企业级技术解决方案:hbase+es
1:需求:
解决海量数据的存储,并且能够实现海量数据的秒级查询
Hbase是典型的nosql,是一种构建在HDFS之上的分布式、面向列的存储系统,在需要的时候可以进行实时的大规模数据集的读写操作;但是hbase的语法非常固话,即便在hbase之上嫁接了phoneix在应对复杂查询的时候,仍然力不从心;
所以说很多公司在历史遗留问题,最开始数据存储在hbase上,当业务越来越复杂,数据量越来越大的时候,使用hbase构建复杂的查询就很吃力了,甚至很多指标无法完成;
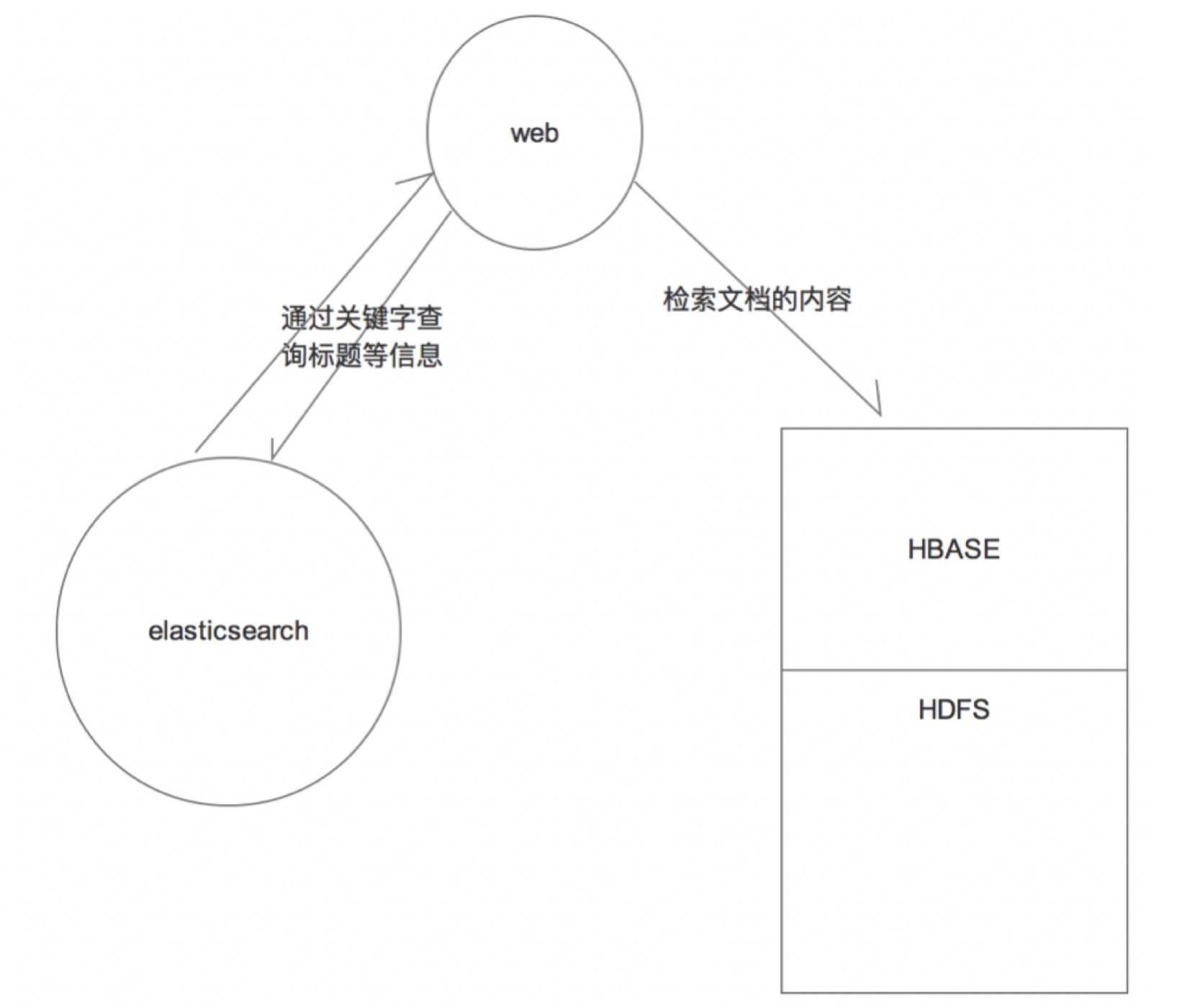
这个时候,我们就是用elasticsearch架构在hbase之上;
海量的数据存储使用hbase,数据的即席查询(快速检索)使用elasticsearch
通过elasticsearch+hbase就可以做到海量数据的复杂查询;
在操作之前,我们还要考虑:一批数据在elasticsearch中构建索引的时候,针对每一个字段要分析是否存储和是否构建索引;
实际生产中,一遍文章要分成标题和正文;但是正文的量是比较大的,那么我们一般会在,在hbase中存储正文(hbase本身就是做海量数据的存储);这样通过es的倒排索引列表检索到关键词的文档id,然后根据文档id在hbase中查询出具体的正文
(当然具体情况看具体需求)
分析,数据哪些字段需要构建索引:
文章数据(id、title、author、describe、conent)
| 字段名称 | 是否需要索引 | 是否需要存储 |
|---|---|---|
| Id | 默认索引 | 默认存储 |
| Title | 需要 | 需要 |
| Author | 看需求 | 看需求 |
| Dscribe | 需要 | 存储 |
| Content | 看需求(高精度查询,是需要的 ) | 看需求 |
| Time | 需要 | 需要 |
2:mapping的配置信息
curl -XPUT http://hadoop01:9200/articles -d '
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
"mappings":{
"article":{
"dynamic":"strict",
"properties":{
"id":{"type": "string", "store": true},
"title":{"type": "string","store": true,"index" : "analyzed","analyzer": "ik_max_word"},
"from":{"type": "string","store": true},
"readCounts":{"type": "integer","store": true},
"content":{"type": "string","store": false,"index": "no"},
"times": {"type": "string", "index": "not_analyzed"}
}
}
}
} '
3: 架构设计
企业级技术解决方案:hbase+es的更多相关文章
- 《Hadoop高级编程》之为Hadoop实现构建企业级安全解决方案
本章内容提要 ● 理解企业级应用的安全顾虑 ● 理解Hadoop尚未为企业级应用提供的安全机制 ● 考察用于构建企业级安全解决方案的方法 第10章讨论了Hadoop安全性以及Hado ...
- Foreman 企业级配置管理解决方案
Foreman 企业级配置管理解决方案 Foreman 企业级配置管理解决方案 笔记本 puppet foreman 构建运维体系 本文是构建运维体系的其中一个关键环节. 什么是 foreman Fo ...
- CMMI三个过程域的流程及达到特定目标、共性目标的要求(RD需求管理过程,PI产品集成过程,TS技术解决方案)
RD需求管理过程 通过面谈的方式获取相关干系人关于产品生命周期各阶段的需求.期望,限制条件,接口 将相关干系人的需求.期望,限制条件,接口转化成用户需求说明书 依据客户需求,确定产品或产品组件需求,形 ...
- FluentData - 轻量级.NET ORM持久化技术解决方案
官方地址:http://fluentdata.codeplex.com/ 官方教程:http://fluentdata.codeplex.com/documentation FluentData入门 ...
- Samtec大数据技术解决方案
序言:众所周知,大数据将在AI时代扮演重要角色,拥有海量数据的公司已在多个领域尝试对掌握的数据进行利用,大数据意识和能力进步飞快,体系和工具日趋成熟. Samtec和Molex 是获得许可从而提供 M ...
- TDSQL | 在整个技术解决方案中HTAP对应的混合交易以及分析系统应该如何实现?
从主交易到传输,到插件式解决方案,每个厂商对HTAP的理解和实验方式都有自己的独到解法,在未来整个数据解决方案当中都会往HTAP中去牵引.那么在整个技术解决方案中HTAP对应的混合交易以及分析系统应该 ...
- Sentry 企业级数据安全解决方案 - Relay 运行模式
内容整理自官方开发文档 Relay 可以在几种主要模式之一下运行,如果您正在配置 Relay server 而不是使用默认设置,那么事先了解这些模式至关重要. 模式存储在配置文件中,该文件包含 rel ...
- Sentry 企业级数据安全解决方案 - Relay 配置选项
Relay 的配置记录在文件 .relay/config.yml 中.要更改此位置,请将 --config 选项传递给任何 Relay 命令: ❯ ./relay run --config /path ...
- Sentry 企业级数据安全解决方案 - Relay 监控 & 指标收集
内容整理自官方文档 系列 Sentry 企业级数据安全解决方案 - Relay 入门 Sentry 企业级数据安全解决方案 - Relay 运行模式 Sentry 企业级数据安全解决方案 - Rela ...
随机推荐
- 2019第二周总结.Java
本学期开始学习Java课程了,首先我先说说学习Java的感觉吧,它不像C语言程序设计,但是又有语言开发的共同点.学Java语言重点是面向对象的程序设计,更加的适应生活需要和计算机开发的需要. 总的来讲 ...
- 第九周总结&第七次实验报告
实验7 实验任务详情: 完成火车站售票程序的模拟. 要求: (1)总票数1000张: (2)10个窗口同时开始卖票: (3)卖票过程延时1秒钟: (4)不能出现一票多卖或卖出负数号票的情况. 实验过程 ...
- Mybatis-学习笔记(N)mybatis-generator 生成DAO、Mapper、entity
1.mybatis-generator 生成DAO.Mapper.entity 所需环境:jdk 所需jar包:mybatis-generator-core-1.3.5.jar.MySQL-conne ...
- 又是图论.jpg
BZOJ 2200 道路和航线重讲ww: FJ 正在一个新的销售区域对他的牛奶销售方案进行调查.他想把牛奶送到 T 个城镇 (1 ≤ T ≤ 25000),编号为 1 到 T.这些城镇之间通过 R 条 ...
- Python 入门之 推导式
Python 入门之 推导式 推导式就是构建比较有规律的列表,生成器,字典等一种简便的方式 1.推导式 (1)列表推导式 : <1> 普通循环: [变量 for循环] print([i f ...
- kmeans 聚类 k 值优化
kmeans 中k值一直是个令人头疼的问题,这里提出几种优化策略. 手肘法 核心思想 1. 肉眼评价聚类好坏是看每类样本是否紧凑,称之为聚合程度: 2. 类别数越大,样本划分越精细,聚合程度越高,当类 ...
- A - 卿学姐与公主(线段树+单点更新+区间极值)
A - 卿学姐与公主 Time Limit: 2000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) Submi ...
- SCUT - 216 - 宝华科技树
https://scut.online/p/216 演员 把这个当成dp算了半天,各种姿势,好吧,就当练习一下树dp. 假如是每个节点的层数之和,按照dp[i][j]为从i点出发获得j科技的最小费用d ...
- 工作笔记之20170223:①关于Html5的placeholder属性,②以及input的outline:none的样式问题
关于这边几个样式问题,重点有这么几个: (1)placeholder="请输入密码" (2) color:#BEB6B6; border:0px; border-bottom:1p ...
- go & AI核心代码