R_Studio(学生成绩)使用cbind()函数对多个学期成绩进行集成
“Gary1.csv”、“Gary2.csv”、“Gary3.csv”中保存了一个班级学生三个学期的成绩
对三个学期中的成绩数据进行集成并重新计算综合成绩和排名,并按排名顺序排布(学号9位数111304001~11304047)
Gary1.csv中数据

Gary2.csv中数据
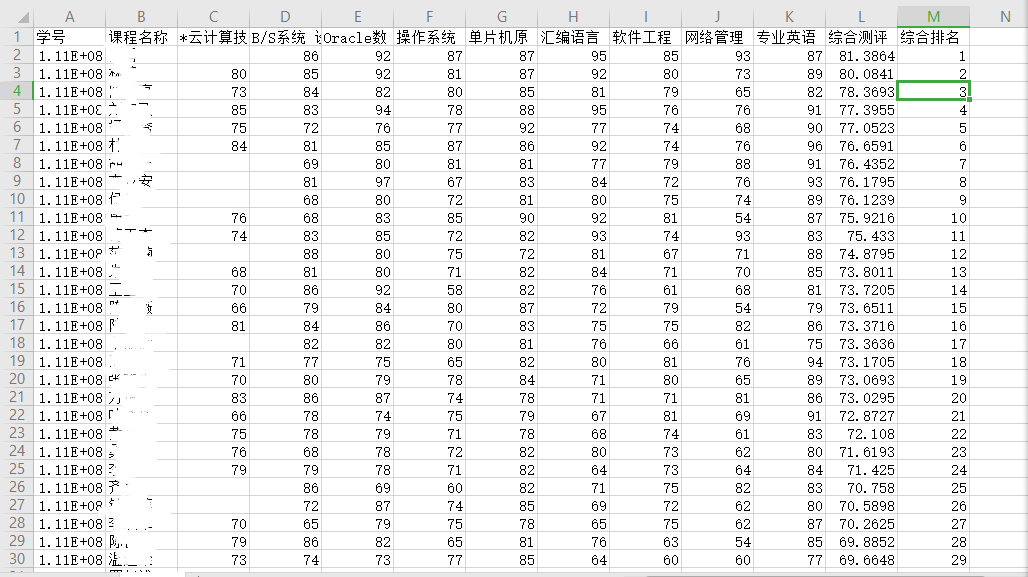
Gary3.csv中数据
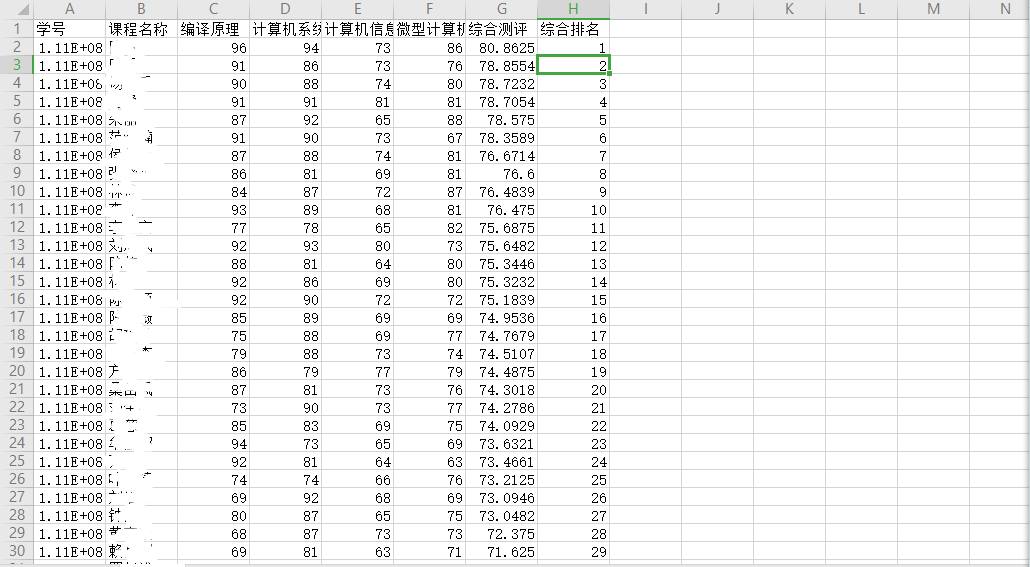
cbind是根据列进行合并 (要求:所有数据行数相等)
rbind是根据行进行合并 (要求:所有数据列数相同)

#打开工作目录文件
setwd('D:\\data') list.files() inputfile1=read.csv(file="Gary1.csv",header=TRUE)
inputfile2=read.csv(file="Gary2.csv",header=TRUE)
inputfile3=read.csv(file="Gary3.csv",header=TRUE) #删除inputfile1中的综合成绩和排名,删除inputfile2中的学号、姓名、综合成绩和排名
result=cbind(inputfile1[,-c(,)],inputfile2[,-c(,,,)]) #数据集列合并 #同理
result2=cbind(result,inputfile3[,-c(,,,)]) #对学生成绩进行相加,得到一组数据(我自己测试学生成绩是从第三列到第二十二列的)
#相加成绩保存到evaluation中
evaluation=apply(result2[,:], ,mean,na.rm=TRUE) #apply函数一般有三个参数
#第一个参数代表矩阵对象
#第二个参数代表要操作矩阵的维度 1表示对行进行处理,2表示对列进行处理
#第三个参数就是处理数据的函数
#apply会分别一行或一列处理该矩阵的数据。 #将evaluation用“综合测评”添加到resule2中,将结果用result11保存
result11=data.frame(result2,'综合测评'=evaluation) #对result11中按综合测评成绩进行decreasing减少量排名
result22=result11[order(result11$综合测评,decreasing = TRUE), ] result33=data.frame(result22,'测评排名'=order(result22$综合测评,decreasing = TRUE)) result33
Gary.R
实现过程
apply函数三个参数:
第一个参数代表矩阵对象
第二个参数代表要操作矩阵的维度 1表示对行进行处理,2表示对列进行处理
第三个参数就是处理数据的函数
读取文件数据保存到inputfile中
inputfile1=read.csv(file="Gary1.csv",header=TRUE)
inputfile2=read.csv(file="Gary2.csv",header=TRUE)
inputfile3=read.csv(file="Gary3.csv",header=TRUE)
删除inputfile1中的综合成绩和排名,删除inputfile2,inputfuke3中的学号、姓名、综合成绩和排名(合并数据后这些数据多余了)
result=cbind(inputfile1[,-c(,)],inputfile2[,-c(,,,)]) #数据集列合并 result2=cbind(result,inputfile3[,-c(,,,)])
计算学生成绩并将所得结果添加到学生表中
evaluation=apply(result2[,3:22], 1,mean,na.rm=TRUE) #将evaluation用“综合测评”添加到resule2中,将结果用result11保存
result11=data.frame(result2,'综合测评'=evaluation) #对result11中按综合测评成绩进行decreasing减少量排名
result22=result11[order(result11$综合测评,decreasing = TRUE), ] result33=data.frame(result22,'测评排名'=order(result22$综合测评,decreasing = TRUE)) result33
当R数据中存在NA时,使用对数据的mean()函数时需要注意NA问题
y<-mean(x)
对学生成绩异常值检测 传送门
修改上列代码28行
evaluation=apply(result2[,3:22], 1,mean)

补充:merge()函数 传送门
merge 连接两个数据,官方参考文档语法
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"),
incomparables = NULL, ...)
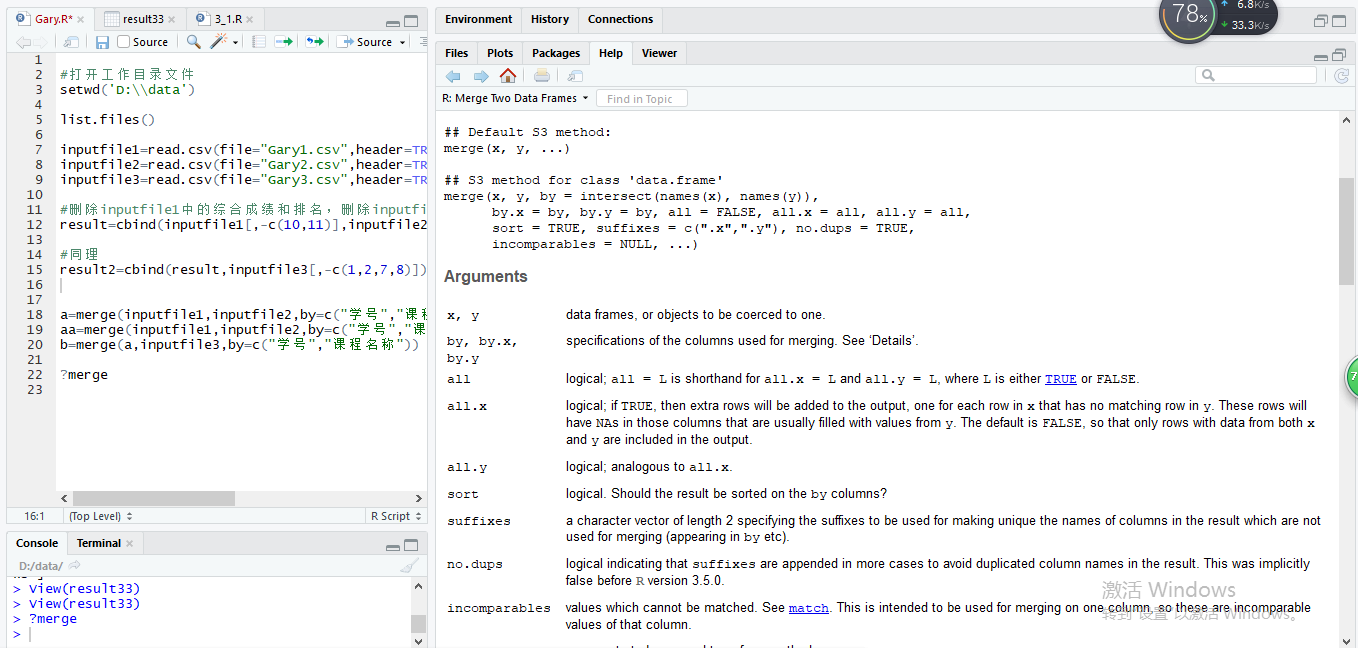
merge()函数是对数据进行交并补运算,三张表进行数据合并时可先合并第一第二张表,再用所合成结果对第三张表进行合成
测试a和aa中值的不同
setwd('D:\\data')
list.files()
inputfile1=read.csv(file="Gary1.csv",header=TRUE)
inputfile2=read.csv(file="Gary2.csv",header=TRUE)
inputfile3=read.csv(file="Gary3.csv",header=TRUE)
#删除inputfile1中的综合成绩和排名,删除inputfile2中的学号、姓名、综合成绩和排名
result=cbind(inputfile1[,-c(10,11)],inputfile2[,-c(1,2,12,13)]) #数据集列合并
#同理
result2=cbind(result,inputfile3[,-c(1,2,7,8)])
a=merge(inputfile1,inputfile2,by=c("学号","课程名称"))
aa=merge(inputfile1,inputfile2,by=c("学号","课程名称","综合排名"))
b=merge(a,inputfile3,by=c("学号","课程名称"))
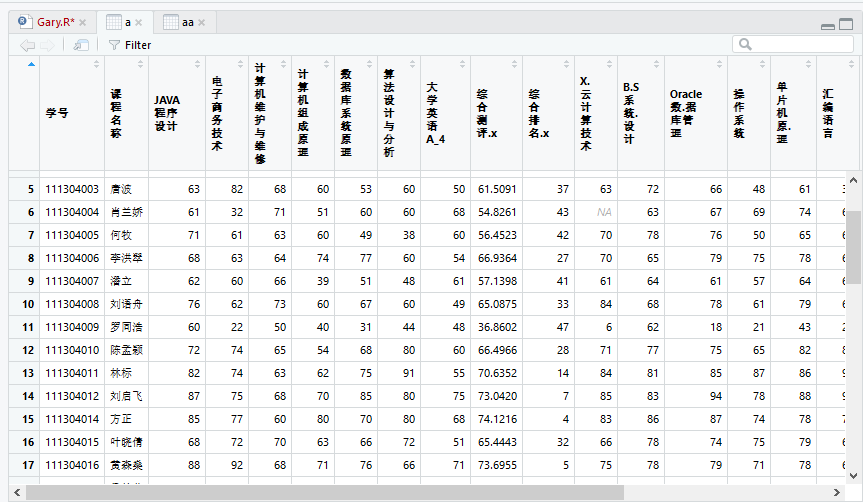
发现aa中存在一个人成绩存在多个综合测评、综合排名的缺陷,把a也添加到by=c("学号","课程名称","综合排名")当中
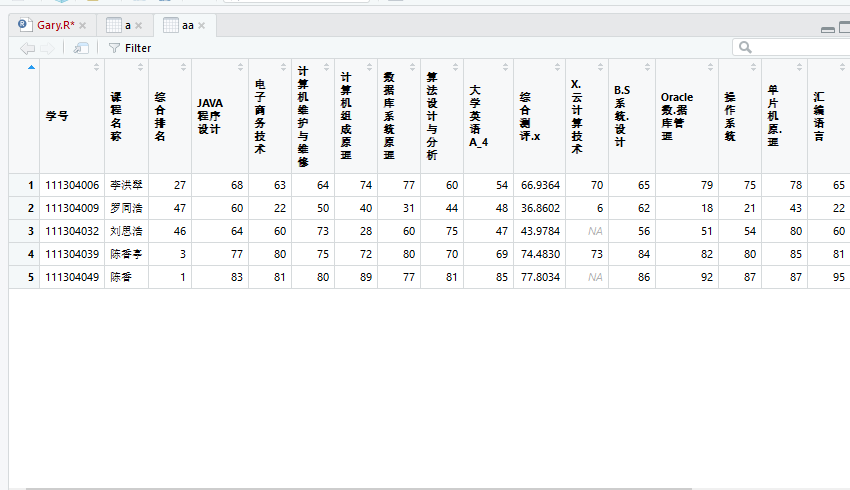
只要第一个学期和第二个学期综合排名不一样时,不显示合并成功的数据!!!
merge()函数对数据的操作还是挺严格的!!!
R_Studio(学生成绩)使用cbind()函数对多个学期成绩进行集成的更多相关文章
- python课后练习当前目录下有一个文件名为score3.txt的文本文件, 存放着某班学生的学号和其两门专业课的成绩。
题目: 当前目录下有一个文件名为score3.txt的文本文件, 存放着某班学生的学号和其两门专业课的成绩.分 别用函数实现以下功能: (1) 定义函数function1,计算每个学生的平均分(取 整 ...
- 【PTA】5-1 输入一个正整数n,再输入n个学生的姓名和百分制成绩,将其转换为两级制成绩后输出。
5-1 输入一个正整数n,再输入n个学生的姓名和百分制成绩,将其转换为两级制成绩后输出.要求定义和调用函数set_grade(stu, n),其功能是根据结构数组stu中存放的学生的百分制成绩scor ...
- sqlserver 查询各个学生语文、数学、英语、历史课程成绩
-- 建表 插入数据 USE 你自己的数据库; CREATE TABLE Member( MID ) PRIMARY KEY, MName ) ); CREATE TABLE Course( FID ...
- Java初学者作业——编写JAVA程序,在控制台输入一位学生的英语考试成绩,根据评测规则,输出对应的成绩等级。定义方法实现学生成绩的评测功能。
返回本章节 返回作业目录 需求说明: 编写JAVA程序,在控制台输入一位学生的英语考试成绩,根据评测规则,输出对应的成绩等级.要求:定义方法实现学生成绩的评测功能. 学生的英语考试成绩进行评测,评测规 ...
- Java初学者作业——编写Java程序,根据输入的某个班级的学员成绩,计算该班级学员的平均成绩,要求输入班级的人数。
返回本章节 返回作业目录 需求说明: 编写Java程序,根据输入的某个班级的学员成绩,计算该班级学员的平均成绩,要求输入班级的人数. 实现思路: 声明变量sum.count以及avg用于存储总成绩.班 ...
- R_Studio(学生成绩)对两个班级学生成绩进行集合,重新计算学生综合测评成绩并对学生按综合测评成绩进行排名
对成绩表"11_1_1.csv" "11_2_1.csv"进行集成,并重新计算4门课程的平均分为综合测评,增加“排名”属性,并按排名排序 "11_1_ ...
- R_Studio(学生成绩)对数据缺失值md.pattern()、异常值分析(箱线图)
我们发现这张Gary.csv表格存在学生成绩不完全的(五十三名学生,三名学生存在成绩不完整.共四个不完整成绩) 79号大学语文.高等数学 96号中国近代史纲要 65号大学体育 (1)NA表示数据集中的 ...
- R_Studio(学生成绩)数据相关性分析
对“Gary.csv”中的成绩数据进行统计量分析 用cor函数来计算相关性,method默认参数是用pearson:并且遇到缺失值,use默认参数everything,结果会是NA 相关性分析 当值r ...
- R_Studio(学生成绩)绘制频率分布直方图、分布饼图、折线比较图
对“Gary.csv”中的成绩数据进行分布分析 (1)按0-59,60-69,70-79,80-89,90-100分组绘制高级语言程序设计成绩的频率分布直方图. (2)按0-59,60-69,70-7 ...
随机推荐
- # Tallest Cows(差分)
Tallest Cows(差分) n头牛,给出最高牛的位置和身高,其他牛身高未知,给出m对相对关系,表示可以相互看见当且仅当他们中间的牛都比他们矮.求每头牛身高最大值是多少. 差分数组的性质:前缀和为 ...
- thinkphp框架部署出现404解决
1:虚拟机配置文件修改: location / { index index.php index.html; if (!-e $request_filename) { rewrite ^/index.p ...
- @Transactional spring事务回滚相关
还可以设置回滚点,看下面 /** * 用户登录接口 * * * 1明确事务方法前的命名规则 * 2保证事务方法执行的时间尽可能的短,不允许出现循环操作,不允许出现RPC等网络请求操作 * 3不允许所有 ...
- python基础之初始函数
首先,为什么要使用函数? 函数的本质来说,就是写一串代码具有某些功能,然后封装起来,接下来可以很方便的调用 例如...然后... # s = '金老板小护士'# len(s) #在这里需求是求字符串s ...
- 二维数组中的查找——牛客剑指offer
题目描述: 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整 ...
- C++ 对象构造顺序、构析函数、临时对象。
对象的构造顺序: 1.对于局部对象,构造顺序是根据程序执行流进行构造,从上到下. #include <stdio.h> class Test { int mi; public: Test( ...
- iis 8.0 HTTP 错误 404.3 server 2012
最近在学习WCF,发现将网站WCF服务放到IIS上时不能正常运行,从网上搜了一下: 解决方法,以管理员身份进入命令行模式,运行: "%windir%\Microsoft.NET\Framew ...
- 小程序存emoji表情 不改变数据库
1.小程序:提交前先编码 encodeURIComponent(data) 2.服务端解码(PHP) urldecode(data) 3.如果有空格字符串的,保存之前先对空格进行处理,不然空格在页面会 ...
- O021、创建 Image
参考https://www.cnblogs.com/CloudMan6/p/5393376.html 本节演示如何通过 Web GUI 和 CLI 两种方法创建image. OpenStack ...
- 最简单的方式实现rem布局
加上如下js,px转换成rem需要手动,计算方式:量的大小除以100,就等于rem,例如:量的设计稿元素宽度是120,那么就写成{width: 1.2rem},这样写有什么问题,待研究,也欢迎补充 & ...