使用Crawler框架搭建自己的爬虫框架MyCrawler
自己写一个爬虫框架的目的:
- 完美架构
- 在实际的数据采集编码过程中,发现代码比较乱,抓取数据,存储数据的代码混杂在一起,为了构建比较完美的数据采集框架
- 敏捷开发
- 将数据采集进行标准流程化,每个标准流程都封装成组件,在实际开发过程中直接调用组件即可,只需编写核心的逻辑
- 代码生成
- 可直接生成大部分的代码,开发者只需补充核心逻辑
爬虫框架与Web框架的对比:
| 爬虫框架 | Web框架 | |
| 脚本类型 | 不区分客户端和服务端; 控制台程序,是独立的进程 | 区分服务端和客户端,且是服务端程序; 运行的容器是Web服务器 |
| 入口脚本 | 是爬虫脚本在运行的入口;例如:main.js | 使用唯一的入口脚本,是服务区接收Web请求的入口;例如index.php |
| 处理 | 已进程为核心 | 采用路由分发,控制器为中心的模式 |
| 数据存储 | 主要为数据插入存储 | 包括数据的增删改查 |
| 页面 | 从页面中采集数据 | 编写页面并使用数据渲染页面 |
| 中间件 | 过滤爬虫存储数据的职责链,通常指数据的除重去噪 | 过滤HTTP请求的职责链 |
爬虫框架MyCrawler的特性:
- 使用面向对象方法封装数据采集类
- 使用面向对象方法封装数据存储类
- 代码生成器
- 自动数据去重
UML中类关系详解
- 虚线箭头指向依赖
- 实线箭头指向关联
- 虚线三角指向接口
- 实线三角指向父类
- 空心菱形能分离而独立存在,是聚合
- 实心菱形精密关联不可分,是组合
MyCrawler爬虫框架类图
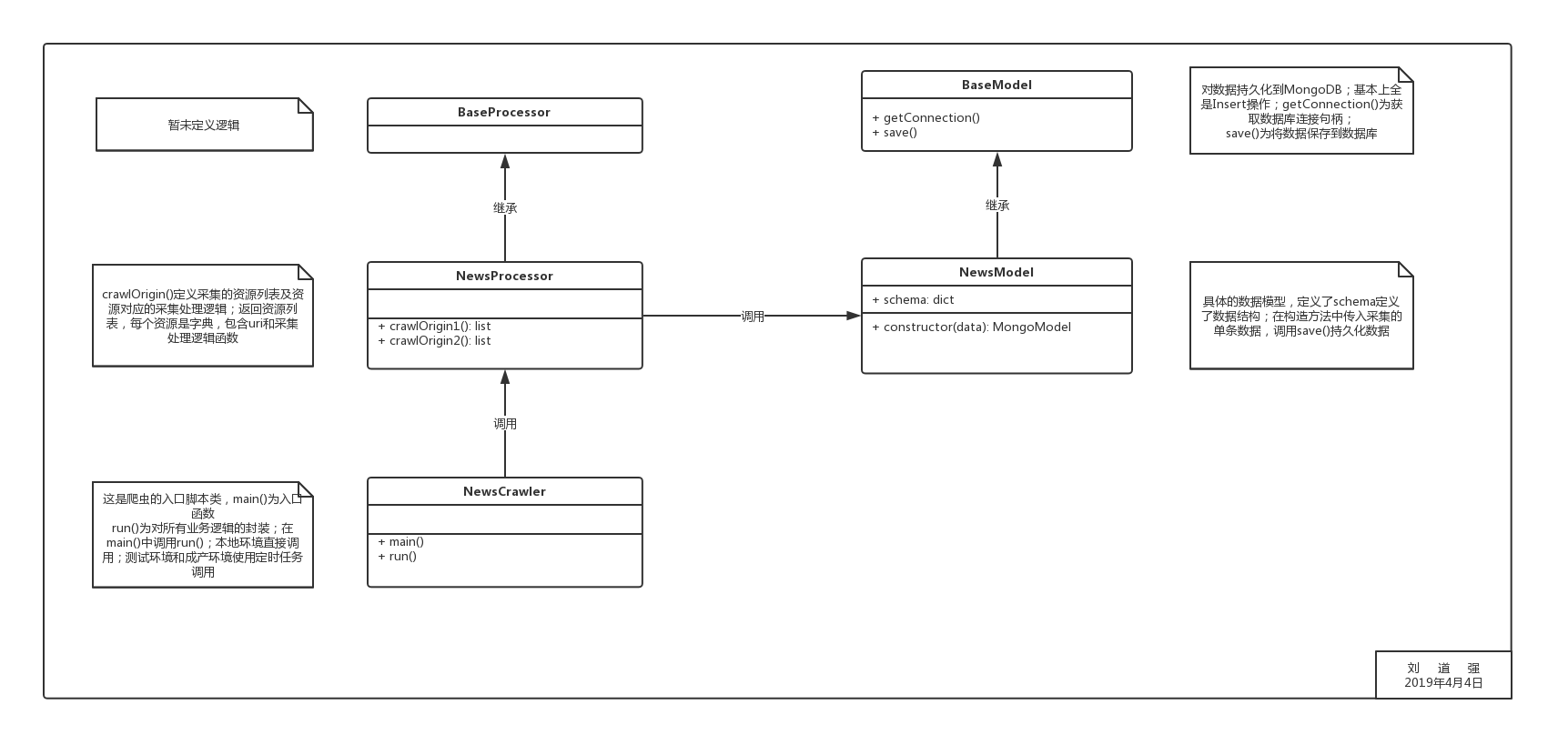
新建一个空项目,命名为MyCrawler
初始化package.json文件
npm init --yes
例如:
F:\project\MyCrawler>npm init --yes
Wrote to F:\project\MyCrawler\package.json:
{
"name": "MyCrawler",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
下载安装Crawler框架
npm install crawler
例如:
F:\project\MyCrawler>npm install crawler npm notice created a lockfile as package-lock.json. You should commit this file. npm WARN MyCrawler@ No description npm WARN MyCrawler@ No repository field. + crawler@ added packages from contributors and audited packages .699s found vulnerabilities ( low, moderate) run `npm audit fix` to fix them, or `npm audit` for details
注意:如果安装失败,则切换使用另一个网络重试,因为有可能是网络不好,或者网络无法达到目的主机
使用Crawler框架搭建自己的爬虫框架MyCrawler的更多相关文章
- android studio 框架搭建:加入注解框架Annotations
参考github上的demo,新建一个project后,会有一个位于app文件夹下的局部build.gradle文件和一个位于根目录project下的全局build.gradle文件,我们要修改的是局 ...
- JAVA 爬虫框架webmagic 初步使用Demo
一想到做爬虫大家第一个想到的语言一定是python,毕竟python比方便,而且最近也非常的火爆,但是python有一个全局锁的概念新能有瓶颈,所以用java还是比较牛逼的, webmagic 官网 ...
- webapi框架搭建系列博客
webapi框架搭建系列博客 webapi框架搭建-创建项目(一) webapi框架搭建-创建项目(二)-以iis为部署环境的配置 webapi框架搭建-创建项目(三)-webapi owin web ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- C# 爬虫框架实现 概述
目录: C# 爬虫框架实现 概述 C# 爬虫框架实现 流程_爬虫结构/原理 C# 爬虫框架实现 流程_各个类开发 C# 爬虫框架实现 流程_遇到的问题 C# 爬虫框架实现 后记 C#爬虫框架实现 源代 ...
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 五.如何做全站采集 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师 ...
- 怎么在32位windows系统上搭建爬虫框架scrapy?
禁止转载: 自学python,然后搭建爬虫框架scrapy.费了我一上午的心血.终于搭建成功,以防以后忘记搭建流程,特此撰写此贴,开写 ******************************** ...
- python网络爬虫(14)使用Scrapy搭建爬虫框架
目的意义 爬虫框架也许能简化工作量,提高效率等.scrapy是一款方便好用,拓展方便的框架. 本文将使用scrapy框架,示例爬取自己博客中的文章内容. 说明 学习和模仿来源:https://book ...
随机推荐
- 分析 js构造函数:对象方法 、类方法 、原型方法
构造函数方法有对象方法.类方法.原型方法,这些方法在什么时候可以调用,什么时候不能调用,为什么? function Func(name){ this.name=name; this.ff=functi ...
- 泥瓦匠想做一个与众不同的技术"匠"
点击蓝字,关注泥瓦匠 本文阅读大约 3 分钟.感谢阅读 喝了最后一口百事可乐,想到它的 slogan:新一代的选择.新一代的选择,每个人选择不同,人生道路历程也不同.就像我刚毕业的时候,毕业选择不一样 ...
- Scrum Mastery:有效利用组织的5个步骤
组织以什么样的方式能最大限度的发挥Scrum的优势?组织在哪些方面阻碍了个人的发展?Scrum是一种能使业务变得敏捷的框架.而组织恰恰需要变得敏捷.只是,组织本身有时候并没有足够的能力来帮助Scrum ...
- (二)surging 微服务框架使用系列之surging 的准备工作consul安装
suging 的注册中心支持consul跟zookeeper.因为consul跟zookeeper的配置都差不多,所以只是consul的配置 consul下载地址:https://www.consul ...
- 🕵️ 如何绕过 BKY 对 script 的屏蔽
Conmajia January 20, 2019 警告 这是试验,警告个屁,请不要多多尝试用它做多余的事. 果不其然,这篇文章立刻被移出主页了,我就说嘛,BKY 哪儿会那么包容和坦然呢? 原文 do ...
- JS里charCodeAt()和fromCharCode()方法拓展应用:加密与解密
JS实现客户端的网页加密解密技术,可用作选择性隐蔽展示.当然客户端的加密安全度是不能与服务器相提并论,肯定不能用于密码这类内容的加密,但对于一般级别的内容用作展示已经够了. JS加密与解密的解决方案有 ...
- InnoSetup 脚本打包及管理员权限设置
InnoSetup使用教程:InnoSetup打包安装 脚本详细 1. 定义变量 #define MyAppName "TranslationTool" #define MyApp ...
- Flutter项目之app升级方案
题接上篇的文章的项目,还是那个空货管理app.本篇文章用于讲解基于Flutter的app项目的升级方案. 在我接触Flutter之前,做过一个比较失败的基于DCloud的HTML5+技术的app,做过 ...
- WinForm 国际化的一些问题
国际化 我之前 WinForm 国际化都是凑一些代码搞起(请看文后 Reference). 最近发现还有个官方国际化方法: 首先设置 Form 的 Localizable 属性为 true 选择 Fo ...
- socket通信如何处理每次包长度不定问题
说起来,这是一个漫长的问题: 客户端和服务器通信的结构是:包头+数据长度+数据 客户端请求服务器发送200包数据.包头=request:长度=4(一个int),数据=200: 服务器在收到客户端的请求 ...