java 中的编码
1、1字节=8位,1024字节=1KB
2、16进制0x12345678,其二进制为00010010 00110100 01010110 01111000共4字节
3、字节序:两个或多个字节存放的先后顺序(Big Endian大端序,Little Endian小端序)。UTF-16编码的头2个字节里标记字节序: LE [0xFF, 0xFE], BE [0xFE, 0xFF]。(http://blog.jobbole.com/102432/)
4、0x12345678以Big Endian存储:0x12 0x34 0x56 0x78
5、0x12345678以Little Endian存储:0x78 0x56 0x34 0x12
6、字符集:Unicode
7、编码:UTF-8、UTF-16、UTF-16BE、UTF-16LE等等
8、编码是字符集的一种编码方式。
9、查看编码的网站:https://unicode-table.com
10、
计算机存储补码
+1
原码:0000 0001
反码:0000 0001
补码:0000 0001
-1
原码:1000 0001
反码(负数反码:在原码基础上,除符号位外,其余取反):1111 1110
补码(负数补码:在反码基础上,加1):1111 1111
java中byte类型占8位。带符号最大值是127,带符号最小值是-128。不带符号最大值是255,不带符号最小值是0。
十进制 十六进制 二进制
254 0xfe 11111110
将254(即00000000 00000000 00000000 11111110)赋值给一个byte类型的变量, 取低8位 11111110,直接当做补码存储,其反码是1111 1101,其原码是1000 0010(十进制-2)。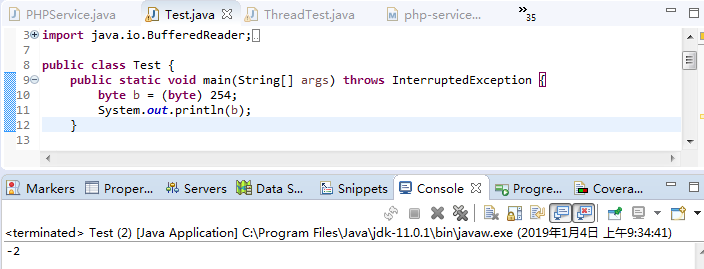
11、编码
UTF-8
没有字节序的概念。
所以1~4字节UTF-8编码看起来是这样的:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
字节头部识别就是前面的0,110,1110,11110表示字节数。
从UTF-8字节流的任意位置开始可以有效地找到一个字符的起始位置,字符边界很容易界定、检测出来。
单字节可编码的Unicode范围:\u0000~\u007F(0~127)
双字节可编码的Unicode范围:\u0080~\u07FF(128~2047)
三字节可编码的Unicode范围:\u0800~\uFFFF(2048~65535)
四字节可编码的Unicode范围:\u10000~\u1FFFFF(65536~2097151)
UTF-16
2字节或4字节
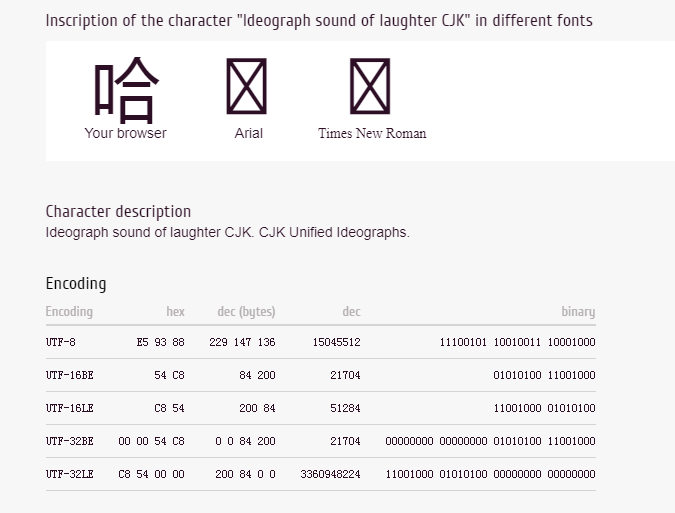
查看中文 “哈” 的编码:
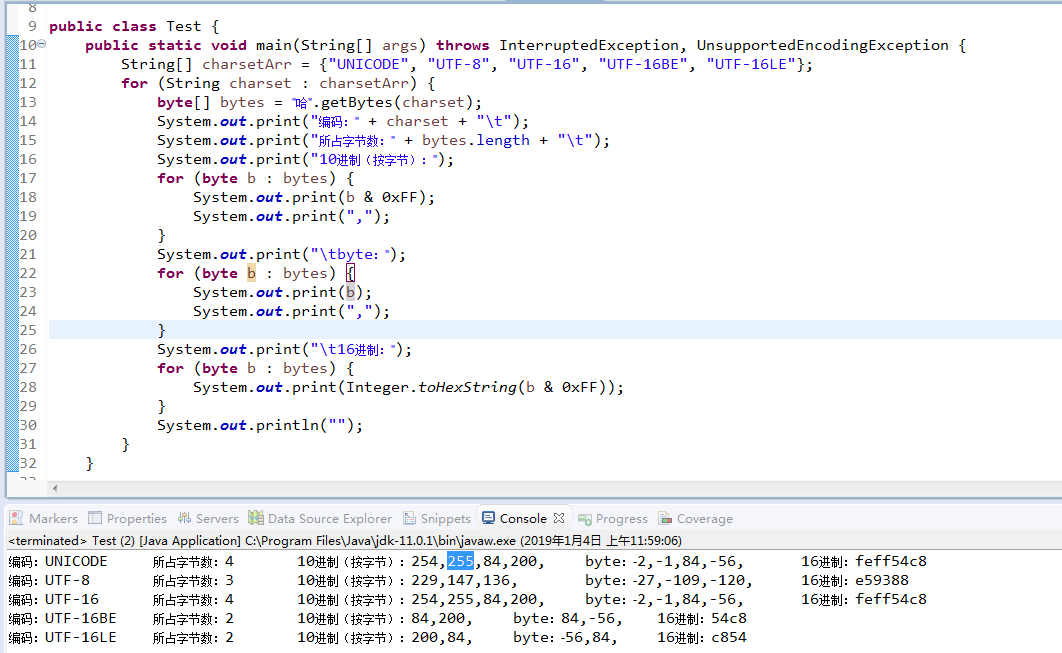
System.out.print(b & 0xFF);
b是byte类型,存储的是1000 0010(即10进制-2),当jvm检测到byte可能会转为 int,或byte与int类型进行计算时,会将byte的最高24位补1,扩充到32位,再参与计算。
1000 0010 扩充到32位:11111111 11111111 11111111 10000010。
b & 0xFF == 11111111 11111111 11111111 10000010 & 00000000 00000000 00000000 11111111
所以 b & 0xFF == 00000000 00000000 00000000 00000000 10000010 (即十进制254)
java 中的编码的更多相关文章
- 理清Java中的编码解码转换
1.字符集及编码方式 概括:字符编码方式及大端小端 详细:彻底理解字符编码 可以通过Charset.availableCharsets()获取Java支持的字符集,以JDK8为例,得到其支持的字符集: ...
- java中的编码和编码格式问题
看来问的人和回答的人都不一定清楚什么是“编码和编码格式”,以及如何理解“java中字符串的编码”;首先明确几点: unicode是一种“编码”,所谓编码就是一个编号(数字)到字符的一种映射关系,就仅仅 ...
- java基础---->java中字符编码问题(一)
这里面对java中的字符编码做一个总结,毕竟在项目中会经常遇到这个问题.爱不爱都可以,我怎样都依你,连借口我都帮你寻. 文件的编码格式 一.关于中文的二进制字节问题 public static Str ...
- 关于java中的编码问题
ok,今天搞了一天都在探索java字符的编码问题.十分头疼.最后终于得出几点: 1.网上有很多博客说判断一个String的编码的方法是通过如下代码;但其实这个代码完全是错的,用一种编码decode后, ...
- JAVA中的编码分析
在实际编程中可以不用关注JVM中使用的是什么编码,而只需要关注自己输出需要采用的编码,JVM会根据你设置的编码正确操作. 1.String采用的是什么编码? 很多厂家根据规范实现了JVM,JVM只说明 ...
- java中字符串编码转换
Java 正确的做字符串编码转换 字符串的内部表示? 字符串在java中统一用unicode表示( 即utf-16 LE) , 对于 String s = "你好哦!"; 如果源码 ...
- Java中字符编码和字符串所占字节数 .
首 先,java中的一个char是2个字节.java采用unicode,2个字节来表示一个字符,这点与C语言中不同,C语言中采用ASCII,在大多数 系统中,一个char通常占1个字节,但是在0~12 ...
- 一文解开java中字符串编码的小秘密
目录 简介 Unicode的发展史 Unicode详解 UTF-8 UTF-16 UTF-32 Null-terminated string 和变种UTF-8 简介 在本文中你将了解到Unicode和 ...
- Java中的编码
package coreJava; import javax.swing.plaf.synth.SynthSpinnerUI; public class EncodeDemo { public sta ...
随机推荐
- 基于RANSAC的点云面分割算法
该算法在RANSAC和空间检索树的基础上实现的. 算法思路: 1.点云抽希.法线估计 2.出局点索引存储声明 3.平面检测 for (size_t i = 0; i < cloudTemp-&g ...
- easyhook源码分析三——申请钩子
EasyHook 中申请钩子的原理介绍 函数原型 内部使用的函数,为给定的入口函数申请一个hook结构. 准备将目标函数的所有调用重定向到目标函数,但是尚未实施hook. EASYHOOK_NT_IN ...
- JVM参数配置详解-包含JDK1.8
堆大小设置 JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系统的可用虚拟内存限制:系统的可用物理内存限制.32位系统下,一般限制在1.5G~2G:6 ...
- 【HANA系列】SAP HANA SQL获取当前日期
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA SQL获取当前 ...
- 【Linux开发】Linux下jpeglib库的安装详解
Linux下jpeglib库的安装详解 首先要下载所需的库压缩包:jpegsrc.v6b.tar.gz或 jpegsrc.v8b.tar.gz 然后将下载的压缩包随便放在和解压到你喜欢的地方. # t ...
- spring扩展点之PropertyPlaceholderConfigurer
原理机制讲解 https://leokongwq.github.io/2016/12/28/spring-PropertyPlaceholderConfigurer.html 使用时多个配置讲解 ht ...
- IntelliJ IDEA 部署 Web 项目,终于搞懂了!
这篇牛逼: IDEA 中最重要的各种设置项,就是这个 Project Structre 了,关乎你的项目运行,缺胳膊少腿都不行. 最近公司正好也是用之前自己比较熟悉的IDEA而不是Eclipse,为了 ...
- JS案例经验1
一 可以通过设置在一个div中的多个div的定位属性为absolute,从而使得这几个元素重叠.他们都脱离了标准流. 二 对于absolute的left和right属性,当left和right同时出现 ...
- tensorflow学习笔记二----------变量
tensorflow里面的变量表示,需要使用特定的语法进行.如果想构造一个行(列)向量,需要调用Variable函数进行.对两个变量进行操作,也要调用相应的函数. import tensorflow ...
- Scrapy 教程(三)-网站解析
有经验的人都知道,解析网站需要尝试,看看得到的数据是不是想要的,那么在scrapy中怎么尝试呢? 调试工具-shell 主要用于编写解析器 命令行进入shell scrapy shell url 这个 ...