[论文理解] CBAM: Convolutional Block Attention Module
CBAM: Convolutional Block Attention Module
简介
本文利用attention机制,使得针对网络有了更好的特征表示,这种结构通过支路学习到通道间关系的权重和像素间关系的权重,然后乘回到原特征图,使得特征图可以更好的表示。
Convolutional Block Attention Module
这里的结构有点类似与SENet里的支路结构。
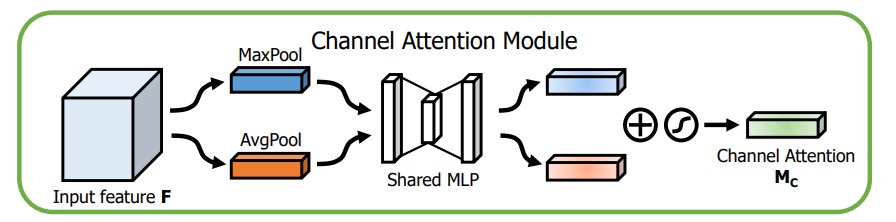
对于Channel attention module,先将原feature map分别做global avg pooling 和global max pooling,然后将两pooling后的向量分别连接一个FC层,之后point-wise相加。激活。
这里用global pooling的作用是捕捉全局特征,因为得到的权重描述的是通道间的关系,所以必须要全局特征才能学习到这种关系。
之所以avg pooling和max pooling一起用,是因为作者发现max pooling能够捕捉特征差异,avg pooling能捕捉一般信息,两者一起用的效果要比单独用的实验结果要好,。
结构如图:
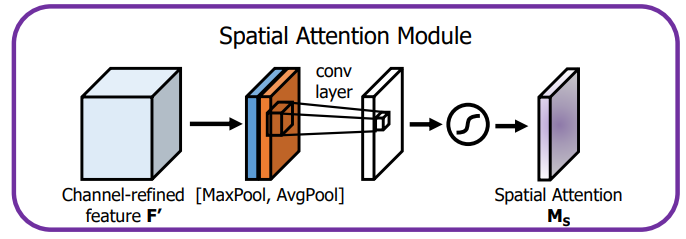
对于Spatial attention module,作者使用了1×1的pooling,与上面一样,使用的是1×1的avg pooling和1×1的max pooling,而没有用1×1卷积,两者concat,紧接着是一层7×7卷积,然后激活。最后输出就是1×h×w。
结构如图:
作者提到了两者的顺序,先做channel attention比先做spatial attention要好很多。
后面作者实验了spatial attention module里1×1conv、1×1pooling的效果,最后发现pooing的效果要比卷积的效果要好,因此上面的结构采用的是pooling而不是卷积结构。
后面就是一些结构了。
几句话简单复现了一下。
'''
@Descripttion: This is Aoru Xue's demo,which is only for reference
@version:
@Author: Aoru Xue
@Date: 2019-09-12 01:24:03
@LastEditors: Aoru Xue
@LastEditTime: 2019-09-12 02:24:25
'''
import torch
import torch.nn as nn
class ChannelAttentionModule(nn.Module):
def __init__(self,size = 128,r = 2):
super(ChannelAttentionModule, self).__init__()
self.max_pooling = nn.MaxPool2d(size)
self.avg_pooling = nn.AvgPool2d(size)
self.fc1 = nn.Linear(64,64//r)
self.fc2 = nn.Linear(64//r,64)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
max_pool = self.max_pooling(x).view(2,64)
max_pool = self.fc1(max_pool)
avg_pool = self.avg_pooling(x).view(2,64)
avg_pool = self.fc1(avg_pool)
t = max_pool + avg_pool
x = self.fc2(t).view(2,64,1,1)
x = self.relu(x)
return x
class SpatialAttentionModule(nn.Module):
def __init__(self,):
super(SpatialAttentionModule, self).__init__()
self.conv7x7 = nn.Conv2d(2,64,kernel_size= 7 , stride=1,padding = 3)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
max_pool = torch.max(x,dim = 1)[0]
avg_pool = torch.mean(x,dim = 1)
x = self.conv7x7(torch.stack([max_pool,avg_pool],dim = 1))
x = self.sigmoid(x)
return x
class ResBlock(nn.Module):
def __init__(self,):
super(ResBlock, self).__init__()
self.channel_module = ChannelAttentionModule(r = 2)
self.spatial_module = SpatialAttentionModule()
def forward(self,x):
inpt = x
c = self.channel_module(x)
x = c*x
s = self.spatial_module(x)
x = s * x
return inpt + x
if __name__ == "__main__":
x = torch.randn(2,64,128,128)
net = ResBlock()
print(net(x).size())
[论文理解] CBAM: Convolutional Block Attention Module的更多相关文章
- 【论文笔记】CBAM: Convolutional Block Attention Module
CBAM: Convolutional Block Attention Module 2018-09-14 21:52:42 Paper:http://openaccess.thecvf.com/co ...
- CBAM: Convolutional Block Attention Module
1. 摘要 作者提出了一个简单但有效的注意力模块 CBAM,给定一个中间特征图,我们沿着空间和通道两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整. 由于 CBAM 是一个轻量级 ...
- CBAM(Convolutional Block Attention Module)使用指南
转自知乎 这货就是基于 SE-Net [5]中的 Squeeze-and-Excitation module 来进行进一步拓展 具体来说,文中把 channel-wise attention 看成是教 ...
- [论文理解] Receptive Field Block Net for Accurate and Fast Object Detection
Receptive Field Block Net for Accurate and Fast Object Detection 简介 本文在SSD基础上提出了RFB Module,利用神经科学的先验 ...
- [论文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 这是一篇2016年的目标检测 ...
- Deep Learning 33:读论文“Densely Connected Convolutional Networks”-------DenseNet 简单理解
一.读前说明 1.论文"Densely Connected Convolutional Networks"是现在为止效果最好的CNN架构,比Resnet还好,有必要学习一下它为什么 ...
- RAM: Residual Attention Module for Single Image Super-Resolution
1. 摘要 注意力机制是深度神经网络的一个设计趋势,其在各种计算机视觉任务中都表现突出.但是,应用到图像超分辨领域的注意力模型大都没有考虑超分辨和其它高层计算机视觉问题的天然不同. 作者提出了一个新的 ...
- [论文理解]关于ResNet的进一步理解
[论文理解]关于ResNet的理解 这两天回忆起resnet,感觉残差结构还是不怎么理解(可能当时理解了,时间长了忘了吧),重新梳理一下两点,关于resnet结构的思考. 要解决什么问题 论文的一大贡 ...
- 论文笔记之:Deep Attention Recurrent Q-Network
Deep Attention Recurrent Q-Network 5vision groups 摘要:本文将 DQN 引入了 Attention 机制,使得学习更具有方向性和指导性.(前段时间做 ...
随机推荐
- Elasticsearch 7.4.0官方文档操作
官方文档地址 https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html 1.0.0 设置Elasticsea ...
- 2019.9.19HTML基础
html:超文本标记语言,不是编程语言,是标签语言,显示数据. 有双标签和单标签 双标签:有开始有结束,<body></body> 单标签:只有一个.<img src=# ...
- JAVA GUI设
1.两种设置大小的方式: //Border border1=BorderFactory.createEmptyBorder(20,20,20,20); //设置大小 panel.setB ...
- flutter 学习路上碰到的错误问题。
决定还是把碰到的问题进行简单记录吧 19.8.14 错误日志: type '_InternalLinkedHashMap<dynamic, dynamic>' is not a subty ...
- HihoCoder1076 与链(数位DP)
时间限制:24000ms 单点时限:3000ms 内存限制:256MB 描述 给定 n 和 k.计算有多少长度为 k 的数组 a1, a2, ..., ak,(0≤ai) 满足: a1 + a2 + ...
- MAC使用终端DISKUTIL命令给U盘分区(解决window优盘只有200M)
1.先使用diskutil list命令查看U盘代号 2.然后用下面的命令把它格式化: sudo diskutil eraseDisk FAT32 USB_NAME MBRFormat /dev/di ...
- spring容器BeanFactory简单例子
在Spring中,那些组成你应用程序的主体及由Spring Ioc容器所管理的对象,都被称之为bean.简单来讲,bean就是Spring容器的初始化.配置及管理的对象.除此之外,bean就与应用程序 ...
- linux运维、架构之路-K8s通过Service访问Pod
一.通过Service访问Pod 每个Pod都有自己的IP地址,当Controller用新的Pod替换发生故障的Pod时,新Pod会分配到新的IP地址,例如:有一组Pod对外提供HTTP服务,它们的I ...
- linux7buffer和cache
现象:作为hdfs集群的主节点,越来越卡 排查:CPU,mem CPU正常,检查内存情况,发现如下 如上截图:发现程序可用内存为91G,但是部分swap分区被占用.于是引出如下思考,free -h这条 ...
- [采坑] VS2015 warning C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失
问题: Visual Studio 2015出现warning C4819: 该文件包含不能在当前代码页(936)中表示的字符.请将该文件保存为 Unicode 格式以防止数据丢失. 解决方案: 1. ...