使用Crawler框架搭建自己的爬虫框架MyCrawler
自己写一个爬虫框架的目的:
- 完美架构
- 在实际的数据采集编码过程中,发现代码比较乱,抓取数据,存储数据的代码混杂在一起,为了构建比较完美的数据采集框架
- 敏捷开发
- 将数据采集进行标准流程化,每个标准流程都封装成组件,在实际开发过程中直接调用组件即可,只需编写核心的逻辑
- 代码生成
- 可直接生成大部分的代码,开发者只需补充核心逻辑
爬虫框架与Web框架的对比:
| 爬虫框架 | Web框架 | |
| 脚本类型 | 不区分客户端和服务端; 控制台程序,是独立的进程 | 区分服务端和客户端,且是服务端程序; 运行的容器是Web服务器 |
| 入口脚本 | 是爬虫脚本在运行的入口;例如:main.js | 使用唯一的入口脚本,是服务区接收Web请求的入口;例如index.php |
| 处理 | 已进程为核心 | 采用路由分发,控制器为中心的模式 |
| 数据存储 | 主要为数据插入存储 | 包括数据的增删改查 |
| 页面 | 从页面中采集数据 | 编写页面并使用数据渲染页面 |
| 中间件 | 过滤爬虫存储数据的职责链,通常指数据的除重去噪 | 过滤HTTP请求的职责链 |
爬虫框架MyCrawler的特性:
- 使用面向对象方法封装数据采集类
- 使用面向对象方法封装数据存储类
- 代码生成器
- 自动数据去重
UML中类关系详解
- 虚线箭头指向依赖
- 实线箭头指向关联
- 虚线三角指向接口
- 实线三角指向父类
- 空心菱形能分离而独立存在,是聚合
- 实心菱形精密关联不可分,是组合
MyCrawler爬虫框架类图
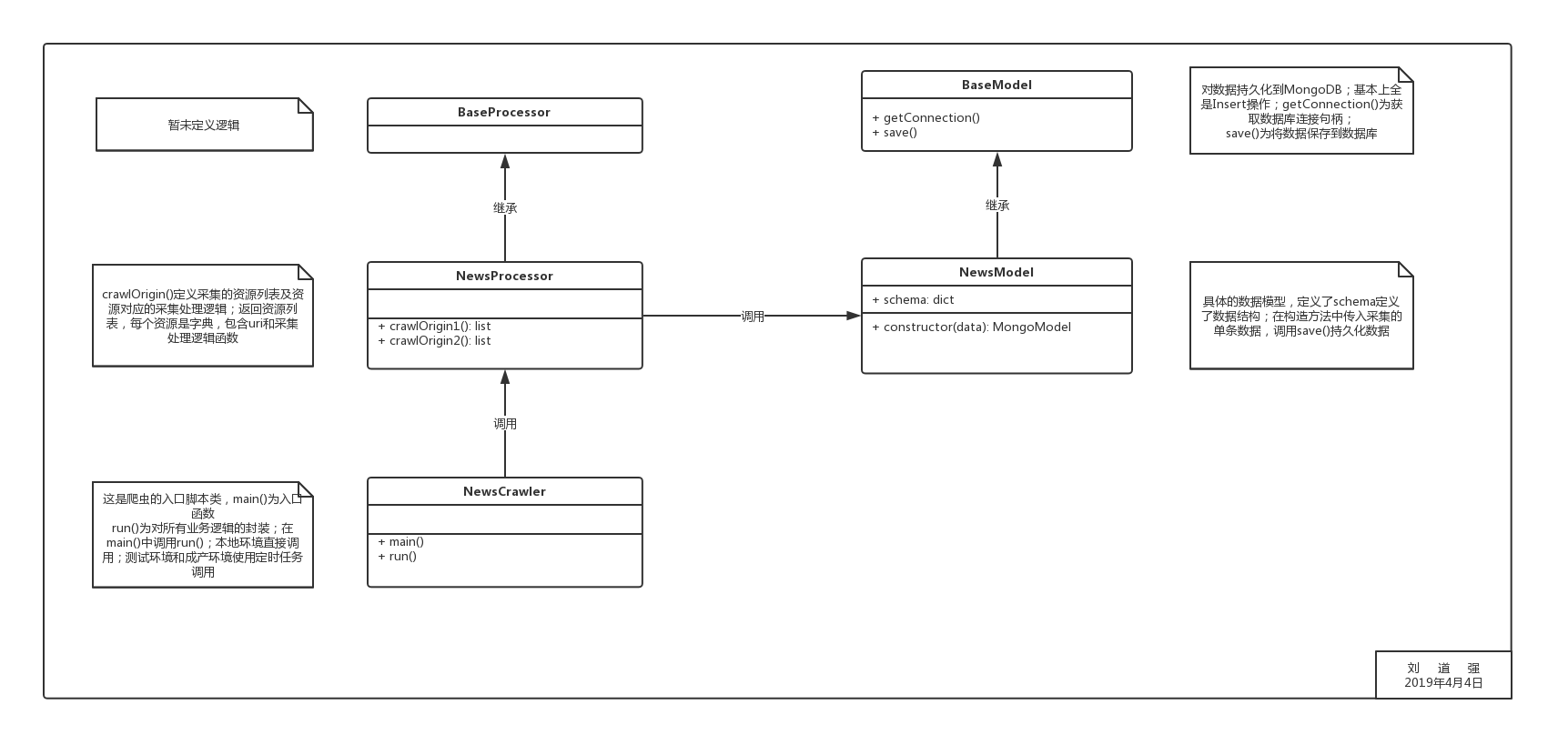
新建一个空项目,命名为MyCrawler
初始化package.json文件
npm init --yes
例如:
F:\project\MyCrawler>npm init --yes
Wrote to F:\project\MyCrawler\package.json:
{
"name": "MyCrawler",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
下载安装Crawler框架
npm install crawler
例如:
F:\project\MyCrawler>npm install crawler npm notice created a lockfile as package-lock.json. You should commit this file. npm WARN MyCrawler@ No description npm WARN MyCrawler@ No repository field. + crawler@ added packages from contributors and audited packages .699s found vulnerabilities ( low, moderate) run `npm audit fix` to fix them, or `npm audit` for details
注意:如果安装失败,则切换使用另一个网络重试,因为有可能是网络不好,或者网络无法达到目的主机
使用Crawler框架搭建自己的爬虫框架MyCrawler的更多相关文章
- android studio 框架搭建:加入注解框架Annotations
参考github上的demo,新建一个project后,会有一个位于app文件夹下的局部build.gradle文件和一个位于根目录project下的全局build.gradle文件,我们要修改的是局 ...
- JAVA 爬虫框架webmagic 初步使用Demo
一想到做爬虫大家第一个想到的语言一定是python,毕竟python比方便,而且最近也非常的火爆,但是python有一个全局锁的概念新能有瓶颈,所以用java还是比较牛逼的, webmagic 官网 ...
- webapi框架搭建系列博客
webapi框架搭建系列博客 webapi框架搭建-创建项目(一) webapi框架搭建-创建项目(二)-以iis为部署环境的配置 webapi框架搭建-创建项目(三)-webapi owin web ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- C# 爬虫框架实现 概述
目录: C# 爬虫框架实现 概述 C# 爬虫框架实现 流程_爬虫结构/原理 C# 爬虫框架实现 流程_各个类开发 C# 爬虫框架实现 流程_遇到的问题 C# 爬虫框架实现 后记 C#爬虫框架实现 源代 ...
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 五.如何做全站采集 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师 ...
- 怎么在32位windows系统上搭建爬虫框架scrapy?
禁止转载: 自学python,然后搭建爬虫框架scrapy.费了我一上午的心血.终于搭建成功,以防以后忘记搭建流程,特此撰写此贴,开写 ******************************** ...
- python网络爬虫(14)使用Scrapy搭建爬虫框架
目的意义 爬虫框架也许能简化工作量,提高效率等.scrapy是一款方便好用,拓展方便的框架. 本文将使用scrapy框架,示例爬取自己博客中的文章内容. 说明 学习和模仿来源:https://book ...
随机推荐
- 学习ASP.NET Core Razor 编程系列十二——在页面中增加校验
学习ASP.NET Core Razor 编程系列目录 学习ASP.NET Core Razor 编程系列一 学习ASP.NET Core Razor 编程系列二——添加一个实体 学习ASP.NET ...
- 手撸GitLab CI(阉割版)
上一集我们说到如何从零开始搭建一个Vue-cli 3.0的项目,而这一集我们将说到如何手写一份阉割版的CI脚本. 首先说一下GitLab部署到服务器的操作,一般有两种,一种是规范化分离的,包含runn ...
- EXPLAIN 命令详解
在工作中,我们用于捕捉性能问题最常用的就是打开慢查询,定位执行效率差的SQL,那么当我们定位到一个SQL以后还不算完事,我们还需要知道该SQL的执行计划,比如是全表扫描,还是索引扫描,这些都需要通过E ...
- C++项目中采用CLR的方式调用C#编写的dll
1.注意事项:在编写C#DLL类库时,最好不要出现相同的命名空间,否则在C++中调用可能会出现编译错误.2.将C#的源码生成的“dll”文件复制到C++项目中的Debug目录下3.将C++项目属性设置 ...
- 使用vue-cli快速搭建vue项目
直接上干货...... 步骤: 1.安装node.js:(下载地址:https://nodejs.org/en/download/)安装完成以后,在命令窗口输入node -v 查看node版本. ...
- 未能加载文件或程序集“System.Web.Mvc, Version=5.2.4.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35”或它的某一个依赖项
楼主创建项目的时候选择的是5.2.4的版本,但是后来改成了5.0.0于是出现了这个错误,解决的方法倒也简单 将View文件夹下 web.config文件中 以下两处 版本改成当前版本就行了
- mssql sqlserver 分组排序函数row_number、rank、dense_rank用法简介及说明
在实际的项目开发中,我们经常使用分组函数,对组内数据进行群组后,然后进行组内排序:如:1:取出一个客户一段时间内,最大订单数的行记录2: 取出一个客户一段时间内,最后一次销售记录的行记录——————— ...
- 【夯实shell基础】shell基础面面观
本文地址 点击关注微信公众号 wenyuqinghuai 分享提纲: 1. shell中的函数 2. shell中的数组 3. shell中的变量 4. shell中的运算符 5. Linux的一些命 ...
- redis 初步认识二(c#调用redis)
前置:服务器安装redis 1.引用redis 2.使用redis(c#) 一 引用redis (nuget 搜索:CSRedisCore) 二 使用redis(c#) using System ...
- [认证授权] 1.OAuth2授权
1 OAuth2解决什么问题的? 举个栗子先.小明在QQ空间积攒了多年的照片,想挑选一些照片来打印出来.然后小明在找到一家提供在线打印并且包邮的网站(我们叫它PP吧(Print Photo缩写