, suid, dev, exec, auto, nouser, async 等参数;
# 第五栏:是否被 dump 备份命令作用,"0"代表不做 dump 备份; "1"代表要每天进行 dump; "2"代表其他不定日期的 dump; 通常设置"0" 或者"1";
# 第六栏:是否以 fsck 检验扇区,启动过程中,系统默认会以 fsck 检验 filesystem 是否完整 (clean), 但某些 filesystem 是不需要检验的,如swap;"0"是不要检验,"1"表示最早检验(一般只有根目录会配置为 "1"),"2"是检验,但晚于"1";通常根目录配置为"1" ,其余需要要检验的 filesystem 都配置为"2";
[root@glusterfs01 ~]# echo "/dev/sdb1 /brick1 xfs defaults 1 2" >> /etc/fstab # 挂载并展示
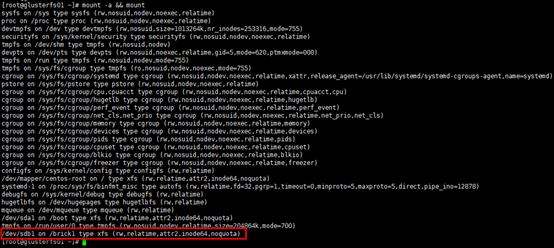
[root@glusterfs01 ~]# mount -a && mount
2. 启动glusterfs-server
1)安装glusterfs-server
# 在4个brick server节点安装glusterfs-server,以glusterfs01节点为例
[root@glusterfs01 ~]# yum install -y glusterfs-server
2)启动glusterfs-server
[root@glusterfs01 ~]# systemctl enable glusterd
[root@glusterfs01 ~]# systemctl restart glusterd # 查看状态
[root@glusterfs01 ~]# systemctl status glusterd
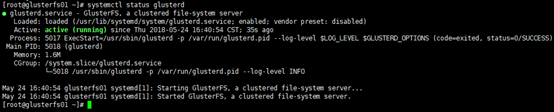
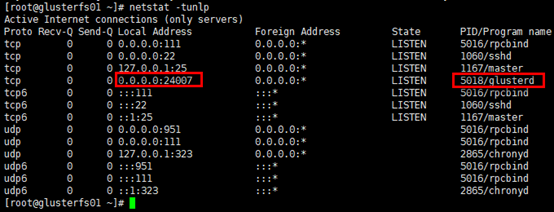
# 查看服务监听端口
[root@glusterfs01 ~]# netstat -tunlp
3. 组建受信存储池
受信存储池(trusted storage pools),是1个可信的网络存储服务器,为卷提供brick,可以理解为集群。
# 在任意一个server节点组建受信存储池均可,即由任意节点邀请其他节点组建存储池;
# 组建时,做为”邀请者”,不需要再加入本节点;
# 使用ip或dns主机名解析都可以,这里已在hosts文件绑定主机,采用主机名;
# 从集群移除节点:gluster peer detach <ip or hostname>
[root@glusterfs01 ~]# gluster peer probe glusterfs02
[root@glusterfs01 ~]# gluster peer probe glusterfs03
[root@glusterfs01 ~]# gluster peer probe glusterfs04
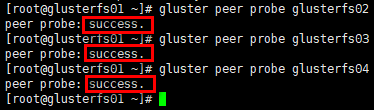
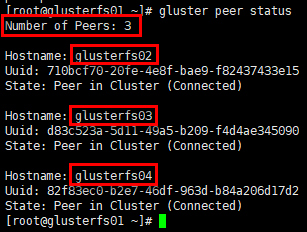
# 查看受信存储池状态;
# 在glusterfs01节点查看集群状态,不会list出本节点,只展示peers
[root@glusterfs01 ~]# gluster peer status
4. 设置glusterfs-client
# 客户端主要安装两个组件,glusterfs与glusterfs-fuse;
# glusterfs-client具备如数据卷管理、I/O 调度、文件定位、数据缓存等功能;
# glusterfs-fuse将远端glusterfs挂载到本地文件系统,可通过”modinfo fuse”,“ll /dev/fuse”等命令查看
[root@glusterfs-client ~]# yum install -y glusterfs glusterfs-fuse
GlusterFS分布式存储集群-1. 部署的更多相关文章
- Centos7下GlusterFS分布式存储集群环境部署记录
0)环境准备 GlusterFS至少需要两台服务器搭建,服务器配置最好相同,每个服务器两块磁盘,一块是用于安装系统,一块是用于GlusterFS. 192.168.10.239 GlusterFS-m ...
- GlusterFS分布式存储集群部署记录-相关补充
接着上一篇Centos7下GlusterFS分布式存储集群环境部署记录文档,继续做一些补充记录,希望能加深对GlusterFS存储操作的理解和熟悉度. ======================== ...
- GlusterFS分布式存储集群-2. 使用
参考文档: Quick Start Guide:http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Quickstart/ Instal ...
- Ceph分布式存储集群-硬件选择
在规划Ceph分布式存储集群环境的时候,对硬件的选择很重要,这关乎整个Ceph集群的性能,下面梳理到一些硬件的选择标准,可供参考: 1)CPU选择Ceph metadata server会动态的重新分 ...
- 简单介绍Ceph分布式存储集群
在规划Ceph分布式存储集群环境的时候,对硬件的选择很重要,这关乎整个Ceph集群的性能,下面梳理到一些硬件的选择标准,可供参考: 1)CPU选择 Ceph metadata server会动态的重新 ...
- Redis——(主从复制、哨兵模式、集群)的部署及搭建
Redis--(主从复制.哨兵模式.集群)的部署及搭建 重点: 主从复制:主从复制是高可用redis的基础,主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复. 哨兵和集群都是 ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- JStorm集群的部署
JStorm是一个类似Hadoop MapReduce的系统,不同的是JStorm是一套基于流水线的消息处理机制,是阿里基于Storm优化的版本,和Storm一样是一个分布式实时计算的系统,从开发角度 ...
- Redis集群的部署
Redis集群分为主节点Master和从节点Slave,主节点只有1个,而从节点可以有多个,这样从节点和主节点可以进行数据的传输,Redis集群的性能将比单机环境更高,接下来是配置的过程 首先配置Ma ...
随机推荐
- MySQL 导出远程服务器数据库 为 sql文件
MySQL 导出远程服务器sql文件 mysqldump -h192.168.1.111 –P3306 -uroot -ppassword --default-character-set=utf8 t ...
- [HNOI2003]操作系统
嘟嘟嘟 这道题就是一个模拟. 首先我们建一个优先队列,存所有等待的进程,当然第一关键字是优先级从大到小,第二关键字是到达时间从小到大.然后再建一个指针Tim,代表cpu运行的绝对时间. 然后分一下几种 ...
- ElasticSearch 获取es信息以及索引操作
检查集群的健康情况 GET /_cat/health?v green:每个索引的primary shard和replica shard都是active状态的yellow:每个索引的primary sh ...
- php后台+前端开发过程整理
一.PHP后台从数据库中获取数据 1. 建立数据库连接: //在本项目中封装了数据库的各种操作 $dbConn = $this->_createMysqlConn(); 2. 执行sql语句 $ ...
- gulp插件(8) - gulp-sourcemaps(生成sourcemap)
功能描述生成sourcemap文件(什么是sourcemap?请参考,简单讲就是文件压缩后不利于查看与调试,但是有了sourcemap,出错的时候,除错工具将直接显示原始代码,而不是转换后的代码) 插 ...
- VSC 插件开发从入门到Hello World
1.原理放一边,我们先来个Hello,World 1.1 安装基础环境 需要的基础环境列表: Node.js npm vs code yo generator-code yo:全称Yeoman,可以把 ...
- 【jq】JQuery对select的操作
下拉框 <select id="selectID" name="selectName"> <option vlaue="1" ...
- GoogleTest初探(1)
此篇主要了解一下GoogleTest中的断言. 总的来说,GoogleTest中的断言分为两大类:EXPECT_*和ASSERT_*,这两者在测试成功或失败后均会给出测试报告,区别是前者在测试失败后会 ...
- jQuery----左侧导航栏面板切换实现
页面运行结果: 点击曹操 点击刘备 点击孙权 原图 需求说明:原图如上所示,点击一方诸侯的时候 ...
- h5声音录制/播放
html代码: <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" ...