使用多个梯度下降的方式进行测试,同时使用ops.apply_gradient进行梯度的下降
1. ops = tf.train.GradientDescentOptimizer(learning_rate) 构建优化器
参数说明:learning_rate 表示输入的学习率
2.ops.compute_gradients(loss, tf.train_variables(), colocate_gradients_with_ops=True)
参数说明:loss表示损失值, tf.train_variables() 表示需要更新的参数, colocate_gradients_with_ops= True表示进行渐变的操作
tf.train.GradientDescentOptimizer 梯度下降优化器
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
TRAIN_STEP = 20 data = []
num_data = 1000
for i in range(num_data):
x_data = np.random.normal(0.0, 0.55)
y_data = 0.1 * x_data + 0.3 + np.random.normal(0.0, 0.03)
data.append([x_data, y_data]) # 第二步:将数据进行分配,分成特征和标签
X_data = [v[0] for v in data]
y_data = [v[1] for v in data]
learning_rate_placeholder = 0.5 # 初始学习率
global_step = tf.Variable(0, trainable=False) # 设置初始global_step步数
learning_rate = tf.train.exponential_decay(learning_rate_placeholder, global_step, 15, 0.1, staircase=True)
W = tf.Variable(tf.truncated_normal([1], -1, 1), 'name') # 进行参数初始化操作
b = tf.Variable(tf.zeros([1])) logits = X_data * W + b # 构造拟合函数
loss = tf.reduce_mean(tf.square(y_data - logits)) # 使用平方和来计算损失值
opt = tf.train.GradientDescentOptimizer(learning_rate) # 构造梯度下降优化器
grad = opt.compute_gradients(loss, tf.trainable_variables(), colocate_gradients_with_ops=True) # 计算梯度,这里的trainable_variables()表示所有的参数,这里我们可以使用参数进行finetune操作
grad_opt = opt.apply_gradients(grad, global_step=global_step) # 进行global的迭代更新,同时构造更新梯度的操作
UPDATA_OP = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # 收集之前的操作
with tf.control_dependencies(UPDATA_OP): # 在进行训练操作之前先将保证其它操作做完
train_op = tf.group(grad_opt) # 进行操作的实例化,用于进行参数更新
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 权重参数初始化操作
for i in range(TRAIN_STEP):
sess.run(train_op) # 进行实际的参数更新操作 plt.plot(X_data, y_data, '+') # 画图操作
plt.plot(X_data, X_data*sess.run(W) + sess.run(b), '-')
plt.show()
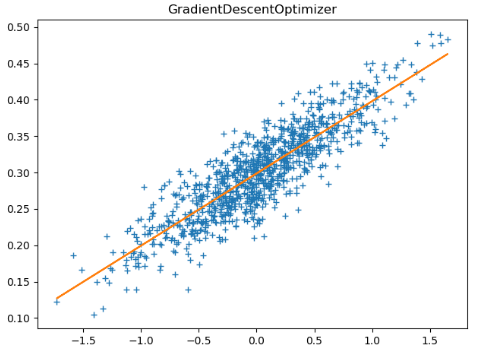
tf.train.AdamOptimizer 自适应学习率梯度下降

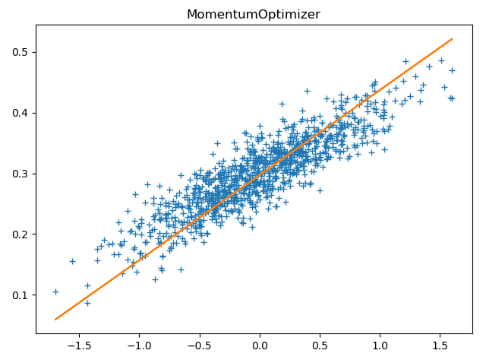
tf.train.MomentumOptimizer(learning_rate, 0.7) 动量梯度下降
原理说明:

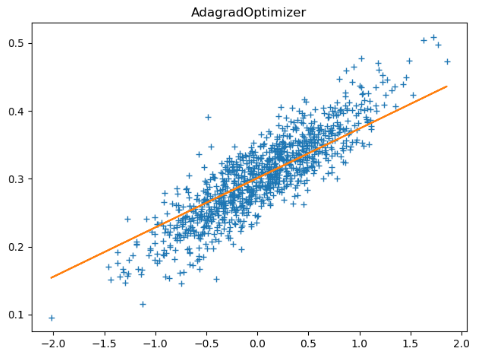
tf.train.AdagradOptimizer Adagra算法的学习率增加
使用多个梯度下降的方式进行测试,同时使用ops.apply_gradient进行梯度的下降的更多相关文章
- OI常用读入方式效率测试
我来填坑了. 这次我用自己写的测试读入的程序来分别测试cin(不关闭流同步),scanf和读入优化的效率差别. 我们分别对三个阶段的数据量n进行测试,通过时间比对来观察性能的差异. n = 102 ...
- redis的list取出数据方式速度测试
redis测试: package business; import java.io.BufferedReader; import java.io.File; import java.io.FileIn ...
- 用ab的post方式进行测试
一.Ab是常用的性能测试工具,因为它支持windows…… 通常使用的命令是ab –c –n –k -r,分别表示:模拟终端数.发送包数.请求是否带keepalive.忽略错误,默认都是以GET方式去 ...
- 转: 将Eclipse代码导入到AndroidStudio的两种方式 ,测试了方法2,成功。
蛋疼,不知道为什么我的eclipse的logcat总是莫名其妙的显示一堆黄色字体的字,看不懂的那种,如下图: 然后查了一下资料,说可能是adt版本太低,手机系统太高. 然后本来想升级adt,但是各种折 ...
- Redis集群模式下的redis-py-cluster方式读写测试
与MySQL主从复制,从节点可以分担部分读压力不一样,甚至可以增加slave或者slave的slave来分担读压力,Redis集群中的从节点,默认是不分担读请求的,从节点只作为主节点的备份,仅负责故障 ...
- RNN梯度消失和爆炸的原因 以及 LSTM如何解决梯度消失问题
RNN梯度消失和爆炸的原因 经典的RNN结构如下图所示: 假设我们的时间序列只有三段, 为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下: 假设在t=3时刻,损失函数为 . 则对于一 ...
- Ineedle驱动方式dpdk测试性能
这次主要是测试在dpdk方案下,ineedle的处理包的性能. 发包工具: 使用立永当时写的一个发包工具:linux_pcap 做法:大概是从网上抓取了一些数据包,将源ip替换为随即ip,sip替换为 ...
- spring AOP 的几种实现方式(能测试)
我们经常会用到的有如下几种 1.基于代理的AOP 2.纯简单Java对象切面 3.@Aspect注解形式的 4.注入形式的Aspcet切面 一.需要的java文件 public class ChenL ...
- Java IO读写大文件的几种方式及测试
读取文件大小:1.45G 第一种,OldIO: public static void oldIOReadFile() throws IOException{ BufferedReader br = n ...
随机推荐
- 黑马java课程视频java学习视频
资料获取方式,关注公总号RaoRao1994,查看往期精彩-所有文章,即可获取资源下载链接 更多资源获取,请关注公总号RaoRao1994
- kafka核心原理总结
新霸哥发现在新的技术发展时代,消息中间件也越来越受重视,很多的企业在招聘的过程中着重强调能够熟练使用消息中间件,所有做为一个软件开发爱好者,新霸哥在此提醒广大的软件开发朋友有时间多学习. 消息中间件利 ...
- 更改命令行,完全显示hostname
刚装完一台新服务器,想让命令行的能显示全部的hostname,查阅资料后,将$PS1的参数修改即可 1,echo $PS1 2,将其中的/h换成/H即可 3,我是在/etc/profile中加了一行 ...
- 测开常见面试题什么是redis
企业中redis是必备的性能优化中间件,也是常见面试题,首先Redis是由意大利人Salvatore Sanfilippo(网名:antirez)开发的一款内存高速缓存数据库.Redis全称为:Rem ...
- js 简单实现隐藏和显示
<html> <head> <meta charset="gb2312"> <title>隐藏和显示</title> & ...
- 度限制MST
POJ1639 顶点度数限制的最小生成树 做法:首先把和顶点相连的X条边全部删掉 得到顶点和 X个连通块 然后求出这X个连通块的MST 再把X条边连接回去这样我们就首先求出了X度MST 知道了X度MS ...
- php socket如何实现长连接
长连接是什么? 朋友们应该都见过很多在线聊天工具和网页在线聊天的工具.学校内有一种熟悉的功能,如果有人回复你了,网站会马上出现提示,此时你并没有刷新页面:Gmail也有此功能,如果邮箱里收到了新的邮件 ...
- ORACLE纯SQL实现多行合并一行
项目中遇到一个需求,需要将多行合并为一行.表结构如下:NAME Null Type---------------------- ...
- CodeForces - 1175E Minimal Segment Cover (倍增优化dp)
题意:给你n条线段[l,r]以及m组询问,每组询问给出一组[l,r],问至少需要取多少个线段可以覆盖[l,r]区间中所有的点. 如果贪心地做的话,可以求出“从每个左端点l出发选一条线段可以到达的最右端 ...
- poj2279 Mr. Young's Picture Permutations[勾长公式 or 线性DP]
若干人左对齐站成最多5行,给定每行站多少个,列数从第一排开始往后递减.要求身高从每排从左到右递增(我将题意篡改了便于理解233),每列从前向后递增.每个人身高为1...n(n<=30)中的一个数 ...