{Reship}Precision, Accuracy & Recall
==============================================================
This aritcle came from here
====================================================================
http://blog.sina.com.cn/s/blog_4b59de070100ehl7.html
最近一直在做相关推荐方面的研究与应用工作,召回率与准确率这两个概念偶尔会遇到,
知道意思,但是有时候要很清晰地向同学介绍则有点转不过弯来。
召回率和准确率是数据挖掘中预测、互联网中的搜索引擎等经常涉及的两个概念和指标。
召回率:Recall,又称“查全率”——还是查全率好记,也更能体现其实质意义。
准确率:Precision,又称“精度”、“正确率”。
以检索为例,可以把搜索情况用下图表示:
|
相关
|
不相关
|
|
|
检索到
|
A
|
B
|
|
未检索到
|
C
|
D
|
A:检索到的,相关的 (搜到的也想要的)
B:检索到的,但是不相关的 (搜到的但没用的)
C:未检索到的,但却是相关的 (没搜到,然而实际上想要的)
D:未检索到的,也不相关的 (没搜到也没用的)
如果我们希望:被检索到的内容越多越好,这是追求“查全率”,即A/(A+C),越大越好。
如果我们希望:检索到的文档中,真正想要的、也就是相关的越多越好,不相关的越少越好,
这是追求“准确率”,即A/(A+B),越大越好。
“召回率”与“准确率”虽然没有必然的关系(从上面公式中可以看到),在实际应用中,是相互制约的。
要根据实际需求,找到一个平衡点。
往往难以迅速反应的是“召回率”。我想这与字面意思也有关系,从“召回”的字面意思不能直接看到其意义。
“召回”在中文的意思是:把xx调回来。“召回率”对应的英文“recall”,
recall除了有上面说到的“order sth to return”的意思之外,还有“remember”的意思。
Recall:the ability to remember sth. that you have learned or sth. that has happened in the past.
当我们问检索系统某一件事的所有细节时(输入检索query查询词),
Recall指:检索系统能“回忆”起那些事的多少细节,通俗来讲就是“回忆的能力”。
“能回忆起来的细节数” 除以 “系统知道这件事的所有细节”,就是“记忆率”,
也就是recall——召回率。简单的,也可以理解为查全率。
根据自己的知识总结的,定义应该肯定对了,在某些表述方面可能有错误的地方。
假设原始样本中有两类,其中:
1:总共有 P个类别为1的样本,假设类别1为正例。
2:总共有N个类别为0 的样本,假设类别0为负例。
经过分类后:
3:有 TP个类别为1 的样本被系统正确判定为类别1,FN 个类别为1 的样本被系统误判定为类别 0,
显然有P=TP+FN;
4:有 FP 个类别为0 的样本被系统误判断定为类别1,TN 个类别为0 的样本被系统正确判为类别 0,
显然有N=FP+TN;
那么:
精确度(Precision):
P = TP/(TP+FP) ; 反映了被分类器判定的正例中真正的正例样本的比重(
准确率(Accuracy)
A = (TP + TN)/(P+N) = (TP + TN)/(TP + FN + FP + TN);
反映了分类器统对整个样本的判定能力——能将正的判定为正,负的判定为负
召回率(Recall),也称为 True Positive Rate:
R = TP/(TP+FN) = 1 - FN/T; 反映了被正确判定的正例占总的正例的比重
转移性(Specificity,不知道这个翻译对不对,这个指标用的也不多),
也称为 True NegativeRate
S = TN/(TN + FP) = 1 – FP/N; 明显的这个和召回率是对应的指标,
只是用它在衡量类别0 的判定能力。
F-measure or balanced F-score
F = 2 * 召回率 * 准确率/ (召回率+准确率);这就是传统上通常说的F1 measure,
另外还有一些别的F measure,可以参考下面的链接
上面这些介绍可以参考:
http://en.wikipedia.org/wiki/Precision_and_recall
同时,也可以看看:http://en.wikipedia.org/wiki/Accuracy_and_precision
为什么会有这么多指标呢?
这是因为模式分类和机器学习的需要。判断一个分类器对所用样本的分类能力或者在不同的应用场合时,
需要有不同的指标。 当总共有个100 个样本(P+N=100)时,假如只有一个正例(P=1),
那么只考虑精确度的话,不需要进行任何模型的训练,直接将所有测试样本判为正例,
那么 A 能达到 99%,非常高了,但这并没有反映出模型真正的能力。另外在统计信号分析中,
对不同类的判断结果的错误的惩罚是不一样的。举例而言,雷达收到100个来袭 导弹的信号,
其中只有 3个是真正的导弹信号,其余 97 个是敌方模拟的导弹信号。假如系统判断 98 个
(97 个模拟信号加一个真正的导弹信号)信号都是模拟信号,那么Accuracy=98%,
很高了,剩下两个是导弹信号,被截掉,这时Recall=2/3=66.67%,
Precision=2/2=100%,Precision也很高。但剩下的那颗导弹就会造成灾害。
因此在统计信号分析中,有另外两个指标来衡量分类器错误判断的后果:
漏警概率(Missing Alarm)
MA = FN/(TP + FN) = 1 – TP/T = 1 - R; 反映有多少个正例被漏判了
(我们这里就是真正的导弹信号被判断为模拟信号,可见MA此时为 33.33%,太高了)
虚警概率(False Alarm)
FA = FP / (TP + FP) = 1 – P;反映被判为正例样本中,有多少个是负例。
统计信号分析中,希望上述的两个错误概率尽量小。而对分类器的总的惩罚旧
是上面两种错误分别加上惩罚因子的和:COST = Cma *MA + Cfa * FA。
不同的场合、需要下,对不同的错误的惩罚也不一样的。像这里,我们自然希望对漏警的惩罚大,
因此它的惩罚因子 Cma 要大些。
个人观点:虽然上述指标之间可以互相转换,但在模式分类中,
一般用 P、R、A 三个指标,不用MA和 FA。而且统计信号分析中,也很少看到用 R 的。
至于为什么名字中间带一个字母X呢? 
查准与召回(Precision & Recall)
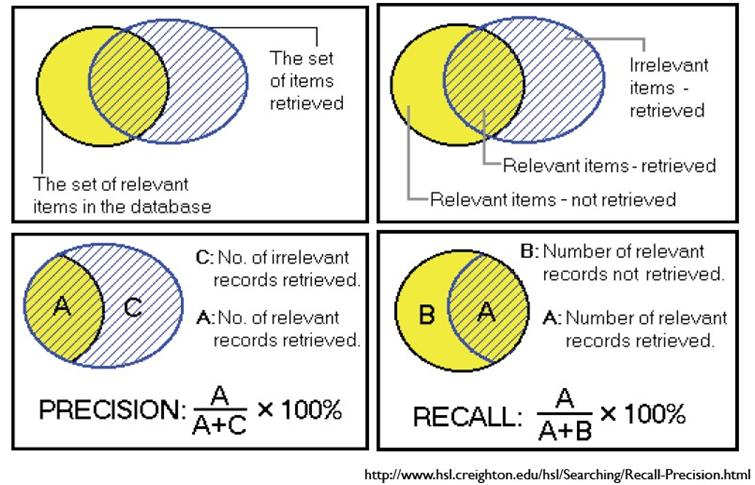
就是检索出来的条目中(比如网页)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
某些情况下是矛盾的。比如极端情况下,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。
F1 Measure
F
Measure了,有些地方也叫做F Score,都是一样的。
F = (a^2+1)P*R / a^2P +R
F1 = 2P*R / (P+R)
很容易理解,F1综合了P和R的结果。
{Reship}Precision, Accuracy & Recall的更多相关文章
- precision、recall、accuracy的概念
机器学习中涉及到几个关于错误的概念: precision:(精确度) precision = TP/(TP+FP) recall:(召回率) recall = TP/(TP+FN) accuracy: ...
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 分类预测输出precision,recall,accuracy,auc和tp,tn,fp,fn矩阵
此次我做的实验是二分类问题,输出precision,recall,accuracy,auc # -*- coding: utf-8 -*- #from sklearn.neighbors import ...
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- Mean Average Precision(mAP),Precision,Recall,Accuracy,F1_score,PR曲线、ROC曲线,AUC值,决定系数R^2 的含义与计算
背景 之前在研究Object Detection的时候,只是知道Precision这个指标,但是mAP(mean Average Precision)具体是如何计算的,暂时还不知道.最近做OD的任 ...
- 对accuracy、precision、recall、F1-score、ROC-AUC、PRC-AUC的一些理解
最近做了一些分类模型,所以打算对分类模型常用的评价指标做一些记录,说一下自己的理解.使用何种评价指标,完全取决于应用场景及数据分析人员关注点,不同评价指标之间并没有优劣之分,只是各指标侧重反映的信息不 ...
- ROC曲线、AUC、Precision、Recall、F-measure理解及Python实现
本文首先从整体上介绍ROC曲线.AUC.Precision.Recall以及F-measure,然后介绍上述这些评价指标的有趣特性,最后给出ROC曲线的一个Python实现示例. 一.ROC曲线.AU ...
- 一道关于 precision、recall 和 threshold关系的机器学习题
Suppose you have trained a logistic regression classifier which is outputing hθ(x). Currently, you p ...
- 评估指标:ROC,AUC,Precision、Recall、F1-score
一.ROC,AUC ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣 . ROC曲线一般的 ...
随机推荐
- 初探groupcache
groupcache是用于dl.google.com的一个memcached的替代品,相对于memcached,提供更小的功能集和更高的效率,以第三方库的形式提供服务. groupcache的常见部署 ...
- 有一个无效 SelectedValue,因为它不在项目列表中。
在项目中出现绑定下拉框报错的问题 1:可能是先赋值,再绑定数据的问题 检查代码,是否有在数据绑定钱进行了赋值.
- Couldn't open file on client side, trying server side 错误解决
09-09 09:43:21.651: D/MediaPlayer(3340): Couldn't open file on client side, trying server side09-09 ...
- 图片加载完后执行js
<script> window.onload=function(){ var liwidth = $('.imgul ...
- frame和bounds区别
学习ios开发有一段时间了,项目也做了两个了,今天看视频,突然发现view的frame和bound两个属性,发现bound怎么也想不明白,好像饶你了死胡同里,经过一番尝试和思考,终于弄明白bound的 ...
- SQLite手工注入方法小结
SQLite 官网下载:www.sqlite.org/download.html sqlite管理工具:http://www.yunqa.de/delphi/products/sqlitespy/in ...
- LA 3938 动态最大连续和 线段树
题目链接: https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show ...
- 关于 MAXScript 拷贝文件夹及内容到其他位置
之前用 hiddenDOSCommand 本机测试通过,但是换其他电脑有时会不能用... fn xcopy oldfile newfile = ( newfilepath = newfile + &q ...
- IIS-反向代理
测试环境:Windows10.IIS/10.0 1.安装ARR.URL Rewrite(URL重写工具2.0) 注意英文和中文环境的对应: Application Request Routing 对应 ...
- Activity和Service是否是在同一个进程中运行。
一般情况下,Activity和Service在同一个包名内,并且没有设定属性android:process=":remote",两者在同一个进程中. 因为一个进程只有一个UI线程, ...