机器学习--boosting家族之GBDT
本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 以下简称GBDT)做一个总结。GBDT有很多简称,有GBT(Gradient Boosting Tree), GTB(Gradient Tree Boosting ), GBRT(Gradient Boosting Regression Tree), MART(Multiple Additive Regression Tree),其实都是指的同一种算法,本文统一简称GBDT。GBDT在BAT大厂中也有广泛的应用,假如要选择3个最重要的机器学习算法的话,个人认为GBDT应该占一席之地。
1. GBDT概述
GBDT也是集成学习Boosting家族的成员,但是却和传统的Adaboost有很大的不同。回顾下Adaboost,我们是利用前一轮迭代弱学习器的误差率来更新训练集的权重,这样一轮轮的迭代下去。GBDT也是迭代,使用了前向分布算法,但是弱学习器限定了只能使用CART回归树模型,同时迭代思路和Adaboost也有所不同。
在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是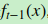 , 损失函数是
, 损失函数是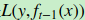 , 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器
, 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器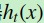 ,让本轮的损失损失
,让本轮的损失损失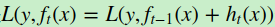 最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
从上面的例子看这个思想还是蛮简单的,但是有个问题是这个损失的拟合不好度量,损失函数各种各样,怎么找到一种通用的拟合方法呢?
2. GBDT的负梯度拟合
必须要澄清的误区:提起决策树(DT, Decision Tree) 绝大部分人首先想到的就是C4.5分类决策树。但如果一开始就把GBDT中的树想成分类树,那就是一条歪路走到黑,一路各种坑,最终摔得都要咯血了还是一头雾水,所以说千万不要以为GBDT是很多棵分类树。决策树分为两大类,回归树和分类树。前者用于预测实数值,如明天的温度、用户的年龄、网页的相关程度;后者用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。这里要强调的是,前者的结果加减是有意义的,如10岁+5岁-3岁=12岁,后者则无意义,如 男+男+女=到底是男是女? GBDT的核心在于累加所有树的结果作为最终结果,每棵树学的是之前所有树结论和的残差。这也就是“Boost”思想的应用,就像前面对年龄的累加(-3是加负3),而分类树的结果显然是没办法累加的,所以GBDT中的树都是回归树,不是分类树,这点对理解GBDT相当重要(尽管GBDT调整后也可用于分类但不代表GBDT的树是分类树)。
这里的残差是怎样计算的呢??所以“G” 就派上用场了,也就是梯度下降思想。梯度下降作用的是损失函数,使其损失函数迭代到极小值。在GBDT 中处理不同的问题,其损失函数是不一样的。
在上一节中,我们介绍了GBDT的基本思路,但是没有解决损失函数拟合方法的问题。针对这个问题,大牛Freidman提出了用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树。第t轮的第i个样本的损失函数的负梯度表示为

利用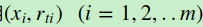 ,我们可以拟合一颗CART回归树,得到了第t颗回归树,其对应的叶节点区域
,我们可以拟合一颗CART回归树,得到了第t颗回归树,其对应的叶节点区域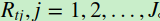 。其中J为叶子节点的个数。
。其中J为叶子节点的个数。
针对每一个叶子节点里的样本,我们求出使损失函数最小,也就是拟合叶子节点最好的的输出值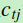 如下:
如下:
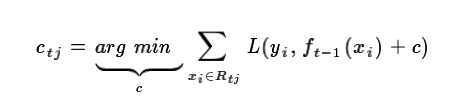
这样我们就得到了本轮的决策树拟合函数如下:
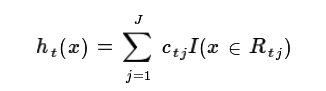
从而本轮最终得到的强学习器的表达式如下:

通过损失函数的负梯度来拟合,我们找到了一种通用的拟合损失误差的办法,这样无轮是分类问题还是回归问题,我们通过其损失函数的负梯度的拟合,就可以用GBDT来解决我们的分类回归问题。区别仅仅在于损失函数不同导致的负梯度不同而已。
3. GBDT回归算法
好了,有了上面的思路,下面我们总结下GBDT的回归算法。为什么没有加上分类算法一起?那是因为分类算法的输出是不连续的类别值,需要一些处理才能使用负梯度,我们在下一节讲。
输入是训练集样本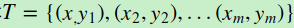 , 最大迭代次数T, 损失函数L。
, 最大迭代次数T, 损失函数L。
输出是强学习器f(x)
1) 初始化弱学习器

2) 对迭代轮数t=1,2,...T有:
a)对样本i=1,2,...m,计算负梯度
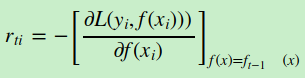
b)利用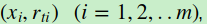 拟合一颗CART回归树,得到第t颗回归树,其对应的叶子节点区域为
拟合一颗CART回归树,得到第t颗回归树,其对应的叶子节点区域为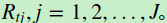
其中J为回归树t的叶子节点的个数。
c) 对叶子区域j =1,2,..J,计算最佳拟合值
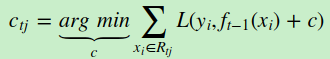
d) 更新强学习器
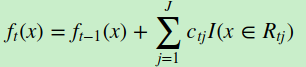
3) 得到强学习器f(x)的表达式

4. GBDT分类算法
这里我们再看看GBDT分类算法,GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。
为了解决这个问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法是用类似于逻辑回归的对数似然损失函数的方法。也就是说,我们用的是类别的预测概率值和真实概率值的差来拟合损失。本文仅讨论用对数似然损失函数的GBDT分类。而对于对数似然损失函数,我们又有二元分类和多元分类的区别。
4.1 二元GBDT分类算法
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数为:
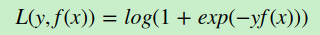
其中y∈{−1,+1}。则此时的负梯度误差为
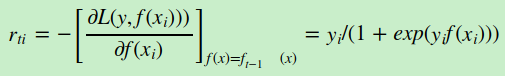
对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
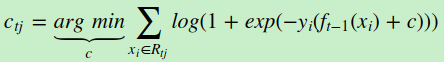
由于上式比较难优化,我们一般使用近似值代替
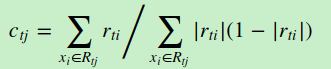
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,二元GBDT分类和GBDT回归算法过程相同。
4.2 多元GBDT分类算法
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假设类别数为K,则此时我们的对数似然损失函数为:
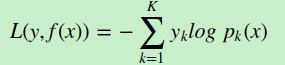
其中如果样本输出类别为k,则 。第k类的概率
。第k类的概率 的表达式为:
的表达式为:
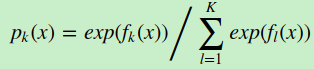
集合上两式,我们可以计算出第tt轮的第ii个样本对应类别ll的负梯度误差为
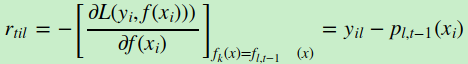
观察上式可以看出,其实这里的误差就是样本ii对应类别ll的真实概率和t−1轮预测概率的差值。
对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
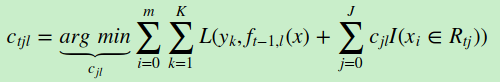
由于上式比较难优化,我们一般使用近似值代替
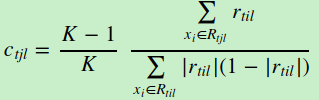
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。
5. GBDT常用损失函数
这里我们再对常用的GBDT损失函数做一个总结。
对于分类算法,其损失函数一般有对数损失函数和指数损失函数两种:
a) 如果是指数损失函数,则损失函数表达式为
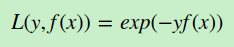
其负梯度计算和叶子节点的最佳残差拟合参见Adaboost原理篇。
b) 如果是对数损失函数,分为二元分类和多元分类两种,参见4.1节和4.2节。
对于回归算法,常用损失函数有如下4种:
a)均方差,这个是最常见的回归损失函数了
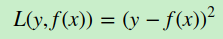
b)绝对损失,这个损失函数也很常见
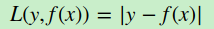
对应负梯度误差为:
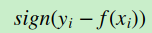
c) Huber损失,它是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下:
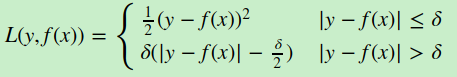
对应的负梯度误差为:
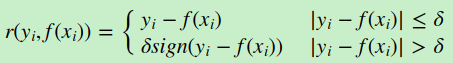
d) 分位数损失。它对应的是分位数回归的损失函数,表达式为

其中θ为分位数,需要我们在回归前指定。对应的负梯度误差为:
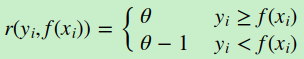
对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
6. GBDT的正则化
和Adaboost一样,我们也需要对GBDT进行正则化,防止过拟合。GBDT的正则化主要有三种方式。
第一种是和Adaboost类似的正则化项,即步长(learning rate)。定义为νν,对于前面的弱学习器的迭代
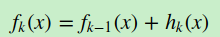
如果我们加上了正则化项,则有
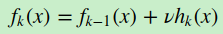
ν的取值范围为0<ν≤10<ν≤1。对于同样的训练集学习效果,较小的νν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
第二种正则化的方式是通过子采样比例(subsample)。取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。
使用了子采样的GBDT有时也称作随机梯度提升树(Stochastic Gradient Boosting Tree, SGBT)。由于使用了子采样,程序可以通过采样分发到不同的任务去做boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。
第三种是对于弱学习器即CART回归树进行正则化剪枝。在决策树原理篇里我们已经讲过,这里就不重复了。
7. GBDT小结
GBDT终于讲完了,GDBT本身并不复杂,不过要吃透的话需要对集成学习的原理,决策树原理和各种损失函树有一定的了解。由于GBDT的卓越性能,只要是研究机器学习都应该掌握这个算法,包括背后的原理和应用调参方法。目前GBDT的算法比较好的库是xgboost。当然scikit-learn也可以。
最后总结下GBDT的优缺点。
GBDT主要的优点有:
1) 可以灵活处理各种类型的数据,包括连续值和离散值。
2) 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
参考:
1、https://www.cnblogs.com/pinard/p/6140514.html
2、https://blog.csdn.net/zbj366112/article/details/70037865
机器学习--boosting家族之GBDT的更多相关文章
- 机器学习--boosting家族之XGBoost算法
一.概念 XGBoost全名叫(eXtreme Gradient Boosting)极端梯度提升,经常被用在一些比赛中,其效果显著.它是大规模并行boosted tree的工具,它是目前最快最好的开源 ...
- 机器学习--boosting家族之Adaboost算法
最近在系统研究集成学习,到Adaboost算法这块,一直不能理解,直到看到一篇博文,才有种豁然开朗的感觉,真的讲得特别好,原文地址是(http://blog.csdn.net/guyuealian/a ...
- 机器学习算法总结(四)——GBDT与XGBOOST
Boosting方法实际上是采用加法模型与前向分布算法.在上一篇提到的Adaboost算法也可以用加法模型和前向分布算法来表示.以决策树为基学习器的提升方法称为提升树(Boosting Tree).对 ...
- Boosting Ensemble and GBDT Algorithm
Boosting Ensemble: 机器学习中,Ensemble model除了Bagging以外,更常用的是Boosting.与Bagging不同,Boosting中各个模型是串行的.其思想是,后 ...
- [机器学习]梯度提升决策树--GBDT
概述 GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由 ...
- Boosting决策树:GBDT
GBDT (Gradient Boosting Decision Tree)属于集成学习中的Boosting流派,迭代地训练基学习器 (base learner),当前基学习器依赖于上一轮基学习器的学 ...
- 机器学习(八)—GBDT 与 XGBOOST
RF.GBDT和XGBoost都属于集成学习(Ensemble Learning),集成学习的目的是通过结合多个基学习器的预测结果来改善单个学习器的泛化能力和鲁棒性. 根据个体学习器的生成方式,目前 ...
- 机器学习—集成学习(GBDT)
一.原理部分: 图片形式~ 二.sklearn实现: 可以看看这个:https://blog.csdn.net/han_xiaoyang/article/details/52663170 1.分类: ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
随机推荐
- Codeforces 632D Longest Subsequence 2016-09-28 21:29 37人阅读 评论(0) 收藏
D. Longest Subsequence time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- JProfiler 简要使用说明
1.简介 JProfiler是一个ALL-IN-ONE的JAVA剖析工具,可以方便地监控Java程序的CPU.内存使用状况,能够检查垃圾回收.分析性能瓶颈. 本说明文档基于JProfiler 9.2编 ...
- Python学习-17.Python中的错误处理(二)
错误是多种多样的,在 except 语句中,可以捕获指定的异常 修改代码如下: import io path = r'' mode = 'w' try: file = open(path,mode) ...
- [微信开发] 微信网页授权Java实现
功能:主要用于在用户通过手机端微信访问第三方H5页面时获取用户的身份信息(openId,昵称,头像,所在地等..)可用来实现微信登录.微信账号绑定.用户身份鉴权等功能. 开发前的准备: 1.需 ...
- Could not load file or assembly '$SharePoint.Project.AssemblyFullName$'
The fix is simple, do the following: 1. Open your project file in NotePad 2. Find the PropertyGrou ...
- day 104 luffy项目第二天
一.前端配置 二.后端配置 一.前端配置 app.vue 二 . 后端配置 model模型配置 迁移数据 序列化 views.py文件配置 url路由 配置中间件解决跨域问题 重新设计下 model模 ...
- Day 42 协程. IO 并发
一.什么是协程? 是单线程下的并发,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的. 协程相比于线程切换效率更快了. ...
- 《Python绝技:运用Python成为顶级黑客》 用Python分析网络流量
1.IP流量将何去何从?——用Python回答: 使用PyGeoIP关联IP地址和物理地址: 需要下载安装pygeoip,可以pip install pygeoip 或者到Github上下载安装htt ...
- BZOJ 5395--[Ynoi2016]谁的梦(STL&容斥)
5395: [Ynoi2016]谁的梦 Time Limit: 80 Sec Memory Limit: 128 MBSubmit: 22 Solved: 7[Submit][Status][Di ...
- fastAdmin根据状态显示是否显示操作按钮
根据状态决定是否显示某个操作按钮 代码如下: